这篇文章将为大家详细讲解有关如何分析MySQL中的REDO AHI latch锁,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
正文
问: 我的系统里面有大事务,怎么辨别其中可能会出现的问题?
在MYSQL中有一个共识点,就是不建议有较复杂的整体性的事务一次性处理,建议是分开处理,降低一个大事务的里面的关联性,让他变成多个事务来处理。当在MYSQL 中出现了超大事务对系统是不好,但如何解释清楚,这就是一个问题。
1 Checkpoint ,众所周知如果 dirty page 到达一个值触发的比率会进行脏页的刷新,当然checkpoint 本身也有四种模式对应的方式来刷新数据到磁盘。
一个事务完整的一个阶段如下
创建阶段:事务创建一条日志;
日志刷盘:日志写入到磁盘上的日志文件;
数据刷盘:日志对应的脏页数据写入到磁盘上的数据文件;
写CKP:日志被当作Checkpoint写入日志文件;
其中会有几个点需要注意,
1 日志空间的 7/8的位置,如果日志写到这个位置会开始异步的进行checkpoint ,但不阻塞事务
2 日志的 15/16的位置,如果触发到这个点,会停止一些当前事务,开始刷盘
3 达到 31/32 的位置,开始做last checkpoint
4 达到日志空间的大小,停止一些事务,做last checkpoint
所以就会存在 当大事务一次性写入的数量较大,并持续性当达到 7/8 和 15/16之间的位置,整体系统就会处于I/O繁忙刷磁盘的情况,当到达15/16 整体系统就不在接受操作了。
所以我们就必须要监控到底日志占用的情况,使用下面的方式监控
select count/1000000 from innodb_metrics where name like '%innodb_check%';

查看checkpoint 占用的整体的百分比。
问:当前数据库的innodb的log 写入的情况如何,有么有等待的状态,存在不存在瓶颈?
这里指的是redo log 的写入有没有瓶颈,我们可以监控 Innodb_os_log_pending_writes 参数是否有增长的泰式,如果持续的增长,则说明以上日志的写入有性能瓶颈。 而通过Innodb_os_log_written参数可以获得相关的日志写入的字节数。来进行判断当前的日志写入整体的情况。
问:当前MYSQL 系统的latch 锁如何,是否存在瓶颈,怎么改善?
首先latch 是一个内存锁,主要的作用是,保护共享资源支持并发,本身这两个事情就是矛盾的,资源要独享,还要支持并发,自然就要有锁来保证。
(注:以上锁并非直接指数据库的行锁,页锁,表锁的概念),相关理论请参考mysql latch 锁,这里不展开。
对一下的参数进行定期的记录并比较,可以获得系统中在检查时间段中,是否有存在系统latch 争用厉害的情况,除了查看当下SQL语句执行的情况,还可以根据其他的情况,来调整mysql instance 的数量,来缓解。
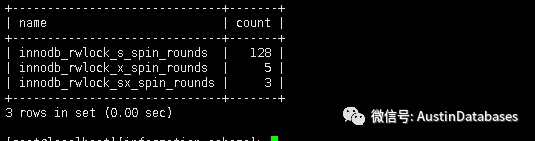
select name,count from INNODB_METRICS where name in ('innodb_rwlock_s_spin_rounds','innodb_rwlock_x_spin_rounds','innodb_rwlock_sx_spin_rounds');
问:自适应哈希索引工作的情况如何?都是MYSQL 自己进行,如何监控?
简单说一下HASH ,其实这样的方法也可以自己设计到业务表中,来达到某些目的和加速查询,MYSQL 这边提供的自适应HASH 。
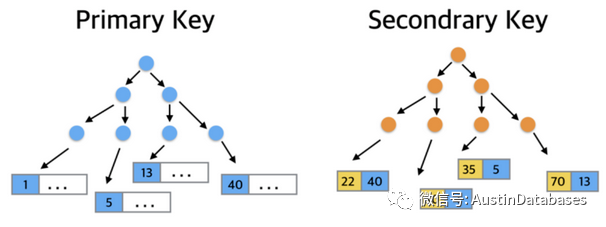
对于数据库的查询,通过主键和索引查询是常态,MYSQL 的 AHI,针对超过3次以上的对应查询 = ,>= <= ,in 等操作会进行记录,并进行数据页与 自动生成的HASH 值的对应。通过这样的方式来加速数据的查询,尤其对于层高已经在 4层的索引,这样的方法会大大加速数据的查询。
那怎么监控AHI 索引的使用情况
select * from INNODB_METRICS where name like 'adaptive_hash_searches'\G
关于如何分析MySQL中的REDO AHI latch锁就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





