本篇文章为大家展示了如何用R语言抓取网页图片,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
今天要爬取的是一个多图的知乎网页,是一个外拍的帖子,里面介绍了巨多各种外拍技巧,很实用的干货。
library(rvest)
library(downloader)
library(stringr)
library(dplyr)
https://www.zhihu.com/question/19647535
打开网页之后,在帖子内容里随便定位一张图片,然后单击右键——检查元素(Ctrl+Shift+I),页面右侧弹出的网页结构会自动定位到该图片的地址,你会看到该图片在html结构中的名称标签:——(img);地址标签——(src)。
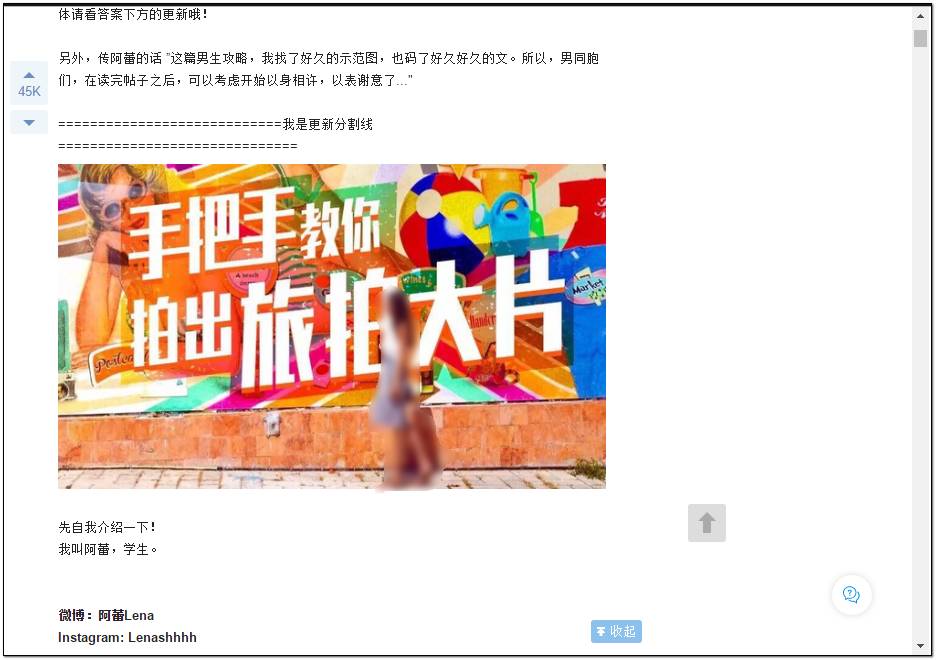
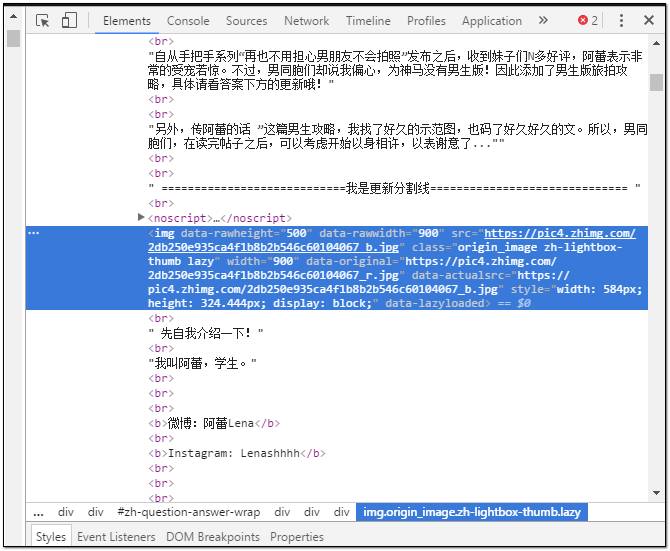
我们想要获取的就是该图片的地址信息,你可以尝试着使用downlond函数下载单张图片。
url<-"https://pic4.zhimg.com/2db250e935ca4f1b8b2b546c60104067_b.jpg"
download(url,"D:/R/Image/picturebbb.jpg", mode = "wb")
这样就完成了自动下载过程,但是图片地址仍然是肉眼观察获取的,显然不够智能,我们想要的效果是通过一个函数自动的批量获取图片地址并下载图片。
那么下一步的目标就很明确了,如何通过函数批评获取图片地址,然后将包含图片地址的字符串向量传递给下载函数。
以上就需要我们大致了解html的构建了,知道所有的图片存放在html构建的那一部分里面,通过网址定位到图片存放区间,通过获取图片存放的区间,批量获取图片地址,然后传递给下载函数执行。
太深入的我也不太了解,但是html的常用结构无非是head/body/,head中存放网页标题和导航栏的信息(我是小白,不要吐槽以上每一句话的准确性哈~),而我们要抓取的目标图片肯定是存放在body中啦。
继续打开body部分,你会被一大摞的<div> </div>结构晃瞎眼,不要担心,我已经瞎了好几回了~—~
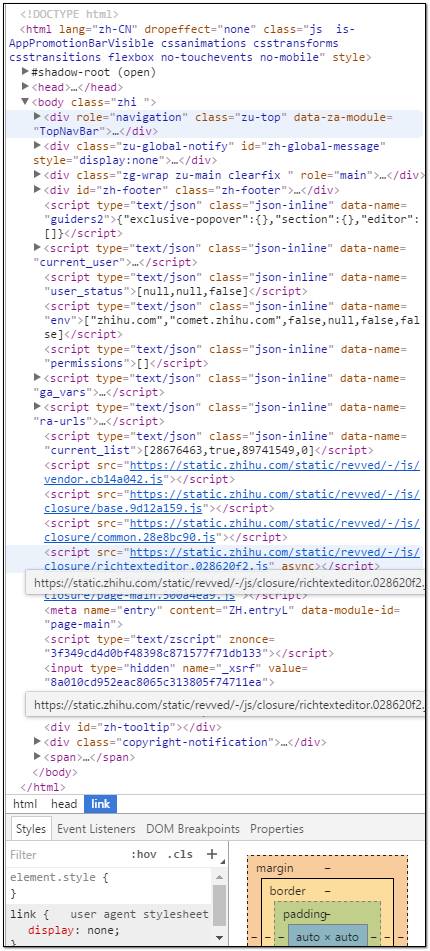
div是html里面的分区结构,每一个分区都是以<div>开头,以</div>结尾。(html中几乎所有结构都是这种方式,仔细观察一下其他形式的结构就会发现)。
当然div分区有N多个,而且div结构本身可以层层嵌套。对于太复杂的网页,在你发现图片存放的div分区之前估计会先被div语句晃瞎眼。
那怎么办呢,还记得在本文开始部分,说的那个手动定位吗,依靠浏览器的审查元素功能,我们可以先定位要下载的第一张图片,右键——检查,找到该图片的div分支结构。
我们需要获取的信息是该图片的div分区名称信息(就是div结构中的class属性或者ID属性)
class和ID获取其中一个就行,如果是class属性,则地址书写规则是:div.class,如果是ID则规则是div#ID。
如果class和ID中字符较长,且单词间存在空格,空格以英文.号替换。
以上图片的div分支结构定位信息就可以写作div.zm-editable-content.clearfix
其实这里有一个简便方法,如果你不确定自己定位的区间是否正确的话,可以查看右下角的html路径(可以自动根据你的鼠标所在的html位置定位父级路径)。
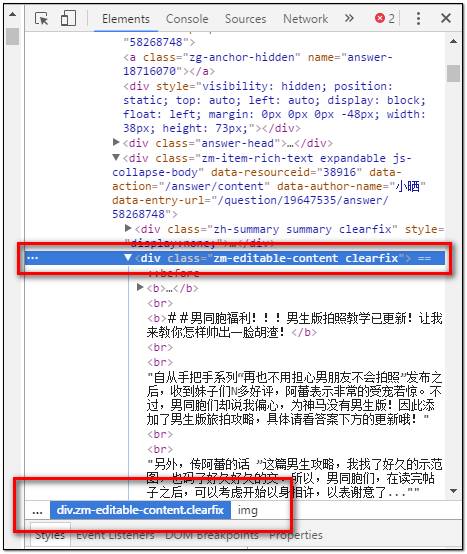
接下来使用read_html函数获取网页并一步一步的定位图片地址。
url <- 'https://www.zhihu.com/question/19647535'
link<- read_html(url)%>% html_nodes("div.zm-editable-content.clearfix")%>%html_nodes("img")%>%html_attr("src")
我们需要获取的是图片所在div分支结构中的img标签下的src内容(也就是图片地址),那么如果不想抓取一大堆不相干的图片的话,就必须明确目标图片的存放位置,以上代码过程从url(该知乎帖子页面网址)定位到目标图片所在的div分支结构,然后定位到分支结构中的img(图片标签)中的src信息(也就是目标图片网址)。
运行以上两句代码并以head函数预览link向量的前几行,查看获取的图片地址是否正确。
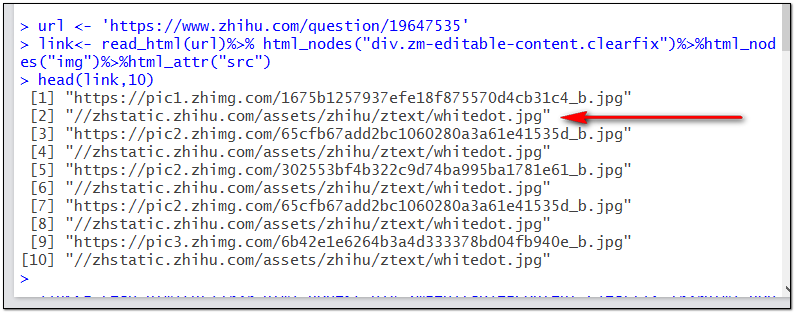
很遗憾,我们获取的存放图片地址信息的字符串向量中,每隔一行都有一个无效网址,如果不清除掉这些无效网址或者筛选出那些完整的网址的时候,download函数执行到无效网址会终端,下载过程就会失败。
这里需要使用stringr包来进行条件筛选。
pat = "https"
link<-grep(pat, link,value=TRUE)
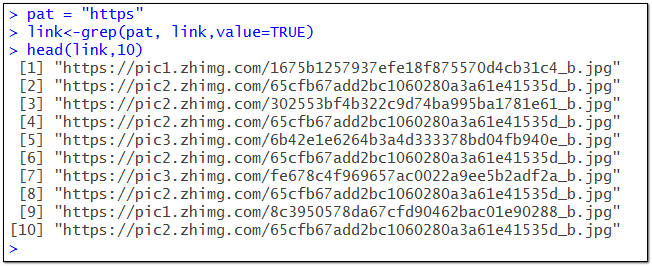
匹配之后,只保留了完整的图片网址,这就是我们最终要的结果。现在可以使用一个for循环来自动执行图片批量下载任务。
dir.create("D:R/Case/") #新建文件夹
for(i in 1:length(link))
{
download(link[i],paste("D:/R/Case/picture",i,".jpg",sep = ""), mode = "wb")
} #一个循环批处理所有下载任务
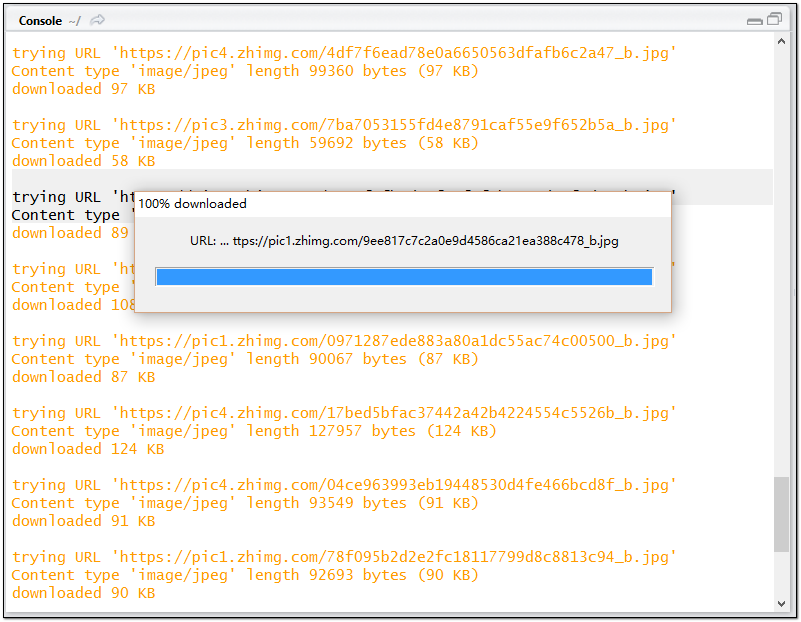
至此,爬虫的代码部分完成,剩余的时间……嘿嘿,泡一杯咖啡,看会儿美剧,静静地等待软件完成自动下载过程吧(速度视图片原始大小和宽带速度而定)。
结束之后,到D盘的Case文件夹下浏览下刚才下载的成果:
394张图片全部顺序标号,乖乖的躺在文件夹里了(当然里面还包含各种表情包图片,这个,我真的不太会分辨,暂时木办法)。
下面就今天分享内容总结以下几点:
用R抓取图片的核心要点是获取html结构中存放图片的div分区中的img标签内的src内容(也就是图片地址,有时候可能需要使用read_src内的地址)。
图片的目标div分区结构的选取至关重要(如果你不指定div分区地址、只使用img标签下的src定位的话,很有可能抓取了全网页的图片网址,各种特殊符号和表情包、菜单栏和logo图表都会被抓取)
如果不太确定自己定位的div结构是否正确,可以借助鼠标选取+html路径信息来定位;
有时候有些网页的图片不是集中存放在单个div分区结构中,而是每张图片都是单独的div结构,这时候如果还是定位的最底层div分区位置的话,那么你可能只能获取单张图片地址。这时候适当的定位父级div分支结构名称(酌情观察,看那个父级结构范围可以涵盖所有目标图片的子div分支结构)
还有一种情况,就是有些公开的图片网站图片存储结构非常规则,分页存储,单页中单个div结构下的一组图片名称是按照数字顺序编号的:
比如:
http://################.1.jpg
http://################.2.jpg
http://################.3.jpg
http://################.4.jpg
………………………………………
http://################.n.jpg
如果你碰到这种存储方式的图片网页,那你真的太幸运了,不用再傻乎乎的去从网页地址的html结构中一步一步的去定位图片地址了,直接使用for循环遍历完所有的图片网址,然后直接传递给download函数批量下载就OK了。
for(n in 1:50)
#自己定位到网页最后一个子页面,查看下最大的图片编号是多少。
{
link<- c(paste("http://################/",n,".jpg",sep=""),link)
}
for(i in 1:length(link))
{
download(link[i],paste("D:/R/Case/picture",i,".jpg",sep = ""), mode = "wb")
}
这样完全避免了从网址中曾曾定位获取图片地址的麻烦,直接就可以获取全网页所有目标图片的地址,效率就更高了。
上述内容就是如何用R语言抓取网页图片,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





