这篇文章主要为大家展示了“java中LinkedHashMap的示例分析”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“java中LinkedHashMap的示例分析”这篇文章吧。
LinkedHashMap维护插入的顺序。
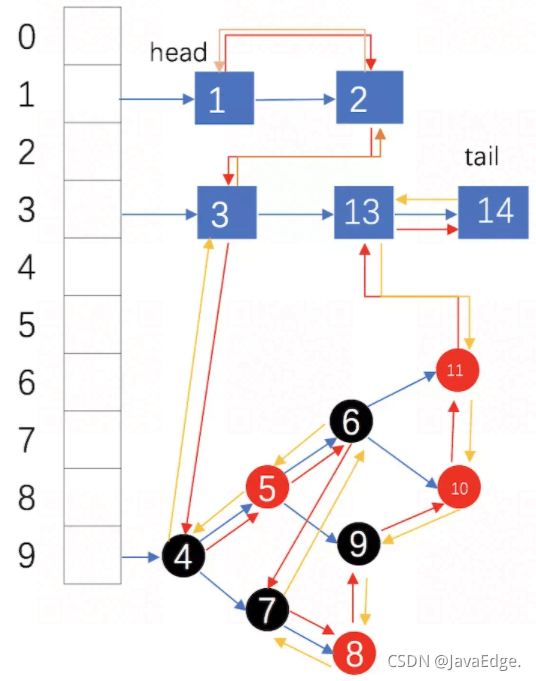
红黄箭头:元素添加顺序
蓝箭头:单链表各个元素的存储顺序
head:链表头部
tail:链表尾部
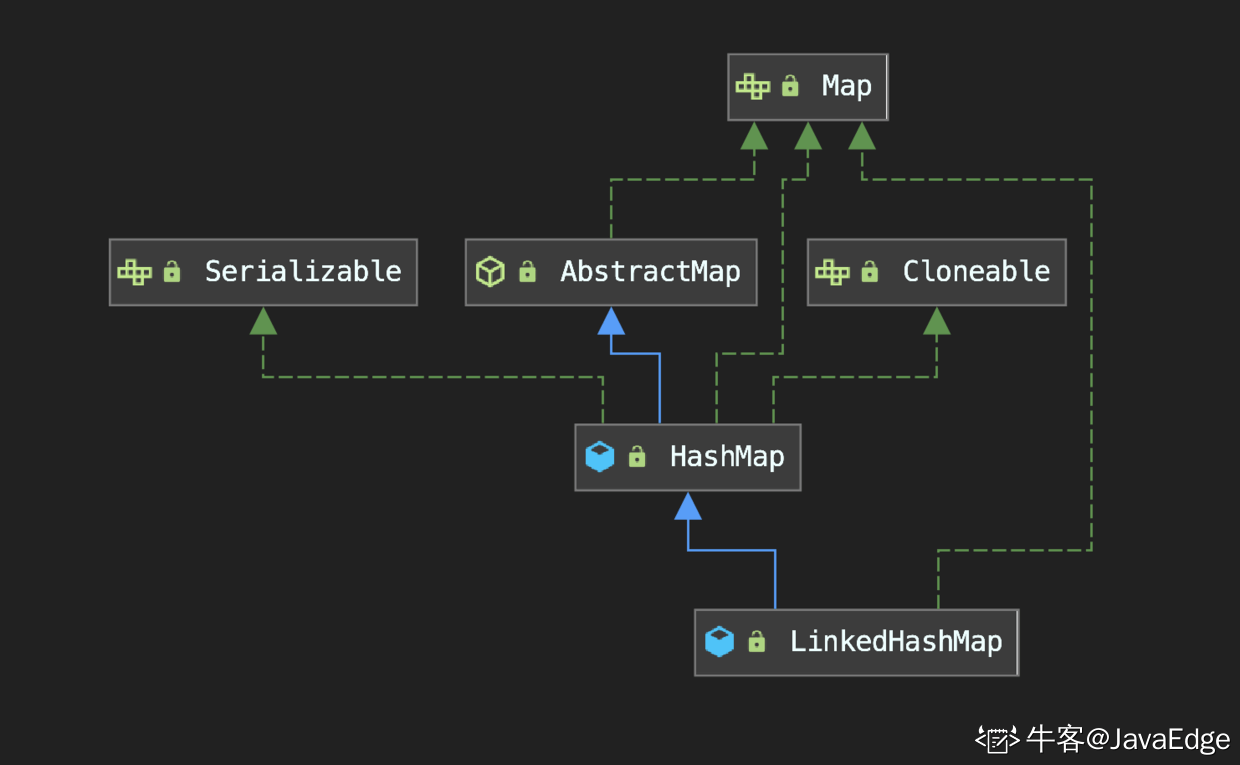
继承自 HashMap ,因此 HashMap 拥有的荣耀它也都有.

双向链表的头(最老)

双链表的末尾(最小)

HashMap.Node的子类:常规 LinkedHashMap 节点,增加了 before 和 after 属性,维护双向链表的结构

此 LinkedHashMap 的迭代排序方法:
true: 访问顺序
false(默认): 插入顺序

构造方法都是先执行父类 HashMap 的构造方法.
构造一个空的维护插入顺序的LinkedHashMap实例,其默认初始容量(16)和负载因子(0.75).

构造一个空的LinkedHashMap实例,可自己指定初始容量,负载因子和排序模式.

构造一个维护插入顺序的LinkedHashMap实例,该实例具有与指定map相同的映射关系,创建的LinkedHashMap实例具有默认的加载因子(0.75)和足以容纳指定map中映射的初始容量.

下面我们开始研究该类的主要特性是如何通过代码实现的.
LinkedHashMap 默认 accessOrder 为 false,提供按照插入顺序的访问,并没有重写父类 HashMap 的 put 方法.但在 HashMap 中,put 的是 HashMap 的 Node 类型节点,LinkedHashMap 的 Entry 与其结构并不同,又是怎样建立起双向链表的呢?下面一起看下 LinkedHashMap 插入相关代码.
忽略未重写的 put=>putValue代码部分,我们直接观察重写的
HashMap

LinkedHashMap 重写

控制新增节点追加到链表的尾部,这样每次新节点都追加到尾部,即可保证插入顺序了.
继续研究 linkNodeLast
新增节点,并追加到链表的尾部.
`// link at the end of list`
`private` `void` `linkNodeLast(LinkedHashMap.Entry<K,V> p) {`
`LinkedHashMap.Entry<K,V> last = tail;`
`// 新增于尾节点`
`tail = p;`
`// last 为null,说明链表为空`
`if` `(last == ``null``)`
`head = p;`
`// 链表非空,建立新节点和上一个尾节点的前后关系`
`else` `{`
`// 将新节点 p 直接接在链尾`
`p.before = last;`
`last.after = p;`
`}`
`}`由此得知,通过在 HashMap 基础上新增的头尾节点,节点的 before 和 after 属性,就能实现在每次新增时,把节点直接追加到尾节点,即可达到维护按照插入顺序的链表结构的目的!
图解链表创建步骤
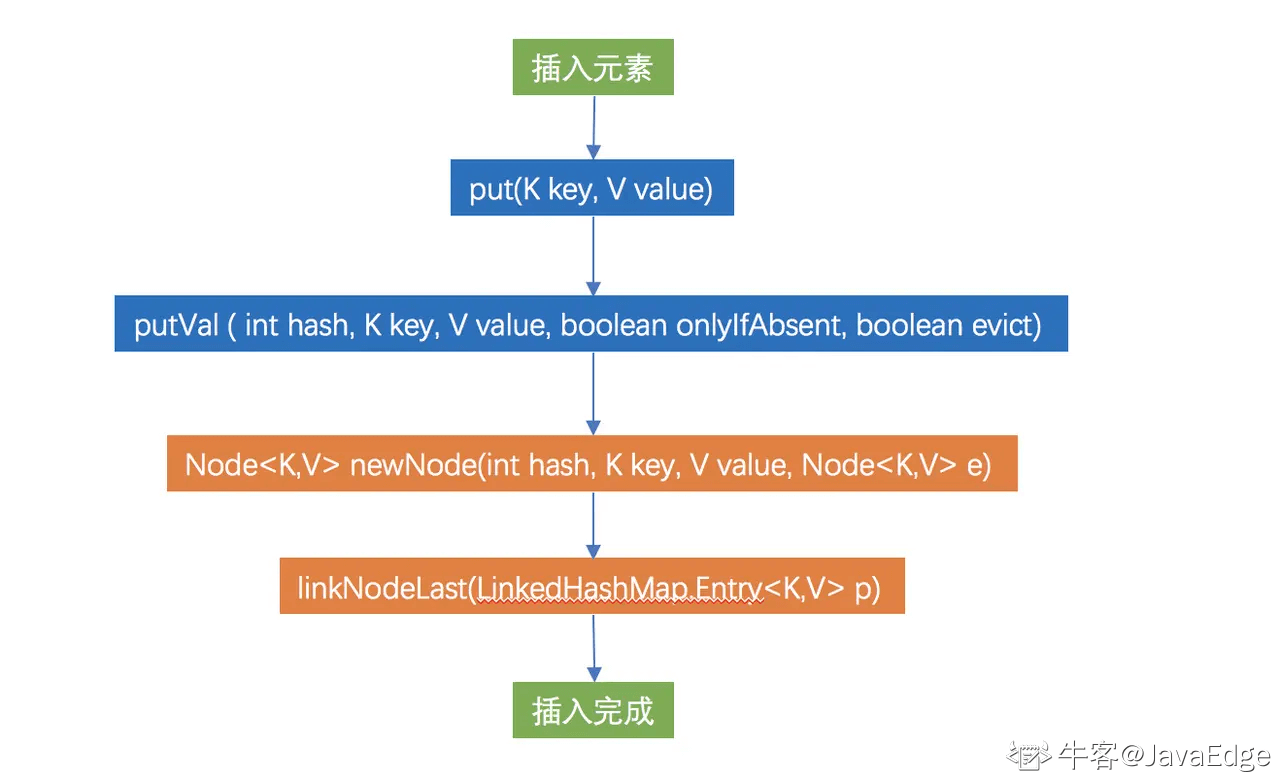
蓝色部分是 HashMap 的方法
橙色部分为 LinkedHashMap 独有方法
注意 LinkedHashMap 虽然也是双向链表,但只提供单向的按插入的顺序从头到尾访问,不及 LinkedList 般可双向无死角访问.
LinkedHashMap 通过迭代器访问,而且默认是从头节点开始访问
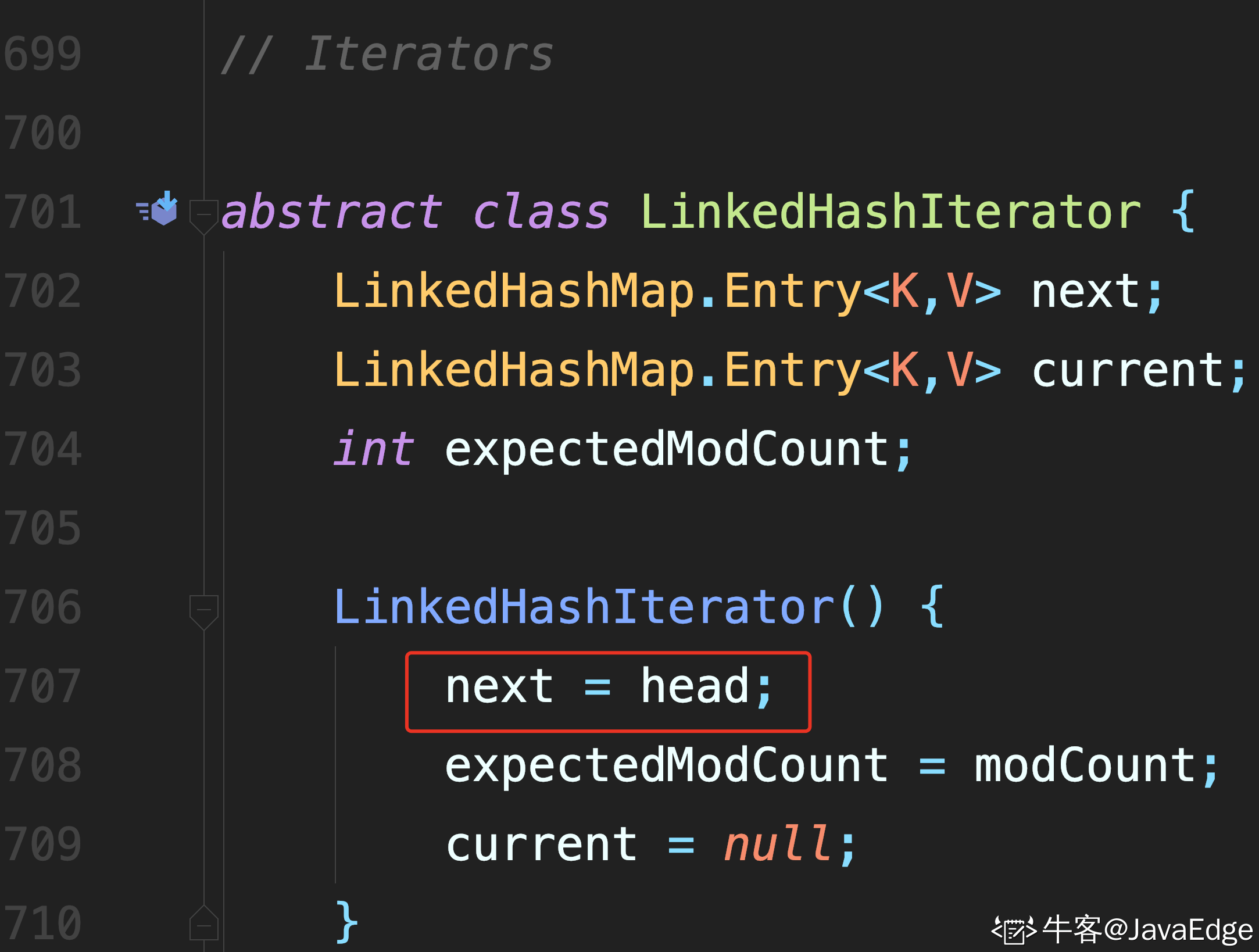
迭代过程中,不断访问 after 节点即可完成遍历.
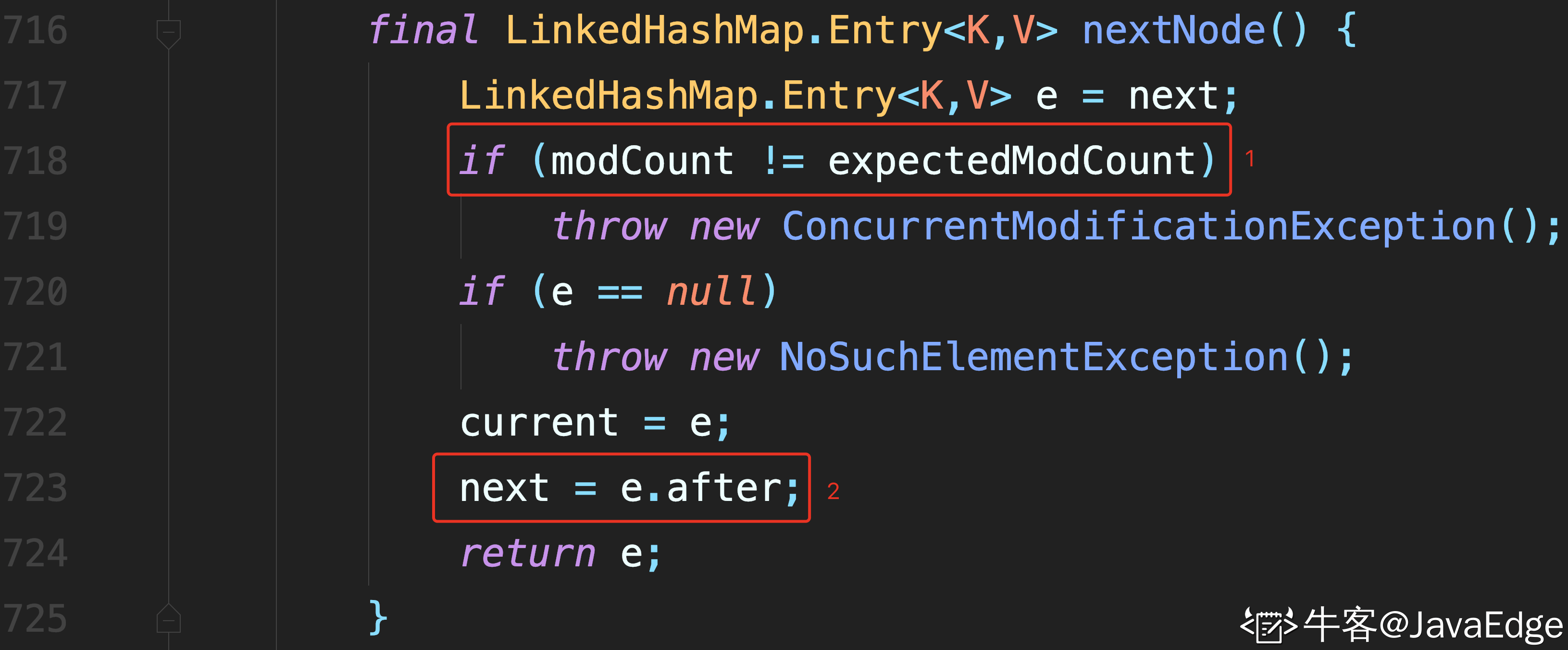
1 处进行校验
2 处通过节点的 after 属性,找到后继节点
HashMap 中保存的允许 LinkedHashMap 后处理的回调

与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现. 在删除节点时,父类不会修复 LinkedHashMap 的双向链表。那么删除及节点后,被删除的节点该如何从双链表中安全移除呢?其实在删除节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 重写了该方法.
`// e 为已经删除的节点`
`void` `afterNodeRemoval(Node<K,V> e) { ``// unlink`
`LinkedHashMap.Entry<K,V> p =`
`(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;`
`// 将 p 节点的前驱后后继引用置 null,辅助 GC`
`p.before = p.after = ``null``;`
`// p.before 为 null,表明 p 是头节点`
`if` `(b == ``null``)`
`head = a;`
`else`
`// 否则将 p 的前驱节点连接到 p 的后继节点`
`b.after = a;`
`// a 为 null,表明 p 是尾节点`
`if` `(a == ``null``)`
`tail = b;`
`else`
`// 否则将 a 的前驱节点连接到 b`
`a.before = b;`
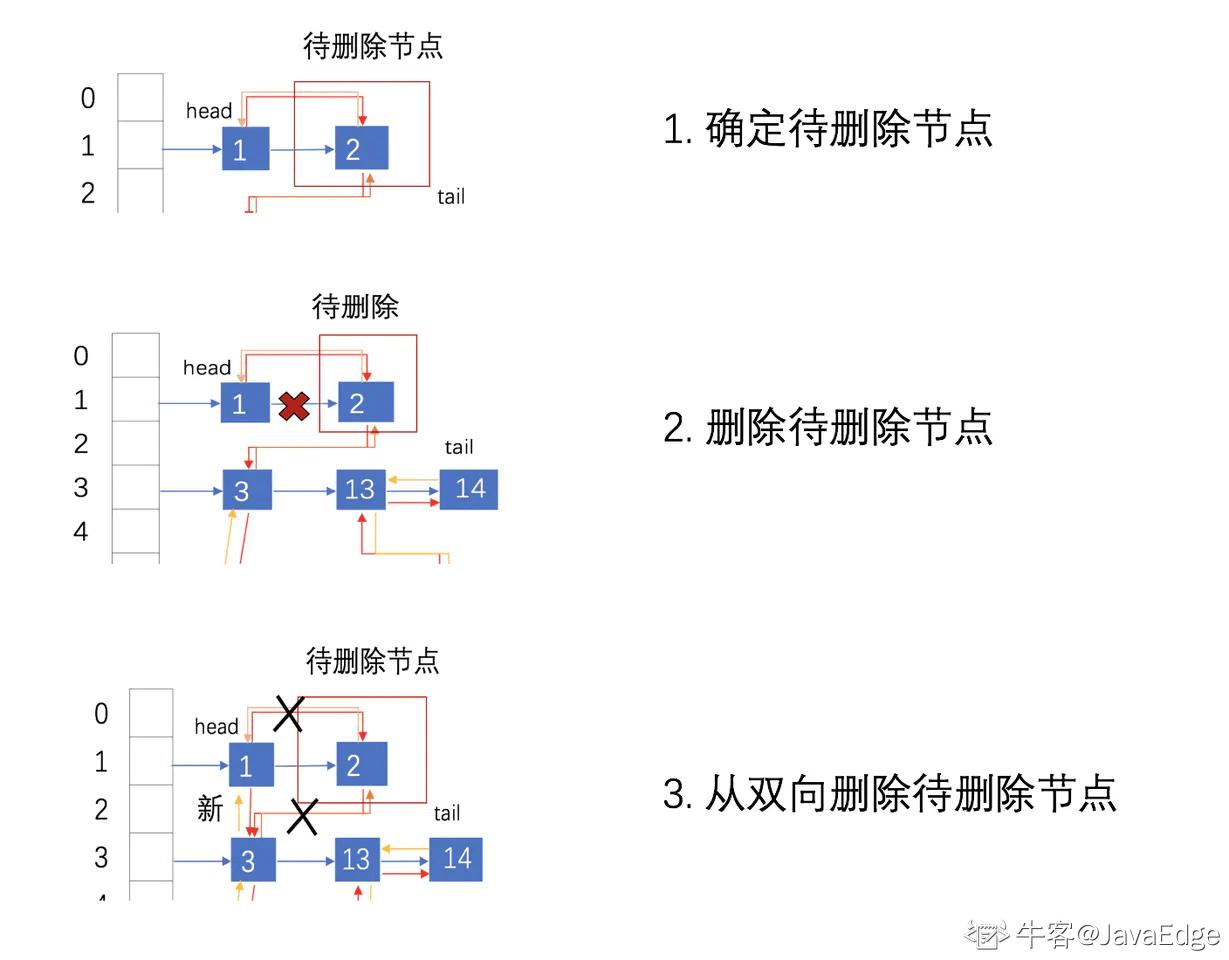
`}`删除元素的主要流程:
根据 hash 定位到桶位置
遍历链表或调用红黑树相关的删除方法
从 LinkedHashMap 维护的双链表中移除要删除的节点
转存失败重新上传取消
经常访问的元素会被追加到队尾,这样不经常访问的数据自然就靠近队头,然后可以通过设置删除策略,比如当 Map 元素个数大于多少时,把头节点删除
get 时,元素会被移动到队尾:

`public` `V get(Object key) {`
`Node<K,V> e;`
`// 调用 HashMap get 方法`
`if` `((e = getNode(hash(key), key)) == ``null``)`
`return` `null``;`
`// 如果设置了 LRU 策略`
`if` `(accessOrder)`
`// 这个方法把当前 key 移动到队尾`
`afterNodeAccess(e);`
`return` `e.value;`
`}`从上述源码中,可以看到,通过 afterNodeAccess 方法把当前访问节点移动到了队尾,其实不仅仅是 get 方法,执行 getOrDefault、compute、computeIfAbsent、computeIfPresent、merge 方法时,也会这么做,通过不断的把经常访问的节点移动到队尾,那么靠近队头的节点,自然就是很少被访问的元素了。
以上是“java中LinkedHashMap的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





