这篇文章给大家分享的是有关大数据中朴素贝叶斯法的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM),本案例采用朴素贝叶斯模型。朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,本节对此算法作了重点分析。
一、 垃圾消息识别算法-朴素贝叶斯
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier, NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数较少,对缺失数据不太敏感,算法也比较简单。
理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
这个在250多年前发明的算法,在信息领域内有着无与伦比的地位。贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。朴素贝叶斯算法(Naive Bayesian) 是其中应用最为广泛的分类算法之一。
1.实现基础机器学习贝叶斯分类的核心
分类是将一个未知样本分到几个预先已知类的过程。数据分类问题的解决是一个两步过程:第一步,建立一个模型,描述预先的数据集或概念集。通过分析由属性描述的样本(或实例、对象等)来构造模型。假定每一个样本都有一个预先定义的类,由一个被称为类标签的属性确定。为建立模型而被分析的数据元组形成训练数据集,该步也称作有指导的学习。
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型和朴素贝叶斯模型。决策树模型通过构造树来解决分类问题。首先利用训练数据集来构造一棵决策树,一旦树建立起来,它就可为未知样本产生一个分类。
在分类问题中使用决策树模型有很多的优点,决策树便于使用,而且高效;根据决策树可以很容易地构造出规则,而规则通常易于解释和理解;决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小;决策树模型的另外一大优点就是可以对有许多属性的数据集构造决策树。决策树模型也有一些缺点,比如处理缺失数据时的困难,过度拟合问题的出现,以及忽略数据集中属性之间的相关性等。
解决这个问题的方法一般是建立一个属性模型,对于不相互独立的属性,把他们单独处理。例如中文文本分类识别的时候,我们可以建立一个字典来处理一些词组。如果发现特定的问题中存在特殊的模式属性,那么就单独处理。
这样做也符合贝叶斯概率原理,因为我们把一个词组看作一个单独的模式,例如英文文本处理一些长度不等的单词,也都作为单独独立的模式进行处理,这是自然语言与其他分类识别问题的不同点。
实际计算先验概率时候,因为这些模式都是作为概率被程序计算,而不是自然语言被人来理解,所以结果是一样的。
在属性个数比较多或者属性之间相关性较大时,朴素贝叶斯模型的分类效率比不上决策树模型。但这点有待验证,因为具体的问题不同,算法得出的结果不同,同一个算法对于同一个问题,只要模式发生变化,也存在不同的识别性能。这点在很多国外论文中已经得到公认,算法对于属性的识别情况决定于很多因素,例如训练样本和测试样本的比例影响算法的性能。
决策树对于文本分类识别,要看具体情况。在属性相关性较小时,朴素贝叶斯模型的性能相对较好。属性相关性较大的时候,决策树算法性能较好。
2.朴素贝叶斯分类的表达式描述
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。如上公式也可变形为:P(B|A) = P(A|B)*P(B) / P(A)。
通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯法则就是这种关系的陈述。贝叶斯法则是关于随机事件A和B的条件概率和边缘概率的。其中P(A|B)是在B发生的情况下A发生的可能性。
在贝叶斯法则中,每个名词都有约定俗成的名称:
Pr(A)是A的先验概率或边缘概率。之所以称为“先验”是因为它不考虑任何B方面的因素。
Pr(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
Pr(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
Pr(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
按这些术语,Bayes法则可表述为:
后验概率 = (似然度 * 先验概率)/标准化常量,也就是说,后验概率与先验概率和似然度的乘积成正比。
另外,比例Pr(B|A)/Pr(B)也有时被称作标准似然度(standardised likelihood),Bayes法则可表述为:
后验概率 = 标准似然度 * 先验概率。
二、 进行分布式贝叶斯分类学习时的全局计数器
在单机环境中完成基于简单贝叶斯分类算法的机器学习案例时,只需要完整加载学习数据后套用贝叶斯表达式针对每个单词计算统计比率信息即可,因为所需的各种参数均可以在同一个数据文件集中直接汇总统计获取,但是当该业务迁移到MapReduce分布式环境中后,情况发生了本质的变化。从图14.9贝叶斯分类表达式在垃圾消息识别中的使用方式:

可以看出,在进行数据学习统计时需要计算几个主要比例参数:可以看出,在进行数据学习统计时需要计算几个主要比例参数:
所有消息中包含某个特定单词的比率;
消息为垃圾消息的比率;
消息为垃圾消息并且垃圾消息中存在特定单词的比例。
因此,需要对所有的学习数据汇总,至少需要明确学习数据中消息的总数,学习数据中垃圾消息的数量,学习数据中有效消息的数量等数据,由于MapReduce任务的数据输入来源来自于HDFS,而HDFS会将超大的数据文件自动切分成大小相等的块存放到不同的数据节点,同时MapRedece任务也将满足“数据在哪个节点,计算任务就在哪个节点启动”的基本原则,因此整个学习数据的分析统计任务会并行在不同的Java虚拟机甚至不同的任务计算节点中,使用传统的共享变量方式来解决这个汇总统计问题就成了不可能完成的任务。
要想使用MapReduce完成计数器的功能可以有以下几种选择:
(1)使用MapReduce内置的Counter组件,MapReduce的Counter计数器会自动记录一些通用的统计信息,如本次MapReduce总共处理的数据分片数量等,开发人员也可以自定义不同类型的Counter计数器并在Map或Reduce任务中设置/累加/计数器的值,但是MapReduce内置的Counter计数器工具有一个明显的缺陷,它并不支持Map任务中累加计数器的值后在Reduce中直接获取。
也就是说,在Reduce任务中第一次获取相关计数器的值永远都为0,尽管在整个任务结束后,MapReduce会将对应计数器在Map和Reduce两个任务过程中分别设置的值进行最终的累加操作,由于在本案例中需要在Reduce任务中获取有效/垃圾消息的总数量以计算比率信息,而这些数量需要在Map任务中统计,因此MapReduce内置的Counter计数器并不是适合本案例的应用环境。
(2)Hadoop生态中的特殊组件Zookeeper对这类跨越节点的统一计数器提供了API支持,但是如果仅仅是因为需要设置少量几个以数字形式存在的计数器就额外部署一套Zookeeper集群显然开销太大,因此这种解决方法也不适用于当前案例。
(3)自行实现简单的统一计数器。统一计数器的实现比较简单,仅需在单独的节点中定义数字变量,在需要设置、累加或获取计数器时通过都通过网络访问这个节点中的这些数字变量。在普通环境中,实现这样一个计数器服务相对较为繁琐,因为需要大量的网络数据交换操作,但是在实现了自定义的RPC调用组件之后,基于网络的数据设置和获取操作就显得异常简单,就类似于在本机上完成一次普通Java方法一样方便,因此可以按照以下的结构来完成计数器服务的实现:
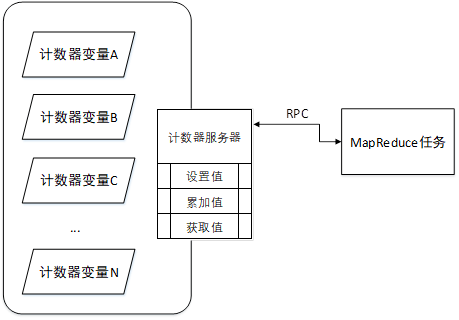
注意:由于多个数据处理节点会并发的向计数器服务发起设值请求,因此需要注意计数器变量的安全性,在最为简单的设计中,使计数器服务的设置值、累加值、获取值方法保持同步即可。
三、数据清洗分析结果存储
MapReduce是典型的非实时数据处理引擎,这就意味着不能将其作为需要实时反馈的场景。所以MapReduce任务只能在后台完成复杂数据的处理操作,供终端实时运算提供支撑的中间结果,而且由于HDFS文件系统的Metadata检索服务和数据网络传输都需要大量的IO开销,如果中间结果集的量级并不需要分布式的文件存储支持而又使用HDFS存储中间结果,反倒会对最终的服务效率带来消极影响。因此在完成好数据的统一清洗分析后,中间结果一般都选择以下的几种保存策略:
如果清洗后的结果是量级较小的规则性数据,则可以将其直接存放到Redis之类的Key-Value高速缓存体系中;
如果清洗后的结果集比较大,那么可以在Reduce任务中将其存放到传统的RDBMS中,供业务系统使用SQL语句完成实时查询;
如果清洗后的结果仍然是海量数据,则可以将其存放到HBase之类的分布式数据库中以提供高效的大数据实施查询。
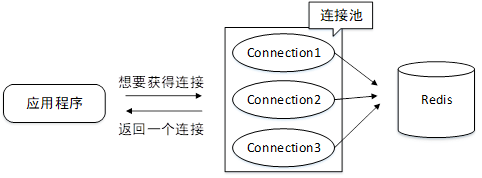
本项目采用Redis缓存数据,并使用了Redis连接池。和RDBMS一样,Redis也可以通过连接池方式提高数据访问效率和吞吐量,其原理如下:
感谢各位的阅读!关于“大数据中朴素贝叶斯法的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





