XPathжҖҺд№Ҳз”Ё
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іXPathжҖҺд№Ҳз”ЁпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
1пјҢXPathзҡ„дҪҝз”Ё
еңЁдҪҝз”ЁеүҚпјҢйңҖиҰҒе®үиЈ…lxmlеә“гҖӮ
е®үиЈ…д»Јз Ғпјҡpip3 install lxml
1.1XPathзҡ„常用规еҲҷ:
/ иЎЁзӨәйҖүеҸ–зӣҙжҺҘеӯҗиҠӮзӮ№
// иЎЁзӨәйҖүеҸ–жүҖжңүеӯҗеӯҷиҠӮзӮ№
. йҖүеҸ–еҪ“еүҚиҠӮзӮ№
.. йҖүеҸ–еҪ“еүҚз»“зӮ№зҡ„зҲ¶иҠӮзӮ№
@ йҖүеҸ–еұһжҖ§
зңӢе®ҢиҝҷдәӣпјҹдҪ жҳҜдёҚжҳҜиҝҳжҳҜдёҖи„ёжҮөйҖјпјҹдёӢйқўжҲ‘们жқҘе®һйҷ…иҝҗз”ЁдёҖдёӢгҖӮ
1.2е®һдҫӢеј•з”Ё
еҰӮеӣҫпјҡ
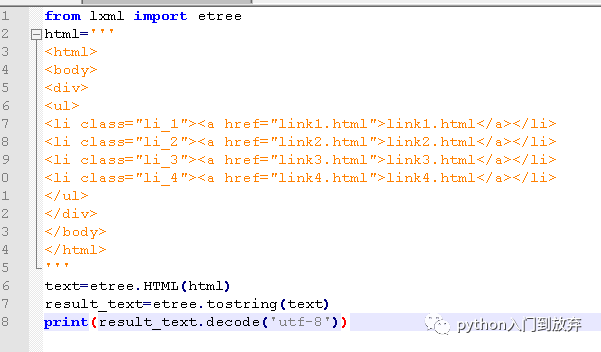
еҜје…ҘetreeжЁЎеқ—
etree.HTML()жҳҜжһ„йҖ дёҖдёӘXPathеҜ№иұЎ
etree.tostring()жҳҜеҜ№д»Јз ҒиҝӣиЎҢдҝ®жӯЈпјҢеҰӮжһңжңүзјәеӨұзҡ„йғЁеҲҶпјҢдјҡиҮӘеҠЁдҝ®еӨҚ
ж–№жі•жҜ”иҫғз®ҖеҚ•пјҢе°ұдёҚжҲӘеҸ–ж•ҲжһңеӣҫдәҶгҖӮ
еҰӮжһңжҲ‘们зӣёеҜ№жң¬ең°зҡ„ж–Ү件иҝӣиЎҢи§ЈжһҗжҖҺд№ҲеҠһпјҹжҲ‘们еҸҜд»Ҙиҝҷж ·еҶҷ

etree.parse()第дёҖдёӘеҸӮж•°дёәhtmlзҡ„и·Ҝеҫ„пјҢ第дәҢпјҲetree.HTMLParser()пјүе’ҢдёҠйқўetree.HTML()зҡ„жҖ§иҙЁжҳҜдёҖж ·зҡ„пјҢдёәдәҶж–№дҫҝпјҢжҺҘдёӢйҮҢжҲ‘дҪҝз”ЁеҜ№жң¬ең°ж–Ү件иҝӣиЎҢи§ЈжһҗгҖӮ
htmlж–Үжң¬еҰӮдёӢпјҡ
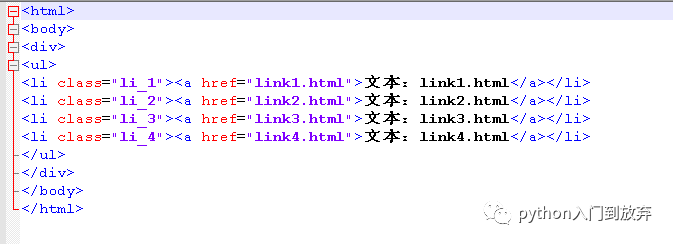
1.3иҺ·еҸ–жүҖжңүзҡ„иҠӮзӮ№

з»“жһңпјҡ

ејҖеӨҙз”Ё//иЎЁзӨәйҖүеҸ–жүҖжңүз¬ҰеҗҲзҡ„иҠӮзӮ№пјҢ*иЎЁзӨәиҺ·еҸ–жүҖжңүзҡ„иҠӮзӮ№пјҢ
дёҠйқўдёӨеҸҘиҜқдёҖзңӢиҝҷдёҚжҳҜдёҖдёӘж„ҸжҖқеҗ—пјҹдјҡдёҚжҮӮпјҒ
жҲ‘们еҸҜд»ҘеҲҶдёәдёӨжӯҘзҗҶи§Ј:
第дёҖжӯҘ//жҳҜйҖүеҸ–жүҖжңүз¬ҰеҗҲиҰҒжұӮзҡ„иҠӮзӮ№пјҢжІЎжңүжҢҮжҳҺжҳҜд»Җд№ҲиҰҒжұӮпјҒпјҢдёҚзҹҘйҒ“дҪ иҰҒиҺ·еҸ–д»Җд№Ҳ.
第дәҢжӯҘ*иЎЁзӨәжүҖжңүиҠӮзӮ№пјҢжүҖд»ҘжүҚдјҡиҺ·еҸ–жүҖжңүиҠӮзӮ№гҖӮиҝҷж ·зҗҶи§Јиө·жқҘеә”иҜҘдјҡеҫҲе®№жҳ“дәҶеҗ§гҖӮ
жіЁж„Ҹпјҡиҝ”еӣһзҡ„жҳҜдёҖдёӘеҲ—иЎЁ
1.4иҺ·еҸ–жҢҮе®ҡзҡ„иҠӮзӮ№
иҝҳжҳҜдёҠйқўзҡ„htmlж–Үжң¬пјҢеҰӮжһңжҲ‘们жғіиҺ·еҸ–liиҠӮзӮ№жҖҺд№ҲеҠһпјҹ
еҸӘйңҖиҰҒе°Ҷresult_text=html.xpath('//*')дҝ®ж”№жҲҗresult_text=html.xpath('//li')
еҰӮжһңжғіиҺ·еҸ–aиҠӮзӮ№пјҢе°ұдҝ®ж”№жҲҗ//a,д№ҹеҸҜд»ҘеҶҷжҲҗ//li//aпјҢжҲ–иҖ…//ul//aиҺ·еҸ–//li/a
йғҪжҳҜеҸҜд»ҘиҺ·еҸ–еҲ°дҪҶжҳҜеҰӮжһң//ul/aжҳҜиҺ·еҸ–дёҚеҲ°зҡ„еӣ дёә/иЎЁзӨәзҡ„жҳҜзӣҙжҺҘеӯҗиҠӮзӮ№
жіЁж„Ҹпјҡиҝ”еӣһзҡ„йғҪжҳҜиҠӮзӮ№пјҢ并дёҚжҳҜж–Үжң¬дҝЎжҒҜгҖӮ
еҚіпјҡ

иҝҷз§ҚеҪўејҸгҖӮ
1.4еұһжҖ§еҢ№й…Қ
еҰӮжһңжҲ‘们жғіиҰҒaж Үзӯҫзҡ„hrefеұһжҖ§пјҢжҲ‘们еҸҜд»Ҙдҝ®ж”№жҲҗ//a/@href
иҝ”еӣһз»“жһңпјҡ

иҝ”еӣһзҡ„д№ҹжҳҜдёҖдёӘеҲ—иЎЁ
еҰӮжһңжҲ‘们жғіиҰҒеҢ№й…Қclassдёәli_1зҡ„liпјҢеҸҜд»Ҙдҝ®ж”№жҲҗ//li[@class="li_1"]еҚіеҸҜ
1.5зҲ¶иҠӮзӮ№еҢ№й…Қ
жҲ‘们жқҘиҺ·еҸ–link2.htmlзҡ„aиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№зҡ„classеұһжҖ§пјҢжҲ‘们жҳҜйңҖиҰҒдҝ®ж”№жҲҗ//a[@href="link2.html"]/../@classпјҢиҝҷйҮҢзҡ„..иЎЁзӨәеҜ»жүҫзҲ¶иҠӮзӮ№пјҢиҝ”еӣһзҡ„дҫқ然жҳҜдёҖдёӘеҲ—иЎЁгҖӮ
1.6иҺ·еҸ–ж–Үжң¬
жҲ‘们жқҘиҺ·еҸ–classдёәli_3зҡ„liдёӢaзҡ„ж–Үжң¬пјҢеҸҜд»ҘеҶҷжҲҗ//li[@class="li_3"]/a/text()еҚіеҸҜ
1.7contains()еҮҪж•°
жҜ”еҰӮе…¶дёӯжңүдёҖдёӘliдёәпјҡ
<li class="li li_last" id="caidan"></li>
жӯӨж—¶пјҡliе…·жңүдёӨдёӘclassеҗҚпјҢжҲ‘们еҰӮжһңиҝҷж ·еҶҷ//li[@class="li"]жҳҜиҺ·еҸ–дёҚеҲ°иҠӮзӮ№зҡ„
йӮЈд№ҲжҲ‘们еҸҜд»Ҙиҝҷж ·еҶҷиҺ·еҸ–еҲ°иҠӮзӮ№//li[contains(@class,"li")]гҖӮ
1.8еӨҡеұһжҖ§иҺ·еҸ–
<li class="li li_last" id="caidan"></li>пјҢеҗҢж ·жҳҜиҝҷдёӘliжҲ‘们йңҖиҰҒиҺ·еҸ–classеҗҚдёәliеҗҢж—¶idдёәcaidanзҡ„liпјҢеҸҜд»Ҙиҝҷж ·еҶҷ//li[contains(@class,"li") and @id="caidan"]
иҺ·еҸ–classеҗҚдёәliжҲ–иҖ…idдёәcaidanзҡ„liе°ұз”ЁorгҖӮ
1.9пјҢlast(),position()еҮҪж•°
дёҠйқўзҡ„htmlжңүеҫҲеӨҡliпјҢеҰӮжһңжҲ‘еҸӘжғіиҺ·еҸ–第дёҖдёӘеҸҜд»Ҙиҝҷж ·пјҡ
//li[1],еҗҢзҗҶ第дәҢдёӘж”№жҲҗ2е°ұеҸҜд»ҘдәҶпјҢеҰӮжһңжғіиҺ·еҸ–жңҖеҗҺдёҖдёӘпјҡ//li[last()]
еҰӮжһңжғіиҺ·еҸ–еүҚдёӨдёӘпјҡ//li[position()<3]
2,Beautiful Soupзҡ„дҪҝз”Ё
еҗҢж ·зҡ„еңЁдҪҝз”ЁеүҚжҲ‘们д№ҹиҰҒе®үиЈ…Beautiful Soup
жІЎжңүе®үиЈ…зҡ„иҜ·иҮӘиЎҢе®үиЈ…гҖӮ
йҰ–е…ҲеҜје…ҘжЁЎеқ—пјҡfrom bs4 import BeautifulSoup
иҝҷж¬ЎжҲ‘们зӣҙжҺҘз”ЁдёҖдёӘзҪ‘з«ҷжқҘиҜ•иҜ•пјҢжҲ‘йҖүжӢ©зҡ„жҳҜзҢ«зңјзҪ‘пјҢ
дҪ еҸҜд»ҘйҖүжӢ©е…¶д»–зҪ‘з«ҷе“ҰгҖӮ
иҺ·еҸ–зҪ‘йЎөйғЁеҲҶпјҢдёҠиҠӮжңүж•ҷпјҢй“ҫжҺҘпјҡpython第дәҢеӨ§зҘһеҷЁrequests
еҰӮеӣҫпјҡ
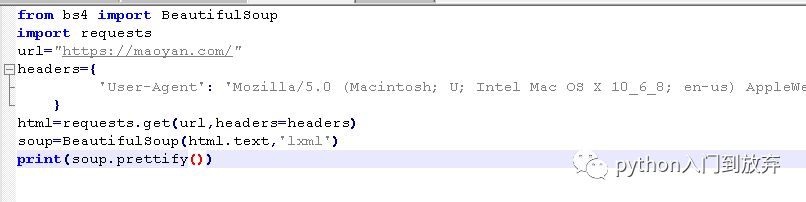
2.1еҲқе§ӢеҢ–
BeautifulSoup()第дёҖдёӘеҸӮж•°дёәиҺ·еҸ–зҡ„зҪ‘йЎөеҶ…е®№пјҢ第дәҢдёӘеҸӮж•°дёәlxmlпјҢдёәд»Җд№ҲжҳҜlxmlпјҹеӣ дёәBeautiful SoupеңЁи§Јжһҗж—¶дҫқиө–и§ЈжһҗеҷЁпјҢpythonиҮӘеёҰзҡ„и§ЈжһҗеҷЁпјҢе®№й”ҷиғҪеҠӣе·®пјҢжҜ”иҫғж…ўпјҢжүҖд»ҘжҲ‘们дҪҝ用第дёүж–№и§ЈжһҗеҷЁlxmlпјҢ
prettify()жҳҜе°ҶиҺ·еҸ–зҡ„еҶ…е®№д»Ҙзј©иҝӣзҡ„ж–№ејҸиҫ“еҮәпјҢзңӢиө·жқҘеҫҲиҲ’жңҚ
еҰӮеӣҫпјҡ
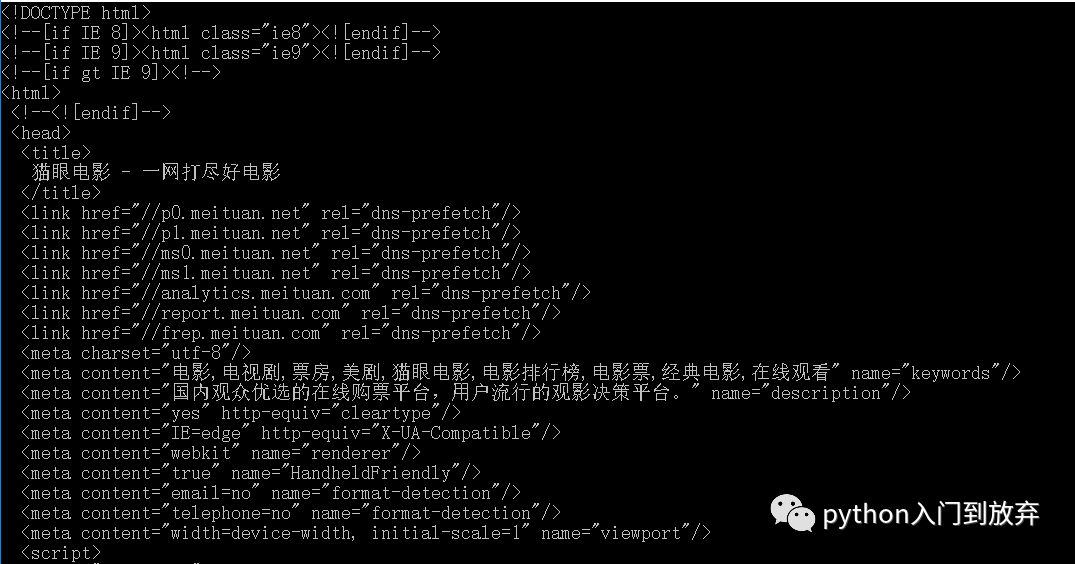
зңӢиө·жқҘиҲ’жңҚеӨҡдәҶгҖӮ
2.2иҺ·еҸ–еҖј
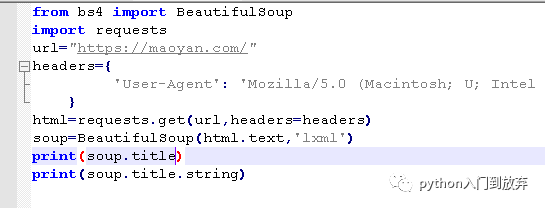
жҲ‘们жқҘиҺ·еҸ–дёҖдёӢtitleдҝЎжҒҜпјҢжҲ‘们жҳҜйңҖиҰҒиҝҷж ·гҖӮ
з»“жһңпјҡ

жҲ‘们еҸҜд»ҘзңӢеҲ°titleиҺ·еҸ–зҡ„жҳҜtitleиҠӮзӮ№зҡ„жүҖжңүдҝЎжҒҜпјҢиҖҢеҠ дёӘstringе°ұеҸҳжҲҗдәҶtitleйҮҢзҡ„ж–Үжң¬еҶ…е®№пјҢиҝҷж ·жҳҜдёҚжҳҜд№ҹжҳҜеҫҲз®ҖеҚ•пјҹ
2.21иҺ·еҸ–еұһжҖ§еҖј
жҜ”еҰӮпјҢжҲ‘们жғіиҰҒиҺ·еҸ–imgзҡ„srcеұһжҖ§пјҢжҲ‘们еҸӘйңҖиҰҒпјҢsoup.img['src']е°ұеҸҜд»ҘиҺ·еҸ–еҲ°пјҢsoup.img.arrts['src']д№ҹеҸҜд»ҘиҺ·еҸ–еҲ°гҖӮ
еҰӮжһңжғіиҺ·еҸ–еҲ°жүҖжңүзҡ„еұһжҖ§е°ұиҝҷж ·еҶҷпјҡsoup.img.arrtsеҚіеҸҜ
еҰӮеӣҫжүҖзӨәпјҡ

жіЁж„ҸпјҡжүҖжңүзҡ„еұһжҖ§иҝ”еӣһзҡ„еҪўејҸжҳҜд»Ҙеӯ—е…ёзҡ„еҪўејҸиҝ”еӣһгҖӮ
2.3иҺ·еҸ–зӣҙжҺҘеӯҗиҠӮзӮ№е’ҢеӯҗеӯҷиҠӮзӮ№пјҢзҲ¶иҠӮзӮ№пјҢзҘ–е…ҲиҠӮзӮ№пјҢе…„ејҹиҠӮзӮ№
иҺ·еҸ–зӣҙжҺҘеӯҗиҠӮзӮ№пјҡcontentsпјҢдҫӢеҰӮжҲ‘жғіиҺ·еҸ–pж Үзӯҫзҡ„зӣҙжҺҘеӯҗиҠӮзӮ№пјҡsoup.p.contentsеҚіеҸҜ
иҺ·еҸ–еӯҗеӯҷиҠӮзӮ№пјҡdescendants,дҫӢеҰӮжҲ‘жғіиҺ·еҸ–pж Үзӯҫзҡ„еӯҗеӯҷиҠӮзӮ№пјҡsoup.p.descendantsеҚіеҸҜ
иҺ·еҸ–зҲ¶иҠӮзӮ№пјҡparentеұһжҖ§пјҢдҫӢеҰӮжҲ‘жғіиҺ·еҸ–pж Үзӯҫзҡ„зҲ¶иҠӮзӮ№пјҡsoup.p.parentеҚіеҸҜ
иҺ·еҸ–зҘ–е…ҲиҠӮзӮ№пјҡparentsеұһжҖ§пјҢдҫӢеҰӮжҲ‘жғіиҺ·еҸ–pж Үзӯҫзҡ„зҘ–е…ҲиҠӮзӮ№пјҡsoup.p.parentsеҚіеҸҜ
иҺ·еҸ–е…„ејҹиҠӮзӮ№пјҡnext_sibling,previous_sibling,next_siblings,previous_siblingsеҲҶеҲ«дёәдёӢдёҖдёӘе…„ејҹиҠӮзӮ№пјҢдёҠдёҖдёӘе…„ејҹиҠӮзӮ№пјҢдёҠйқўжүҖжңүзҡ„е…„ејҹиҠӮзӮ№пјҢдёӢйқўжүҖжңүзҡ„е…„ејҹиҠӮзӮ№гҖӮ
2.4иҺ·еҸ–ж–Үжң¬еұһжҖ§
stringдёәиҺ·еҸ–ж–Үжң¬
attrsдёәиҺ·еҸ–еұһжҖ§
2.5ж–№жі•йҖүжӢ©еҷЁ
find_all()иҝ”еӣһзҡ„дёҖдёӘеҲ—иЎЁпјҢеҢ№й…ҚжүҖжңүз¬ҰеҗҲиҰҒжұӮзҡ„е…ғзҙ
еҰӮжһңжҲ‘们жғіиҰҒиҺ·еҸ–ulеҸҜд»Ҙиҝҷж ·еҶҷпјҡsoup.find_all(name='ul')
еҰӮжһңжҲ‘们жғіиҰҒиҺ·еҸ–idдёәid1еұһжҖ§еҸҜд»Ҙиҝҷж ·еҶҷпјҡsoup.find_all(arrts[id='id1'])
еҰӮжһңжҲ‘们жғіиҰҒиҺ·еҸ–classдёәclass1еұһжҖ§еҸҜд»Ҙиҝҷж ·еҶҷпјҡsoup.find_all(arrts[class_='class1'])
еӣ дёәclassжңүзү№ж®Ҡж„Ҹд№үпјҢжүҖд»ҘжҲ‘们иҺ·еҸ–classзҡ„ж—¶еҖҷд»·ж ј_еҚіеҸҜ
еҰӮжһңжҲ‘们жғіиҰҒиҺ·еҸ–ж–Үжң¬еҖјеҸҜд»Ҙиҝҷж ·еҶҷпјҡsoup.find_all(text=re.compile(''))
еҢ№й…ҚtextйңҖиҰҒз”ЁеҲ°жӯЈеҲҷпјҢеҢ№й…ҚдҪ жғіиҰҒзҡ„textеҖј
find()еҸӘиҝ”еӣһдёҖдёӘеҖјпјҢеҢ№й…ҚеҲ°з¬ҰеҗҲиҰҒжұӮзҡ„第дёҖдёӘеҖјгҖӮ
з”Ёжі•е’ҢдёҠйқўзҡ„ж–№жі•дёҖж ·
жіЁж„Ҹпјҡд»ҘдёҠиҜҙжңүзҡ„еұһжҖ§пјҢж–№жі•йғҪжҳҜйҖҡиҝҮжҲ‘е®һдҫӢзҡ„soupжқҘи°ғз”ЁпјҢsoupжҳҜжҲ‘зҡ„е‘ҪеҗҚпјҢдҪ еҸҜд»Ҙдҝ®ж”№е®ғпјҢеҗҢж—¶дҪ и°ғз”Ёе°ұиҰҒз”ЁдҪ зҡ„е‘ҪеҗҚдәҶ
2.6cssйҖүжӢ©еҷЁ
жҲ‘们еҰӮжһңз”ЁcssйҖүжӢ©еҷЁйңҖиҰҒи°ғз”Ёselect()ж–№жі•
жҜ”еҰӮжғіиҺ·еҸ–classеҗҚдёәclass1зҡ„иҠӮзӮ№пјҢжҲ‘们еҸҜд»Ҙиҝҷж ·еҶҷпјҡsoup.select('.class1')еҚіеҸҜпјҢе’Ңcssзҡ„иЎЁиҫҫж–№ејҸжҳҜдёҖж ·зҡ„пјҢдҪҶжҳҜд»–зҡ„cssйҖүжӢ©еҷЁеҠҹиғҪдёҚеӨҹејәеӨ§пјҢдёӢйқўжҲ‘们д»Ӣз»ҚдёҖдёӘй’ҲеҜ№cssзҡ„и§Јжһҗеә“гҖӮ
3пјҢpyqueryзҡ„дҪҝз”Ё
йҰ–е…ҲиҰҒе®үиЈ…pyquery
жІЎжңүе®үиЈ…зҡ„иҜ·иҮӘиЎҢе®үиЈ…гҖӮ
еҜје…ҘжЁЎеқ—пјҡfrom pyquery import PyQuery
йҰ–е…Ҳе’ҢдёҠйқўзҡ„дёҖж ·пјҢеҗҢж ·йңҖиҰҒеҲқе§ӢеҢ–пјҢиҺ·еҸ–еҜ№иұЎ
еҰӮдёӢпјҡ

з»“жһңпјҡ

иҝҷж ·е°ұиҺ·еҸ–еҲ°дәҶжүҖжңүзҡ„li
жӯӨеӨ–пјҡеҲқе§ӢеҢ–еҜ№иұЎж—¶пјҢеҸҜд»ҘеЎ«еҶҷж–Үжң¬пјҲдёҠйқўе°ұжҳҜпјүпјҢиҝҳеҸҜд»ҘеЎ«еҶҷurlпјҡPyQuery(url='https://maoyan.com/')
иҝҳеҸҜд»ҘеЎ«еҶҷжң¬ең°ж–Ү件пјҡPyQuery(filename=''),''дёӯеЎ«еҶҷжң¬ең°ж–Ү件зҡ„и·Ҝеҫ„
3.1cssйҖүжӢ©еҷЁзҡ„еҹәжң¬з”Ёжі•
еҰӮжһңжғійҖүеҸ–classеҗҚдёәclass1дёӢзҡ„liеҸҜд»Ҙиҝҷж ·еҶҷresult('.class li')е’Ңcssзҡ„йҖүжӢ©еҷЁеҶҷжі•жҳҜдёҖж ·зҡ„гҖӮ
3.2find()ж–№жі•пјҢеӯҗиҠӮзӮ№пјҢзҲ¶иҠӮзӮ№пјҢе…„ејҹиҠӮзӮ№
е’ҢдёҠйқўдёҚеҗҢиҝҷйҮҢзҡ„find()ж–№жі•жҳҜжҹҘжүҫжүҖжңүзҡ„еӯҗеӯҷиҠӮзӮ№пјҢ
жіЁж„Ҹпјҡиҫ“еҮәзҡ„жҳҜзҲ¶иҠӮзӮ№зҡ„жүҖжңүеҶ…е®№гҖӮ
е…„ејҹиҠӮзӮ№пјҡsiblis()ж–№жі•пјҢеҰӮжһңеҸӘжғіиҰҒе…„ејҹиҠӮзӮ№дёӯidдёәid1зҡ„еҸҜд»Ҙиҝҷж ·еҶҷпјҡparents('#id1')
3.3еҜ№дәҺиҺ·еҸ–зҡ„з»“жһңпјҢдёҚжғідёҠйқўиҝ”еӣһзҡ„жҳҜеҲ—иЎЁпјҢиҝҷйҮҢеҰӮжһңиҝ”еӣһеӨҡдёӘеҜ№иұЎйңҖиҰҒforеҫӘзҺҜйҒҚеҺҶ
3.4иҺ·еҸ–еұһжҖ§пјҢж–Үжң¬пјҢ
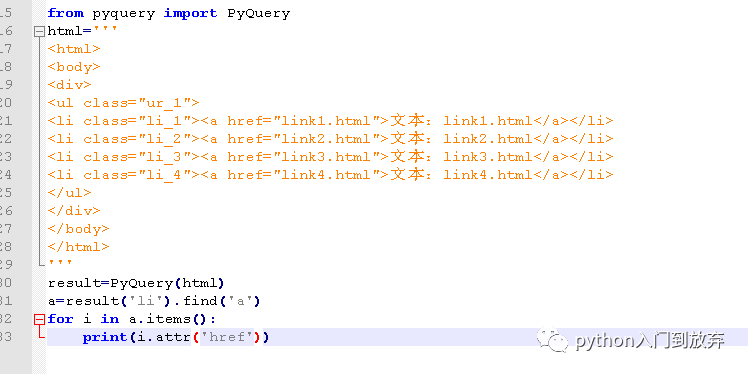
дҫӢеҰӮжҲ‘们жғіиҰҒиҺ·еҸ–liдёӢaзҡ„hrefеұһжҖ§пјҲattr()еҮҪж•°пјүпјҢз”ұдәҺжңүеӨҡдёӘз»“жһңпјҢжүҖд»ҘжҲ‘们иҝҷйҮҢйңҖиҰҒйҒҚеҺҶгҖӮ
еҰӮеӣҫпјҡ
з»“жһңпјҡ
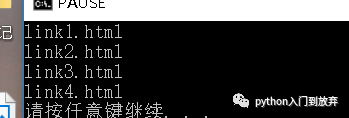
жіЁж„ҸпјҡеҰӮжһңдёҚйҒҚеҺҶпјҢеҸӘдјҡиҫ“еҮә第дёҖдёӘ
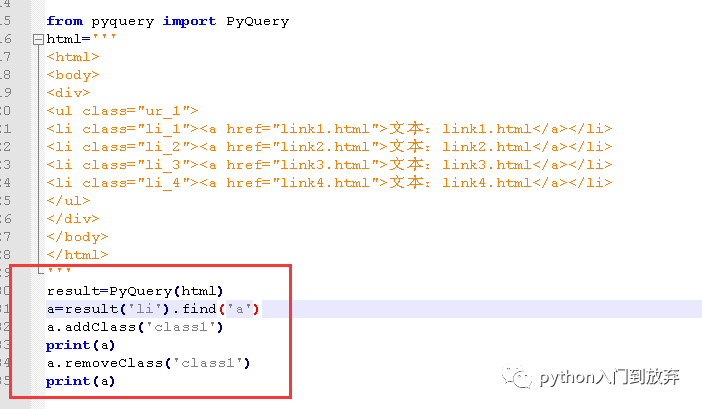
3.6еҜ№еұһжҖ§пјҢж–Үжң¬пјҢclassзҡ„еҲ йҷӨпјҢдҝ®ж”№
жҲ‘们жқҘе®һдҫӢдёҖдёӢпјҡ
з»“жһңпјҡ

еҗҢж—¶жҲ‘们иҝҳеҸҜд»Ҙж·»еҠ еұһжҖ§пјҢж–Үжң¬
ж·»еҠ еұһжҖ§пјҡattr('name','name1')
ж·»еҠ ж–Үжң¬пјҡtext('123123')
ж·»еҠ д»Јз Ғпјҡhtml('<span>12122</apan>')
жңүдәҶж·»еҠ пјҢе°ұжңүеҲ йҷӨremove()еҮҪж•°
е…ідәҺвҖңXPathжҖҺд№Ҳз”ЁвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





