这篇文章主要介绍“怎么使用PyCharm Profile分析异步爬虫效率”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“怎么使用PyCharm Profile分析异步爬虫效率”文章能帮助大家解决问题。
第一个代码如下,就是一个普通的 for 循环爬虫。原文地址。
import requests
import bs4
from colorama import Fore
def main():
get_title_range()
print("Done.")
def get_html(episode_number: int) -> str:
print(Fore.YELLOW + f"Getting HTML for episode {episode_number}", flush=True)
url = f'https://talkpython.fm/{episode_number}'
resp = requests.get(url)
resp.raise_for_status()
return resp.text
def get_title(html: str, episode_number: int) -> str:
print(Fore.CYAN + f"Getting TITLE for episode {episode_number}", flush=True)
soup = bs4.BeautifulSoup(html, 'html.parser')
header = soup.select_one('h2')
if not header:
return "MISSING"
return header.text.strip()
def get_title_range():
# Please keep this range pretty small to not DDoS my site. ;)
for n in range(185, 200):
html = get_html(n)
title = get_title(html, n)
print(Fore.WHITE + f"Title found: {title}", flush=True)
if __name__ == '__main__':
main()这段代码跑完花了37s,然后我们用 pycharm 的 profiler 工具来具体看看哪些地方比较耗时间。
点击Profile (文件名称)
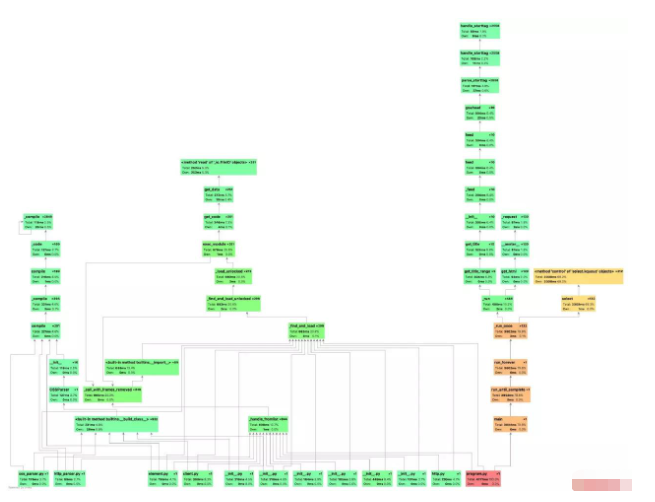
之后获取到得到一个详细的函数调用关系、耗时图:

可以看到 get_html 这个方法占了96.7%的时间。这个程序的 IO 耗时达到了97%,获取 html 的时候,这段时间内程序就在那死等着。如果我们能够让他不要在那儿傻傻地等待 IO 完成,而是开始干些其他有意义的事,就能节省大量的时间。
稍微做一个计算,试用asyncio异步抓取,能将时间降低多少?
get_html这个方法耗时36.8s,一共调用了15次,说明实际上获取一个链接的 html 的时间为36.8s / 15 = 2.4s。**要是全异步的话,获取15个链接的时间还是2.4s。**然后加上get_title这个函数的耗时0.6s,所以我们估算,改进后的程序将可以用 3s 左右的时间完成,也就是性能能够提升13倍。
再看下改进后的代码。原文地址。
import asyncio
from asyncio import AbstractEventLoop
import aiohttp
import requests
import bs4
from colorama import Fore
def main():
# Create loop
loop = asyncio.get_event_loop()
loop.run_until_complete(get_title_range(loop))
print("Done.")
async def get_html(episode_number: int) -> str:
print(Fore.YELLOW + f"Getting HTML for episode {episode_number}", flush=True)
# Make this async with aiohttp's ClientSession
url = f'https://talkpython.fm/{episode_number}'
# resp = await requests.get(url)
# resp.raise_for_status()
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
resp.raise_for_status()
html = await resp.text()
return html
def get_title(html: str, episode_number: int) -> str:
print(Fore.CYAN + f"Getting TITLE for episode {episode_number}", flush=True)
soup = bs4.BeautifulSoup(html, 'html.parser')
header = soup.select_one('h2')
if not header:
return "MISSING"
return header.text.strip()
async def get_title_range(loop: AbstractEventLoop):
# Please keep this range pretty small to not DDoS my site. ;)
tasks = []
for n in range(190, 200):
tasks.append((loop.create_task(get_html(n)), n))
for task, n in tasks:
html = await task
title = get_title(html, n)
print(Fore.WHITE + f"Title found: {title}", flush=True)
if __name__ == '__main__':
main()同样的步骤生成profile 图:
可见现在耗时为大约3.8s,基本符合我们的预期了。

关于“怎么使用PyCharm Profile分析异步爬虫效率”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





