这篇文章给大家介绍Scrapy爬取知乎中怎么模拟登录,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
从今天开始更新关于爬取知乎的一系列文章,最近一直在优化代码,奈何代理IP有用的都是要钱的,所以已经不知道怎么优化了,发出来大家也参考参考,顺便提点意见。
知乎对于爬虫还是很友好的。所以其实也挺好弄得。
这是知乎刚进来的页面必须要登录。但是有时候是需要验证码而有时候不需要。所以这也需要做一个判断。
我们的最终目标是构建 POST 请求所需的 Headers 和 Form-Data 这两个对象即可。
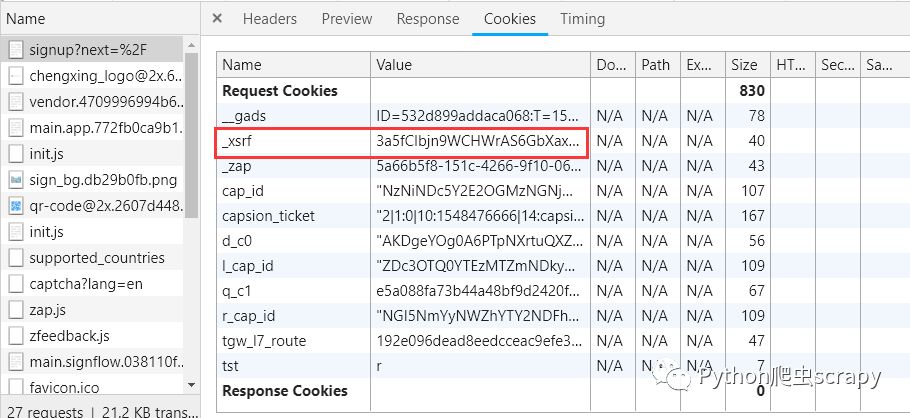
继续看Requests Headers信息,和登录页面的 GET 请求对比发现,这个 POST 的头部多了三个身份验证字段,经测试x-xsrftoken是必需的。
x-xsrftoken则是防 Xsrf 跨站的 Token 认证,访问首页时从Response Headers的Set-Cookie字段中可以找到。
具体的form-data: 可以参考知乎专栏:https://zhuanlan.zhihu.com/p/34073256
我的代码里没有实现点击倒立汉字的功能,有兴趣的可以去尝试。
def start_requests(self):
# 进入登录页面,回调函数start_login()
yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',headers=self.headers,callback=self.start_login, meta={'cookiejar': 1},) # meta={'cookiejar':1}
这是直接去get它的验证码,URL后面加参数lang=en,他请求到的就会只有英文验证码,不会出现倒立的汉字。
def start_login(self,response):
# 判断是否需要验证码
need_cap=json.loads(response.body)['show_captcha']
# re.search(r'true', resp.text)
print(need_cap)
if need_cap:
print('需要验证码')
yield scrapy.Request('https://www.zhihu.com/api/v3/oauth/captcha?lang=en',headers=self.headers,callback=self.capture,method='PUT', meta={'cookiejar': response.meta['cookiejar']})
else:
print('不需要验证码')
post_url = 'https://www.zhihu.com/api/v3/oauth/sign_in'
post_data ={
'client_id': self.client_id,
'grant_type': self.grant_type,
'timestamp': self.timestamp,
'source': self.source,
'signature': self.get_signnature(self.grant_type, self.client_id, self.source, self.timestamp),
'username': '+861777777',
'password': '123456',
'captcha': '',
# 改为'cn'是倒立汉字验证码
'lang': 'en',
'ref_source': 'other_',
'utm_source': ''}
yield scrapy.FormRequest(url=post_url, formdata=post_data, headers=self.headers, meta={'cookiejar': response.meta['cookiejar']},)
这个函数有点小问题就是每次其实都会请求到验证码,所以有时候不需要验证码也还是要输入,要改进的话需要用正则去匹配响应的TRUE。但是感觉也没啥的,因为基本只需要登录一次,保存cookies就可以了。
def capture(self,response):
try:
img = json.loads(response.body)['img_base64']
except ValueError:
print('获取img_base64的值失败!')
else:
img = img.encode('utf8')
img_data = base64.b64decode(img)
with open('zhihu.gif', 'wb') as f:
f.write(img_data)
f.close()
captcha = input('请输入验证码:')
post_data = {
'client_id': self.client_id,
'grant_type': self.grant_type,
'timestamp': self.timestamp,
'source': self.source,
'signature': self.get_signnature(self.grant_type, self.client_id, self.source, self.timestamp),
'username': '+861777777777',
'password': '123456',
'captcha': captcha,
'lang': 'en',
'ref_source': 'other_',
'utm_source': '',
'_xsrf': '0sQhRIVITLlEX8kQWA09VOqsPlSqRJQT'
}
yield scrapy.FormRequest(
url='https://www.zhihu.com/signin',
formdata=post_data,
callback=self.after_login,
headers=self.headers,
meta={'cookiejar': response.meta['cookiejar']},
)COOKIES_ENABLED = True
在setting.py中修改这个。意思就是使用自己定义的cookie。
def after_login(self, response):
if response.status == 200:
print("登录成功")
"""
登陆完成后从第一个用户开始爬数据 """
return [scrapy.Request(
self.start_url,
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_people,
errback=self.parse_err,
)]
else:
print("登录失败")登录成功去请求下一个方法,登录失败可以打印响应的内容或者重新输入,这一部分我没具体写。
关于Scrapy爬取知乎中怎么模拟登录就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





