在给大家讲解Hive之前,我们要先熟悉下Hadoop的一些概念。
Hadoop可以分为一下几个部分
HDFS hadoop的文件系统,用于数据存储
MapReduce 用于数据处理
Yarn 用于资源管理
那Hadoop 中的MapReduce程序一般处理输入都是一些标准化的日志,假设我们有如下的日志文件。
姓名 科目 成绩
张三 语文 90
李四 语文 80
王五 语文 88
张三 数学 99
李四 数学 98
王五 数学 90
我们需要对这些数据进行处理,如获取成绩最高者、统计平均分等。
那么没做一次处理我们就需要像写八股文似的进行编写MapReduce程序:
1、编写Mapper
2、编写Reducer
3、编写main
4、在main中定义job
5、设置job的输入、输出以及参数
6、执行job
这样就需要我们对MapReduce编程十分的熟悉,并且这种方式比较费时费力。同时,在一般的公司中,
对这种有固定格式的数据进行处理我们一般都交由专门的DB进行处理,但是DB又对MapReduce的编程不了解,
让他们编写MapReduce程序来处理数据就不太现实,那有没有一种或者一个工具,
能让他们使用类似sql的方式来清洗数据。
答案当然是有的,那就是我们的Hive。Hive是一个在hadoop基础上来处理结构化数据的数据仓库基础工具。这里说它是一个工具,它主要的功能就是方便我们处理数据,但是数据的存储等还是在HDFS上。
Hive是架构在Hadoop之上,可以提供类似SQL语言的查询语句进行简化大数据的处理以及清晰,
方便DB进行数据处理。
Hive开始是有Facebook开发,后由Apache软件基金会开发,并将其Apache下的一个顶级项目。
Hive为一个开源项目,它用在好多不同的公司。
1、它不像关系型数据库只能处理少量的数据,hive由于架构在Hadoop之上,本身就赋予了其处理大数据的能力。
2、它提供一种类似SQL的查询语言,叫HQL或者HiveQL。
3、由于本身就是在MapReduce上进行的二次扩展,因此hive就具有了良好的可扩展型,
如果出现一个hive提供不了的处理,我们可以通过编写mapreduce程序,将其封装成hive的一个函数。HIve只是一个工具,他将HQL转换成MapReduce程序运行在Yarn上面,进行处理HDFS上存储的数据,
这样就可以让我们对于简单的数据处理,只是编写一下HQL就可以了,不用在编写MapReduce程序。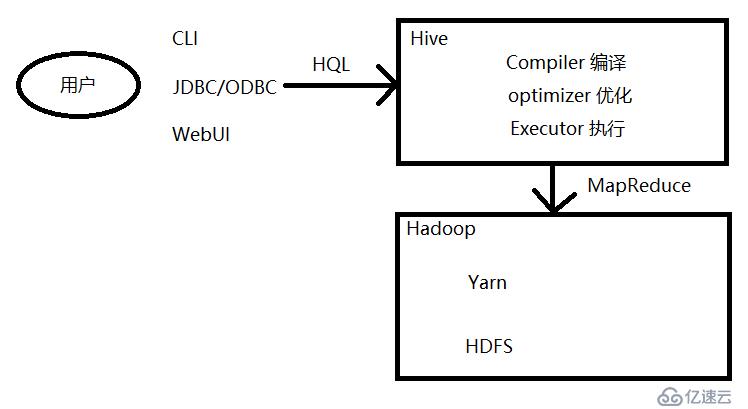
用户在使用Hive的过程中,通过CLI、JDBC/ODBC、WebUI等方式,提供HQL语句到hive中,hive通过编译、优化、执行,将经过优化的HQL语句进行转换成MapReduce程序放到yarn上运行。
针对开始提出的查询成绩最高的那一行,我们只需要写如下的HQL就可以了:
select * from table order by sorce desc limit 0,1
到此,整个hive的介绍就个大家讲解完成了,在下一篇中,我们讲会讲解hive的安装
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





