linux swapжҳҜжҖҺд№Ҳи§ҰеҸ‘зҡ„
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢlinux swapжҳҜжҖҺд№Ҳи§ҰеҸ‘зҡ„зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
linux swapжҢҮзҡ„жҳҜlinuxдәӨжҚўеҲҶеҢәпјҢжҳҜзЈҒзӣҳдёҠзҡ„дёҖеқ—еҢәеҹҹпјҢеҸҜд»ҘжҳҜдёҖдёӘеҲҶеҢәпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘж–Ү件пјҢжҲ–иҖ…жҳҜдёӨиҖ…зҡ„з»„еҗҲпјӣswapзұ»дјјдәҺWindowsзҡ„иҷҡжӢҹеҶ…еӯҳпјҢе°ұжҳҜеҪ“еҶ…еӯҳдёҚи¶іж—¶пјҢжҠҠдёҖйғЁеҲҶзЎ¬зӣҳз©әй—ҙиҷҡжӢҹжҲҗеҶ…еӯҳдҪҝз”ЁпјҢд»ҺиҖҢи§ЈеҶіеҶ…еӯҳе®№йҮҸдёҚи¶ізҡ„жғ…еҶөгҖӮ
жң¬ж•ҷзЁӢж“ҚдҪңзҺҜеўғпјҡlinux5.9.8зі»з»ҹгҖҒDell G3з”өи„‘гҖӮ
linux swap
Linux зҡ„дәӨжҚўеҲҶеҢәпјҲswapпјүпјҢжҲ–иҖ…еҸ«еҶ…еӯҳзҪ®жҚўз©әй—ҙпјҲswap spaceпјүпјҢжҳҜзЈҒзӣҳдёҠзҡ„дёҖеқ—еҢәеҹҹпјҢеҸҜд»ҘжҳҜдёҖдёӘеҲҶеҢәпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘж–Ү件пјҢжҲ–иҖ…жҳҜ他们зҡ„з»„еҗҲгҖӮ
SWAPзҡ„дҪңз”Ёзұ»дјјWindowsзі»з»ҹдёӢзҡ„вҖңиҷҡжӢҹеҶ…еӯҳвҖқгҖӮеҪ“зү©зҗҶеҶ…еӯҳдёҚи¶іж—¶пјҢжӢҝеҮәйғЁеҲҶзЎ¬зӣҳз©әй—ҙеҪ“SWAPеҲҶеҢәпјҲиҷҡжӢҹжҲҗеҶ…еӯҳпјүдҪҝз”ЁпјҢд»ҺиҖҢи§ЈеҶіеҶ…еӯҳе®№йҮҸдёҚи¶ізҡ„жғ…еҶөгҖӮ
SWAPж„ҸжҖқжҳҜдәӨжҚўпјҢйЎҫеҗҚжҖқд№үпјҢеҪ“жҹҗиҝӣзЁӢеҗ‘OSиҜ·жұӮеҶ…еӯҳеҸ‘зҺ°дёҚи¶іж—¶пјҢOSдјҡжҠҠеҶ…еӯҳдёӯжҡӮж—¶дёҚз”Ёзҡ„ж•°жҚ®дәӨжҚўеҮәеҺ»пјҢж”ҫеңЁSWAPеҲҶеҢәдёӯпјҢиҝҷдёӘиҝҮзЁӢз§°дёәSWAP OUTгҖӮеҪ“жҹҗиҝӣзЁӢеҸҲйңҖиҰҒиҝҷдәӣж•°жҚ®дё”OSеҸ‘зҺ°иҝҳжңүз©әй—Ізү©зҗҶеҶ…еӯҳж—¶пјҢеҸҲдјҡжҠҠSWAPеҲҶеҢәдёӯзҡ„ж•°жҚ®дәӨжҚўеӣһзү©зҗҶеҶ…еӯҳдёӯпјҢиҝҷдёӘиҝҮзЁӢз§°дёәSWAP INгҖӮ
еҪ“然пјҢswapеӨ§е°ҸжҳҜжңүдёҠйҷҗзҡ„пјҢдёҖж—ҰswapдҪҝз”Ёе®ҢпјҢж“ҚдҪңзі»з»ҹдјҡи§ҰеҸ‘OOM-KillerжңәеҲ¶пјҢжҠҠж¶ҲиҖ—еҶ…еӯҳжңҖеӨҡзҡ„иҝӣзЁӢkillжҺүд»ҘйҮҠж”ҫеҶ…еӯҳгҖӮ
ж•°жҚ®еә“зі»з»ҹдёәд»Җд№Ҳе«Ңејғswapпјҹ
жҳҫ然пјҢswapжңәеҲ¶зҡ„еҲқиЎ·жҳҜдёәдәҶзј“и§Јзү©зҗҶеҶ…еӯҳз”Ёе°ҪиҖҢйҖүжӢ©зӣҙжҺҘзІ—жҡҙOOMиҝӣзЁӢзҡ„е°ҙе°¬гҖӮдҪҶеқҰзҷҪи®ІпјҢеҮ д№ҺжүҖжңүж•°жҚ®еә“еҜ№swapйғҪдёҚжҖҺд№Ҳеҫ…и§ҒпјҢж— и®әMySQLгҖҒOracalгҖҒMongoDBжҠ‘жҲ–HBaseпјҢдёәд»Җд№Ҳпјҹиҝҷдё»иҰҒе’ҢдёӢйқўдёӨдёӘж–№йқўжңүе…іпјҡ
1. ж•°жҚ®еә“зі»з»ҹдёҖиҲ¬йғҪеҜ№е“Қеә”延иҝҹжҜ”иҫғж•Ҹж„ҹпјҢеҰӮжһңдҪҝз”Ёswapд»ЈжӣҝеҶ…еӯҳпјҢж•°жҚ®еә“жңҚеҠЎжҖ§иғҪеҝ…然дёҚеҸҜжҺҘеҸ—гҖӮеҜ№дәҺе“Қеә”延иҝҹжһҒе…¶ж•Ҹж„ҹзҡ„зі»з»ҹжқҘи®ІпјҢ延иҝҹеӨӘеӨ§е’ҢжңҚеҠЎдёҚеҸҜз”ЁжІЎжңүд»»дҪ•еҢәеҲ«пјҢжҜ”жңҚеҠЎдёҚеҸҜз”ЁжӣҙдёҘйҮҚзҡ„жҳҜпјҢswapеңәжҷҜдёӢиҝӣзЁӢе°ұжҳҜдёҚжӯ»пјҢиҝҷе°ұж„Ҹе‘ізқҖзі»з»ҹдёҖзӣҙдёҚеҸҜз”ЁвҖҰвҖҰеҶҚжғіжғіеҰӮжһңдёҚдҪҝз”ЁswapзӣҙжҺҘoomпјҢжҳҜдёҚжҳҜдёҖз§ҚжӣҙеҘҪзҡ„йҖүжӢ©пјҢиҝҷж ·еҫҲеӨҡй«ҳеҸҜз”Ёзі»з»ҹзӣҙжҺҘдјҡдё»д»ҺеҲҮжҚўжҺүпјҢз”ЁжҲ·еҹәжң¬ж— ж„ҹзҹҘгҖӮ
2. еҸҰеӨ–еҜ№дәҺиҜёеҰӮHBaseиҝҷзұ»еҲҶеёғејҸзі»з»ҹжқҘиҜҙпјҢе…¶е®һ并дёҚжӢ…еҝғжҹҗдёӘиҠӮзӮ№е®•жҺүпјҢиҖҢжҒ°жҒ°жӢ…еҝғжҹҗдёӘиҠӮзӮ№еӨҜдҪҸгҖӮдёҖдёӘиҠӮзӮ№е®•жҺүпјҢжңҖеӨҡе°ұжҳҜе°ҸйғЁеҲҶиҜ·жұӮзҹӯжҡӮдёҚеҸҜз”ЁпјҢйҮҚиҜ•еҚіеҸҜжҒўеӨҚгҖӮдҪҶжҳҜдёҖдёӘиҠӮзӮ№еӨҜдҪҸдјҡе°ҶжүҖжңүеҲҶеёғејҸиҜ·жұӮйғҪеӨҜдҪҸпјҢжңҚеҠЎеҷЁз«ҜзәҝзЁӢиө„жәҗиў«еҚ з”ЁдёҚж”ҫпјҢеҜјиҮҙж•ҙдёӘйӣҶзҫӨиҜ·жұӮйҳ»еЎһпјҢз”ҡиҮійӣҶзҫӨиў«жӢ–еһ®гҖӮ
д»ҺиҝҷдёӨдёӘи§’еәҰиҖғиҷ‘пјҢжүҖжңүж•°жҚ®еә“йғҪдёҚе–ңж¬ўswapиҝҳжҳҜеҫҲжңүйҒ“зҗҶзҡ„пјҒ
swapзҡ„е·ҘдҪңжңәеҲ¶
既然数жҚ®еә“们еҜ№swapдёҚеҫ…и§ҒпјҢйӮЈжҳҜдёҚжҳҜе°ұиҰҒдҪҝз”Ёswapoffе‘Ҫд»Өе…ій—ӯзЈҒзӣҳзј“еӯҳзү№жҖ§е‘ўпјҹйқһд№ҹпјҢеӨ§е®¶еҸҜд»ҘжғіжғіпјҢе…ій—ӯзЈҒзӣҳзј“еӯҳж„Ҹе‘ізқҖд»Җд№Ҳпјҹе®һйҷ…з”ҹдә§зҺҜеўғжІЎжңүдёҖдёӘзі»з»ҹдјҡеҰӮжӯӨжҝҖиҝӣпјҢиҰҒзҹҘйҒ“иҝҷдёӘдё–з•Ңж°ёиҝңдёҚжҳҜйқһ0еҚі1зҡ„пјҢеӨ§е®¶йғҪдјҡжҲ–еӨҡжҲ–е°‘йҖүжӢ©иө°еңЁдёӯй—ҙпјҢдёҚиҝҮжңүдәӣеҒҸеҗ‘0пјҢжңүдәӣеҒҸеҗ‘1иҖҢе·ІгҖӮеҫҲжҳҫ然пјҢеңЁswapиҝҷдёӘй—®йўҳдёҠпјҢж•°жҚ®еә“еҝ…然йҖүжӢ©еҒҸеҗ‘е°ҪйҮҸе°‘з”ЁгҖӮHBaseе®ҳж–№ж–ҮжЎЈзҡ„еҮ зӮ№иҰҒжұӮе®һйҷ…дёҠе°ұжҳҜиҗҪе®һиҝҷдёӘж–№й’Ҳпјҡе°ҪеҸҜиғҪйҷҚдҪҺswapеҪұе“ҚгҖӮзҹҘе·ұзҹҘеҪјжүҚиғҪзҷҫжҲҳдёҚж®ҶпјҢиҰҒйҷҚдҪҺswapеҪұе“Қе°ұеҝ…йЎ»еј„жё…жҘҡLinuxеҶ…еӯҳеӣһ收жҳҜжҖҺд№Ҳе·ҘдҪңзҡ„пјҢиҝҷж ·жүҚиғҪдёҚйҒ—жјҸд»»дҪ•еҸҜиғҪзҡ„з–‘зӮ№гҖӮ
е…ҲжқҘзңӢзңӢswapжҳҜеҰӮдҪ•и§ҰеҸ‘зҡ„пјҹ
з®ҖеҚ•жқҘиҜҙпјҢLinuxдјҡеңЁдёӨз§ҚеңәжҷҜдёӢи§ҰеҸ‘еҶ…еӯҳеӣһ收пјҢдёҖз§ҚжҳҜеңЁеҶ…еӯҳеҲҶй…Қж—¶еҸ‘зҺ°жІЎжңүи¶іеӨҹз©әй—ІеҶ…еӯҳж—¶дјҡз«ӢеҲ»и§ҰеҸ‘еҶ…еӯҳеӣһ收пјӣдёҖз§ҚжҳҜејҖеҗҜдәҶдёҖдёӘе®ҲжҠӨиҝӣзЁӢпјҲswapdиҝӣзЁӢпјүе‘ЁжңҹжҖ§еҜ№зі»з»ҹеҶ…еӯҳиҝӣиЎҢжЈҖжҹҘпјҢеңЁеҸҜз”ЁеҶ…еӯҳйҷҚдҪҺеҲ°зү№е®ҡйҳҲеҖјд№ӢеҗҺдё»еҠЁи§ҰеҸ‘еҶ…еӯҳеӣһ收гҖӮ第дёҖз§ҚеңәжҷҜжІЎд»Җд№ҲеҸҜиҜҙпјҢжқҘйҮҚзӮ№иҒҠиҒҠ第дәҢз§ҚеңәжҷҜпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
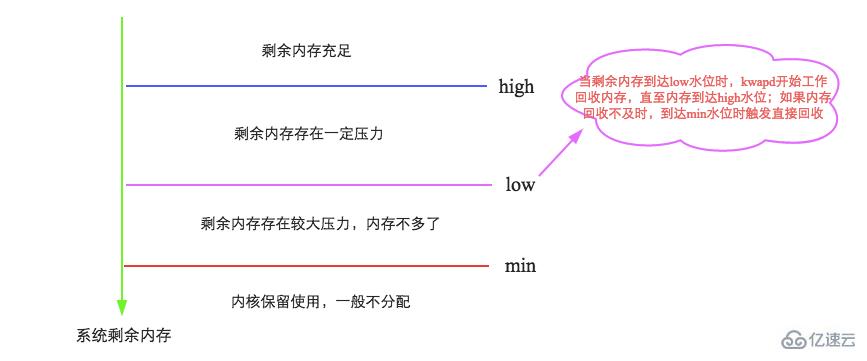
иҝҷйҮҢе°ұиҰҒеј•еҮәжҲ‘们关注зҡ„第дёҖдёӘеҸӮж•°пјҡvm.min_free_kbytesпјҢд»ЈиЎЁзі»з»ҹжүҖдҝқз•ҷз©әй—ІеҶ…еӯҳзҡ„жңҖдҪҺйҷҗwatermark[min]пјҢ并且еҪұе“Қwatermark[low]е’Ңwatermark[high]гҖӮз®ҖеҚ•еҸҜд»Ҙи®Өдёәпјҡ
watermark[min] = min_free_kbytes
watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4
watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2
watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
еҸҜи§ҒпјҢLInuxзҡ„иҝҷеҮ дёӘж°ҙдҪҚзәҝдёҺеҸӮж•°min_free_kbytesеҜҶдёҚеҸҜеҲҶгҖӮmin_free_kbytesеҜ№дәҺзі»з»ҹзҡ„йҮҚиҰҒжҖ§дёҚиЁҖиҖҢе–»пјҢж—ўдёҚиғҪеӨӘеӨ§пјҢд№ҹдёҚиғҪеӨӘе°ҸгҖӮ
min_free_kbytesеҰӮжһңеӨӘе°ҸпјҢпј»min,lowпјҪд№Ӣй—ҙж°ҙдҪҚзҡ„bufferе°ұдјҡеҫҲе°ҸпјҢеңЁkswapdеӣһ收зҡ„иҝҮзЁӢдёӯдёҖж—ҰдёҠеұӮз”іиҜ·еҶ…еӯҳзҡ„йҖҹеәҰеӨӘеҝ«пјҲе…ёеһӢеә”з”Ёпјҡж•°жҚ®еә“пјүпјҢе°ұдјҡеҜјиҮҙз©әй—ІеҶ…еӯҳжһҒжҳ“йҷҚиҮіwatermark[min]д»ҘдёӢпјҢжӯӨж—¶еҶ…ж ёе°ұдјҡиҝӣиЎҢdirect reclaimпјҲзӣҙжҺҘеӣһ收пјүпјҢзӣҙжҺҘеңЁеә”з”ЁзЁӢеәҸзҡ„иҝӣзЁӢдёҠдёӢж–ҮдёӯиҝӣиЎҢеӣһ收пјҢеҶҚз”Ёеӣһ收дёҠжқҘзҡ„з©әй—ІйЎөж»Ўи¶іеҶ…еӯҳз”іиҜ·пјҢеӣ жӯӨе®һйҷ…дјҡйҳ»еЎһеә”з”ЁзЁӢеәҸпјҢеёҰжқҘдёҖе®ҡзҡ„е“Қеә”延иҝҹгҖӮеҪ“然пјҢmin_free_kbytesд№ҹдёҚе®ңеӨӘеӨ§пјҢеӨӘеӨ§дёҖж–№йқўдјҡеҜјиҮҙеә”з”ЁзЁӢеәҸиҝӣзЁӢеҶ…еӯҳеҮҸе°‘пјҢжөӘиҙ№зі»з»ҹеҶ…еӯҳиө„жәҗпјҢеҸҰдёҖж–№йқўиҝҳдјҡеҜјиҮҙkswapdиҝӣзЁӢиҠұиҙ№еӨ§йҮҸж—¶й—ҙиҝӣиЎҢеҶ…еӯҳеӣһ收гҖӮеҶҚзңӢзңӢиҝҷдёӘиҝҮзЁӢпјҢжҳҜдёҚжҳҜе’ҢJavaеһғеңҫеӣһ收жңәеҲ¶дёӯCMSз®—жі•дёӯиҖҒз”ҹд»Јеӣһ收и§ҰеҸ‘жңәеҲ¶зҘһдјјпјҢжғіжғіеҸӮж•°-XX:CMSInitiatingOccupancyFractionпјҢжҳҜдёҚжҳҜпјҹе®ҳж–№ж–ҮжЎЈдёӯиҰҒжұӮmin_free_kbytesдёҚиғҪе°ҸдәҺ1GпјҲеңЁеӨ§еҶ…еӯҳзі»з»ҹдёӯи®ҫзҪ®8GпјүпјҢе°ұжҳҜдёҚиҰҒиҪ»жҳ“и§ҰеҸ‘зӣҙжҺҘеӣһ收гҖӮ
иҮіжӯӨпјҢеҹәжң¬и§ЈйҮҠдәҶLinuxзҡ„еҶ…еӯҳеӣһ收и§ҰеҸ‘жңәеҲ¶д»ҘеҸҠжҲ‘们关注зҡ„第дёҖдёӘеҸӮж•°vm.min_free_kbytesгҖӮжҺҘдёӢжқҘз®ҖеҚ•зңӢзңӢLinuxеҶ…еӯҳеӣһ收йғҪеӣһ收дәӣд»Җд№ҲгҖӮLinuxеҶ…еӯҳеӣһ收еҜ№иұЎдё»иҰҒеҲҶдёәдёӨз§Қпјҡ
1. ж–Ү件缓еӯҳпјҢиҝҷдёӘе®№жҳ“зҗҶи§ЈпјҢдёәдәҶйҒҝе…Қж–Ү件数жҚ®жҜҸж¬ЎйғҪиҰҒд»ҺзЎ¬зӣҳиҜ»еҸ–пјҢзі»з»ҹдјҡе°ҶзғӯзӮ№ж•°жҚ®еӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢжҸҗй«ҳжҖ§иғҪгҖӮеҰӮжһңд»…д»…е°Ҷж–Ү件иҜ»еҮәжқҘпјҢеҶ…еӯҳеӣһ收еҸӘйңҖиҰҒйҮҠж”ҫиҝҷйғЁеҲҶеҶ…еӯҳеҚіеҸҜпјҢдёӢж¬ЎеҶҚж¬ЎиҜ»еҸ–иҜҘж–Ү件数жҚ®зӣҙжҺҘд»ҺзЎ¬зӣҳдёӯиҜ»еҸ–еҚіеҸҜпјҲзұ»дјјHBaseж–Ү件缓еӯҳпјүгҖӮйӮЈеҰӮжһңдёҚд»…е°Ҷж–Ү件иҜ»еҮәжқҘпјҢиҖҢдё”еҜ№иҝҷдәӣзј“еӯҳзҡ„ж–Ү件数жҚ®иҝӣиЎҢдәҶдҝ®ж”№пјҲи„Ҹж•°жҚ®пјүпјҢеӣһ收еҶ…еӯҳе°ұйңҖиҰҒе°ҶиҝҷйғЁеҲҶж•°жҚ®ж–Ү件еҶҷдјҡзЎ¬зӣҳеҶҚйҮҠж”ҫпјҲзұ»дјјMySQLж–Ү件缓еӯҳпјүгҖӮ
2. еҢҝеҗҚеҶ…еӯҳпјҢиҝҷйғЁеҲҶеҶ…еӯҳжІЎжңүе®һйҷ…иҪҪдҪ“пјҢдёҚеғҸж–Ү件缓еӯҳжңүзЎ¬зӣҳж–Ү件иҝҷж ·дёҖдёӘиҪҪдҪ“пјҢжҜ”еҰӮе…ёеһӢзҡ„е ҶгҖҒж Ҳж•°жҚ®зӯүгҖӮиҝҷйғЁеҲҶеҶ…еӯҳеңЁеӣһ收зҡ„ж—¶еҖҷдёҚиғҪзӣҙжҺҘйҮҠж”ҫжҲ–иҖ…еҶҷеӣһзұ»дјјж–Ү件зҡ„еӘ’д»ӢдёӯпјҢиҝҷжүҚжҗһеҮәжқҘswapиҝҷдёӘжңәеҲ¶пјҢе°Ҷиҝҷзұ»еҶ…еӯҳжҚўеҮәеҲ°зЎ¬зӣҳдёӯпјҢйңҖиҰҒзҡ„ж—¶еҖҷеҶҚеҠ иҪҪеҮәжқҘгҖӮ
е…·дҪ“LinuxдҪҝз”Ёд»Җд№Ҳз®—жі•жқҘзЎ®и®Өе“Әдәӣж–Ү件缓еӯҳжҲ–иҖ…еҢҝеҗҚеҶ…еӯҳйңҖиҰҒиў«еӣһ收жҺүпјҢиҝҷйҮҢ并дёҚе…іеҝғпјҢжңүе…ҙи¶ЈеҸҜд»ҘеҸӮиҖғиҝҷйҮҢгҖӮдҪҶжҳҜжңүдёӘй—®йўҳйңҖиҰҒжҲ‘们жҖқиҖғпјҡ既然жңүдёӨзұ»еҶ…еӯҳеҸҜд»Ҙиў«еӣһ收пјҢйӮЈд№ҲеңЁиҝҷдёӨзұ»еҶ…еӯҳйғҪеҸҜд»Ҙиў«еӣһ收зҡ„жғ…еҶөдёӢпјҢLinuxеҲ°еә•жҳҜеҰӮдҪ•еҶіе®ҡеҲ°еә•жҳҜеӣһ收е“Әзұ»еҶ…еӯҳе‘ўпјҹиҝҳжҳҜдёӨиҖ…йғҪдјҡиў«еӣһ收пјҹиҝҷйҮҢе°ұзүөеҮәжқҘдәҶжҲ‘们第дәҢдёӘе…іеҝғзҡ„еҸӮж•°пјҡswappinessпјҢиҝҷдёӘеҖјз”ЁжқҘе®ҡд№үеҶ…ж ёдҪҝз”Ёswapзҡ„з§ҜжһҒзЁӢеәҰпјҢеҖји¶Ҡй«ҳпјҢеҶ…ж ёе°ұдјҡз§ҜжһҒең°дҪҝз”ЁswapпјҢеҖји¶ҠдҪҺпјҢе°ұдјҡйҷҚдҪҺеҜ№swapзҡ„дҪҝз”Ёз§ҜжһҒжҖ§гҖӮиҜҘеҖјеҸ–еҖјиҢғеӣҙеңЁ0пҪһ100пјҢй»ҳи®ӨжҳҜ60гҖӮиҝҷдёӘswappinessеҲ°еә•жҳҜжҖҺд№Ҳе®һзҺ°зҡ„е‘ўпјҹе…·дҪ“еҺҹзҗҶеҫҲеӨҚжқӮпјҢз®ҖеҚ•жқҘи®ІпјҢswappinessйҖҡиҝҮжҺ§еҲ¶еҶ…еӯҳеӣһ收时пјҢеӣһ收зҡ„еҢҝеҗҚйЎөжӣҙеӨҡдёҖдәӣиҝҳжҳҜеӣһ收зҡ„ж–Ү件缓еӯҳжӣҙеӨҡдёҖдәӣжқҘиҫҫеҲ°иҝҷдёӘж•ҲжһңгҖӮswappinessзӯүдәҺ100пјҢиЎЁзӨәеҢҝеҗҚеҶ…еӯҳе’Ңж–Ү件缓еӯҳе°Ҷз”ЁеҗҢж ·зҡ„дјҳе…Ҳзә§иҝӣиЎҢеӣһ收пјҢй»ҳи®Ө60иЎЁзӨәж–Ү件缓еӯҳдјҡдјҳе…Ҳиў«еӣһ收жҺүпјҢиҮідәҺдёәд»Җд№Ҳж–Ү件缓еӯҳиҰҒиў«дјҳе…Ҳеӣһ收жҺүпјҢеӨ§е®¶дёҚеҰЁжғіжғіпјҲеӣһ收ж–Ү件缓еӯҳйҖҡеёёжғ…еҶөдёӢдёҚдјҡеј•иө·IOж“ҚдҪңпјҢеҜ№зі»з»ҹжҖ§иғҪеҪұе“Қиҫғе°ҸпјүгҖӮеҜ№дәҺж•°жҚ®еә“жқҘи®ІпјҢswapжҳҜе°ҪйҮҸйңҖиҰҒйҒҝе…Қзҡ„пјҢжүҖд»ҘйңҖиҰҒе°Ҷе…¶и®ҫзҪ®дёә0гҖӮжӯӨеӨ„йңҖиҰҒжіЁж„ҸпјҢи®ҫзҪ®дёә0并дёҚд»ЈиЎЁдёҚжү§иЎҢswapе“ҰпјҒ
иҮіжӯӨпјҢжҲ‘们д»ҺLinuxеҶ…еӯҳеӣһ收и§ҰеҸ‘жңәеҲ¶гҖҒLinuxеҶ…еӯҳеӣһ收еҜ№иұЎдёҖзӣҙиҒҠеҲ°swapпјҢе°ҶеҸӮж•°min_free_kbytesд»ҘеҸҠswappinessиҝӣиЎҢдәҶи§ЈйҮҠгҖӮжҺҘдёӢжқҘзңӢзңӢеҸҰдёҖдёӘдёҺswapжңүе…ізі»зҡ„еҸӮж•°пјҡzone_reclaim_modeпјҢж–ҮжЎЈиҜҙдәҶи®ҫзҪ®иҝҷдёӘеҸӮж•°дёә0еҸҜд»Ҙе…ій—ӯNUMAзҡ„zone reclaimпјҢиҝҷеҸҲжҳҜжҖҺд№ҲеӣһдәӢпјҹжҸҗиө·NUMAпјҢж•°жҚ®еә“们еҸҲйғҪдёҚй«ҳе…ҙдәҶпјҢеҫҲеӨҡDBAйғҪжӣҫз»Ҹиў«еқ‘жғЁиҝҮгҖӮйӮЈиҝҷйҮҢз®ҖеҚ•иҜҙжҳҺдёүдёӘе°Ҹй—®йўҳпјҡNUMAжҳҜд»Җд№ҲпјҹNUMAе’Ңswapжңүд»Җд№Ҳе…ізі»пјҹzone_reclaim_modeзҡ„е…·дҪ“ж„Ҹд№үпјҹ
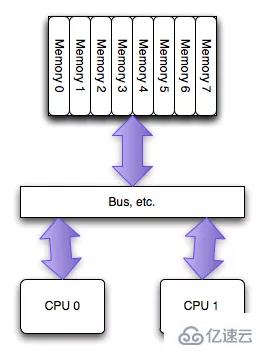
NUMAпјҲNon-Uniform Memory AccessпјүжҳҜзӣёеҜ№UMAжқҘиҜҙзҡ„пјҢдёӨиҖ…йғҪжҳҜCPUзҡ„и®ҫи®Ўжһ¶жһ„пјҢж—©жңҹCPUи®ҫи®ЎдёәUMAз»“жһ„пјҢеҰӮдёӢеӣҫ(еӣҫзүҮжқҘиҮӘзҪ‘з»ң)жүҖзӨәпјҡ
дёәдәҶзј“и§ЈеӨҡж ёCPUиҜ»еҸ–еҗҢдёҖеқ—еҶ…еӯҳжүҖйҒҮеҲ°зҡ„йҖҡйҒ“瓶йўҲй—®йўҳпјҢиҠҜзүҮе·ҘзЁӢеёҲеҸҲи®ҫи®ЎдәҶNUMAз»“жһ„пјҢеҰӮдёӢеӣҫпјҲеӣҫзүҮжқҘиҮӘзҪ‘з»ңпјүжүҖзӨәпјҡ
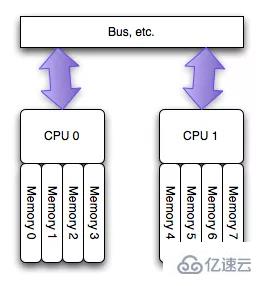
иҝҷз§Қжһ¶жһ„еҸҜд»ҘеҫҲеҘҪи§ЈеҶіUMAзҡ„й—®йўҳпјҢеҚідёҚеҗҢCPUжңүдё“еұһеҶ…еӯҳеҢәпјҢдёәдәҶе®һзҺ°CPUд№Ӣй—ҙзҡ„вҖқеҶ…еӯҳйҡ”зҰ»вҖқпјҢиҝҳйңҖиҰҒиҪҜ件еұӮйқўдёӨзӮ№ж”ҜжҢҒпјҡ
1. еҶ…еӯҳеҲҶй…ҚйңҖиҰҒеңЁиҜ·жұӮзәҝзЁӢеҪ“еүҚжүҖеӨ„CPUзҡ„дё“еұһеҶ…еӯҳеҢәеҹҹиҝӣиЎҢеҲҶй…ҚгҖӮеҰӮжһңеҲҶй…ҚеҲ°е…¶д»–CPUдё“еұһеҶ…еӯҳеҢәпјҢеҠҝеҝ…йҡ”зҰ»жҖ§дјҡеҸ—еҲ°дёҖе®ҡеҪұе“ҚпјҢ并且跨и¶ҠжҖ»зәҝзҡ„еҶ…еӯҳи®ҝй—®жҖ§иғҪеҝ…然дјҡжңүдёҖе®ҡзЁӢеәҰйҷҚдҪҺгҖӮ
2. еҸҰеӨ–пјҢдёҖж—ҰlocalеҶ…еӯҳпјҲдё“еұһеҶ…еӯҳпјүдёҚеӨҹз”ЁпјҢдјҳе…Ҳж·ҳжұ°localеҶ…еӯҳдёӯзҡ„еҶ…еӯҳйЎөпјҢиҖҢдёҚжҳҜеҺ»жҹҘзңӢиҝңзЁӢеҶ…еӯҳеҢәжҳҜеҗҰдјҡжңүз©әй—ІеҶ…еӯҳеҖҹз”ЁгҖӮ
иҝҷж ·е®һзҺ°пјҢйҡ”зҰ»жҖ§зЎ®е®һеҘҪдәҶпјҢдҪҶй—®йўҳд№ҹжқҘдәҶпјҡNUMAиҝҷз§Қзү№жҖ§еҸҜиғҪдјҡеҜјиҮҙCPUеҶ…еӯҳдҪҝз”ЁдёҚеқҮиЎЎпјҢйғЁеҲҶCPUдё“еұһеҶ…еӯҳдёҚеӨҹдҪҝз”ЁпјҢйў‘з№ҒйңҖиҰҒеӣһ收пјҢиҝӣиҖҢеҸҜиғҪеҸ‘з”ҹеӨ§йҮҸswapпјҢзі»з»ҹе“Қеә”延иҝҹдјҡдёҘйҮҚжҠ–еҠЁгҖӮиҖҢдёҺжӯӨеҗҢж—¶е…¶д»–йғЁеҲҶCPUдё“еұһеҶ…еӯҳеҸҜиғҪйғҪеҫҲз©әй—ІгҖӮиҝҷе°ұдјҡдә§з”ҹдёҖз§ҚжҖӘзҺ°иұЎпјҡдҪҝз”Ёfreeе‘Ҫд»ӨжҹҘзңӢеҪ“еүҚзі»з»ҹиҝҳжңүйғЁеҲҶз©әй—Ізү©зҗҶеҶ…еӯҳпјҢзі»з»ҹеҚҙдёҚж–ӯеҸ‘з”ҹswapпјҢеҜјиҮҙжҹҗдәӣеә”з”ЁжҖ§иғҪжҖҘеү§дёӢйҷҚгҖӮи§ҒеҸ¶йҮ‘иҚЈиҖҒеёҲзҡ„MySQLжЎҲдҫӢеҲҶжһҗпјҡгҖҠжүҫеҲ°MySQLжңҚеҠЎеҷЁеҸ‘з”ҹSWAPзҪӘйӯҒзҘёйҰ–гҖӢгҖӮ
жүҖд»ҘпјҢеҜ№дәҺе°ҸеҶ…еӯҳеә”з”ЁжқҘи®ІпјҢNUMAжүҖеёҰжқҘзҡ„иҝҷз§Қй—®йўҳ并дёҚзӘҒеҮәпјҢзӣёеҸҚпјҢlocalеҶ…еӯҳжүҖеёҰжқҘзҡ„жҖ§иғҪжҸҗеҚҮзӣёеҪ“еҸҜи§ӮгҖӮдҪҶжҳҜеҜ№дәҺж•°жҚ®еә“иҝҷзұ»еҶ…еӯҳеӨ§жҲ·жқҘиҜҙпјҢNUMAй»ҳи®Өзӯ–з•ҘжүҖеёҰжқҘзҡ„зЁіе®ҡжҖ§йҡҗжӮЈжҳҜдёҚеҸҜжҺҘеҸ—зҡ„гҖӮеӣ жӯӨж•°жҚ®еә“们йғҪејәзғҲиҰҒжұӮеҜ№NUMAзҡ„й»ҳи®Өзӯ–з•ҘиҝӣиЎҢж”№иҝӣпјҢжңүдёӨдёӘж–№йқўеҸҜд»ҘиҝӣиЎҢж”№иҝӣпјҡ
1. е°ҶеҶ…еӯҳеҲҶй…Қзӯ–з•Ҙз”ұй»ҳи®Өзҡ„дәІе’ҢжЁЎејҸж”№дёәinterleaveжЁЎејҸпјҢеҚідјҡе°ҶеҶ…еӯҳpageжү“ж•ЈеҲҶй…ҚеҲ°дёҚеҗҢзҡ„CPU zoneдёӯгҖӮйҖҡиҝҮиҝҷз§Қж–№ејҸи§ЈеҶіеҶ…еӯҳеҸҜиғҪеҲҶеёғдёҚеқҮзҡ„й—®йўҳпјҢдёҖе®ҡзЁӢеәҰдёҠзј“и§ЈдёҠиҝ°жЎҲдҫӢдёӯзҡ„иҜЎејӮй—®йўҳгҖӮеҜ№дәҺMongoDBжқҘиҜҙпјҢеңЁеҗҜеҠЁзҡ„ж—¶еҖҷе°ұдјҡжҸҗзӨәдҪҝз”ЁinterleaveеҶ…еӯҳеҲҶй…Қзӯ–з•Ҙпјҡ
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl вҖ“interleave=all mongod [other options]
2. ж”№иҝӣеҶ…еӯҳеӣһ收зӯ–з•ҘпјҡжӯӨеӨ„з»ҲдәҺиҜ·еҮәд»ҠеӨ©зҡ„第дёүдёӘдё»и§’еҸӮж•°zone_reclaim_modeпјҢиҝҷдёӘеҸӮж•°е®ҡд№үдәҶNUMAжһ¶жһ„дёӢдёҚеҗҢзҡ„еҶ…еӯҳеӣһ收зӯ–з•ҘпјҢеҸҜд»ҘеҸ–еҖј0/1/3/4пјҢе…¶дёӯ0иЎЁзӨәеңЁlocalеҶ…еӯҳдёҚеӨҹз”Ёзҡ„жғ…еҶөдёӢеҸҜд»ҘеҺ»е…¶д»–зҡ„еҶ…еӯҳеҢәеҹҹеҲҶй…ҚеҶ…еӯҳпјӣ1иЎЁзӨәеңЁlocalеҶ…еӯҳдёҚеӨҹз”Ёзҡ„жғ…еҶөдёӢжң¬ең°е…Ҳеӣһ收еҶҚеҲҶй…Қпјӣ3иЎЁзӨәжң¬ең°еӣһ收е°ҪеҸҜиғҪе…Ҳеӣһ收ж–Ү件缓еӯҳеҜ№иұЎпјӣ4иЎЁзӨәжң¬ең°еӣһ收дјҳе…ҲдҪҝз”Ёswapеӣһ收еҢҝеҗҚеҶ…еӯҳгҖӮеҸҜи§ҒпјҢHBaseжҺЁиҚҗй…ҚзҪ®zone_reclaim_modeпјқ0дёҖе®ҡзЁӢеәҰдёҠйҷҚдҪҺдәҶswapеҸ‘з”ҹзҡ„жҰӮзҺҮгҖӮ
дёҚйғҪжҳҜswapзҡ„дәӢ
иҮіжӯӨпјҢжҲ‘们жҺўи®ЁдәҶдёүдёӘдёҺswapзӣёе…ізҡ„зі»з»ҹеҸӮж•°пјҢ并且еӣҙз»•Linuxзі»з»ҹеҶ…еӯҳеҲҶй…ҚгҖҒswapд»ҘеҸҠNUMAзӯүзҹҘиҜҶзӮ№еҜ№иҝҷдёүдёӘеҸӮж•°иҝӣиЎҢдәҶж·ұе…Ҙи§ЈиҜ»гҖӮйҷӨжӯӨд№ӢеӨ–пјҢеҜ№дәҺж•°жҚ®еә“зі»з»ҹжқҘиҜҙпјҢиҝҳжңүдёӨдёӘйқһеёёйҮҚиҰҒзҡ„еҸӮж•°йңҖиҰҒзү№еҲ«е…іжіЁпјҡ
1. IOи°ғеәҰзӯ–з•ҘпјҡиҝҷдёӘиҜқйўҳзҪ‘дёҠжңүеҫҲеӨҡи§ЈйҮҠпјҢеңЁжӯӨ并дёҚжү“з®—иҜҰиҝ°пјҢеҸӘз»ҷеҮәз»“жһңгҖӮйҖҡеёёеҜ№дәҺsataзӣҳзҡ„OLTPж•°жҚ®еә“жқҘиҜҙпјҢdeadlineз®—жі•и°ғеәҰзӯ–з•ҘжҳҜжңҖдјҳзҡ„йҖүжӢ©гҖӮ
2. THPпјҲtransparent huge pagesпјүзү№жҖ§е…ій—ӯгҖӮTHPзү№жҖ§з¬”иҖ…жӣҫз»Ҹз–‘жғ‘иҝҮеҫҲд№…пјҢдё»иҰҒз–‘жғ‘зӮ№жңүдёӨзӮ№пјҢе…¶дёҖжҳҜTHPе’ҢHugePageжҳҜдёҚжҳҜдёҖеӣһдәӢпјҢе…¶дәҢжҳҜHBaseдёәд»Җд№ҲиҰҒжұӮе…ій—ӯTHPгҖӮз»ҸиҝҮеүҚеүҚеҗҺеҗҺеӨҡж¬ЎжҹҘйҳ…зӣёе…іж–ҮжЎЈпјҢз»ҲдәҺжүҫеҲ°дёҖдәӣиӣӣдёқ马иҝ№гҖӮиҝҷйҮҢеҲҶеӣӣдёӘе°ҸзӮ№жқҘи§ЈйҮҠTHPзү№жҖ§пјҡ
пјҲ1пјүд»Җд№ҲжҳҜHugePageпјҹ
зҪ‘дёҠеҜ№HugePageзҡ„и§ЈйҮҠжңүеҫҲеӨҡпјҢеӨ§е®¶еҸҜд»ҘжЈҖзҙўйҳ…иҜ»гҖӮз®ҖеҚ•жқҘиҜҙпјҢи®Ўз®—жңәеҶ…еӯҳжҳҜйҖҡиҝҮиЎЁжҳ е°„пјҲеҶ…еӯҳзҙўеј•иЎЁпјүзҡ„ж–№ејҸиҝӣиЎҢеҶ…еӯҳеҜ»еқҖпјҢзӣ®еүҚзі»з»ҹеҶ…еӯҳд»Ҙ4KBдёәдёҖдёӘйЎөпјҢдҪңдёәеҶ…еӯҳеҜ»еқҖзҡ„жңҖе°ҸеҚ•е…ғгҖӮйҡҸзқҖеҶ…еӯҳдёҚж–ӯеўһеӨ§пјҢеҶ…еӯҳзҙўеј•иЎЁзҡ„еӨ§е°Ҹе°ҶдјҡдёҚж–ӯеўһеӨ§гҖӮдёҖеҸ°256GеҶ…еӯҳзҡ„жңәеҷЁ,еҰӮжһңдҪҝз”Ё4KBе°ҸйЎө, д»…зҙўеј•иЎЁеӨ§е°Ҹе°ұиҰҒ4Gе·ҰеҸігҖӮиҰҒзҹҘйҒ“иҝҷдёӘзҙўеј•иЎЁжҳҜеҝ…йЎ»иЈ…еңЁеҶ…еӯҳзҡ„пјҢиҖҢдё”жҳҜеңЁCPUеҶ…еӯҳпјҢеӨӘеӨ§е°ұдјҡеҸ‘з”ҹеӨ§йҮҸmissпјҢеҶ…еӯҳеҜ»еқҖжҖ§иғҪе°ұдјҡдёӢйҷҚгҖӮ
HugePageе°ұжҳҜдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢHugePageдҪҝз”Ё2MBеӨ§е°Ҹзҡ„еӨ§йЎөд»Јжӣҝдј з»ҹе°ҸйЎөжқҘз®ЎзҗҶеҶ…еӯҳпјҢиҝҷж ·еҶ…еӯҳзҙўеј•иЎЁеӨ§е°Ҹе°ұеҸҜд»ҘжҺ§еҲ¶зҡ„еҫҲе°ҸпјҢиҝӣиҖҢе…ЁйғЁиЈ…еңЁCPUеҶ…еӯҳпјҢйҳІжӯўеҮәзҺ°missгҖӮ
пјҲ2пјүд»Җд№ҲжҳҜTHPпјҲTransparent Huge Pagesпјү?
HugePageжҳҜдёҖз§ҚеӨ§йЎөзҗҶи®әпјҢйӮЈе…·дҪ“жҖҺд№ҲдҪҝз”ЁHugePageзү№жҖ§е‘ўпјҹзӣ®еүҚзі»з»ҹжҸҗдҫӣдәҶдёӨз§ҚдҪҝз”Ёж–№ејҸпјҢе…¶дёҖз§°дёәStatic Huge PagesпјҢеҸҰдёҖз§Қе°ұжҳҜTransparent Huge PagesгҖӮеүҚиҖ…ж №жҚ®еҗҚз§°е°ұеҸҜд»ҘзҹҘйҒ“жҳҜдёҖз§ҚйқҷжҖҒз®ЎзҗҶзӯ–з•ҘпјҢйңҖиҰҒз”ЁжҲ·иҮӘе·ұж №жҚ®зі»з»ҹеҶ…еӯҳеӨ§е°ҸжүӢеҠЁй…ҚзҪ®еӨ§йЎөдёӘж•°пјҢиҝҷж ·еңЁзі»з»ҹеҗҜеҠЁзҡ„ж—¶еҖҷе°ұдјҡз”ҹжҲҗеҜ№еә”дёӘж•°зҡ„еӨ§йЎөпјҢеҗҺз»ӯе°ҶдёҚеҶҚж”№еҸҳгҖӮиҖҢTransparent Huge PagesжҳҜдёҖз§ҚеҠЁжҖҒз®ЎзҗҶзӯ–з•ҘпјҢе®ғдјҡеңЁиҝҗиЎҢжңҹеҠЁжҖҒеҲҶй…ҚеӨ§йЎөз»ҷеә”з”ЁпјҢ并еҜ№иҝҷдәӣеӨ§йЎөиҝӣиЎҢз®ЎзҗҶпјҢеҜ№з”ЁжҲ·жқҘиҜҙе®Ңе…ЁйҖҸжҳҺпјҢдёҚйңҖиҰҒиҝӣиЎҢд»»дҪ•й…ҚзҪ®гҖӮеҸҰеӨ–пјҢзӣ®еүҚTHPеҸӘй’ҲеҜ№еҢҝеҗҚеҶ…еӯҳеҢәеҹҹгҖӮ
пјҲ3пјүHBaseпјҲж•°жҚ®еә“пјүдёәд»Җд№ҲиҰҒжұӮе…ій—ӯTHPзү№жҖ§пјҹ
THPжҳҜдёҖз§ҚеҠЁжҖҒз®ЎзҗҶзӯ–з•ҘпјҢдјҡеңЁиҝҗиЎҢжңҹеҲҶй…Қз®ЎзҗҶеӨ§йЎөпјҢеӣ жӯӨдјҡжңүдёҖе®ҡзЁӢеәҰзҡ„еҲҶй…Қ延时пјҢиҝҷеҜ№иҝҪжұӮе“Қеә”延时зҡ„ж•°жҚ®еә“зі»з»ҹжқҘиҜҙдёҚеҸҜжҺҘеҸ—гҖӮйҷӨжӯӨд№ӢеӨ–пјҢTHPиҝҳжңүеҫҲеӨҡе…¶д»–ејҠз«ҜпјҢеҸҜд»ҘеҸӮиҖғиҝҷзҜҮж–Үз« гҖҠwhy-tokudb-hates-transparent-hugepagesгҖӢ
пјҲ4пјүTHPе…ій—ӯ/ејҖеҗҜеҜ№HBaseиҜ»еҶҷжҖ§иғҪеҪұе“ҚжңүеӨҡеӨ§пјҹ
дёәдәҶйӘҢиҜҒTHPејҖеҗҜе…ій—ӯеҜ№HBaseжҖ§иғҪзҡ„еҪұе“ҚеҲ°еә•жңүеӨҡеӨ§пјҢжң¬дәәеңЁжөӢиҜ•зҺҜеўғеҒҡдәҶдёҖдёӘз®ҖеҚ•зҡ„жөӢиҜ•пјҡжөӢиҜ•йӣҶзҫӨд»…дёҖдёӘRegionServerпјҢжөӢиҜ•иҙҹиҪҪдёәиҜ»еҶҷжҜ”1:1гҖӮTHPеңЁйғЁеҲҶзі»з»ҹдёӯдёәalwaysд»ҘеҸҠneverдёӨдёӘйҖүйЎ№пјҢеңЁйғЁеҲҶзі»з»ҹдёӯеӨҡдәҶдёҖдёӘз§°дёәmadviseзҡ„йҖүйЎ№гҖӮеҸҜд»ҘдҪҝз”Ёе‘Ҫд»Ө echo never/always > /sys/kernel/mm/transparent_hugepage/enabled жқҘе…ій—ӯ/ејҖеҗҜTHPгҖӮжөӢиҜ•з»“жһңеҰӮдёӢеӣҫжүҖзӨәпјҡ
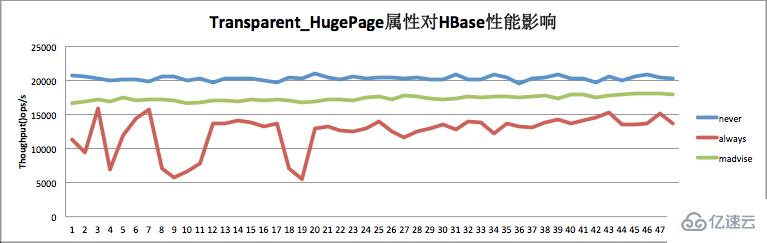
еҰӮдёҠеӣҫпјҢTPHе…ій—ӯеңәжҷҜдёӢпјҲneverпјүHBaseжҖ§иғҪжңҖдјҳпјҢжҜ”иҫғзЁіе®ҡгҖӮиҖҢTHPејҖеҗҜзҡ„еңәжҷҜпјҲalwaysпјүпјҢжҖ§иғҪзӣёжҜ”е…ій—ӯзҡ„еңәжҷҜжңү30%е·ҰеҸізҡ„дёӢйҷҚпјҢиҖҢдё”жӣІзәҝжҠ–еҠЁеҫҲеӨ§гҖӮеҸҜи§ҒпјҢHBaseзәҝдёҠеҲҮи®°иҰҒе…ій—ӯTHPгҖӮ
д»ҘдёҠе°ұжҳҜвҖңlinux swapжҳҜжҖҺд№Ҳи§ҰеҸ‘зҡ„вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





