Python Pandasзҡ„зҹҘиҜҶзӮ№жңүе“Әдәӣ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPython Pandasзҡ„зҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ

дёәд»Җд№ҲиҰҒеӯҰд№ Pandas?
йӮЈд№Ҳй—®йўҳжқҘдәҶпјҡ
numpyе·Із»ҸиғҪеӨҹеё®еҠ©жҲ‘们еӨ„зҗҶж•°жҚ®пјҢиғҪеӨҹз»“еҗҲmatplotlibи§ЈеҶіжҲ‘们数жҚ®еҲҶжһҗзҡ„й—®йўҳпјҢйӮЈд№ҲpandasеӯҰд№ зҡ„зӣ®зҡ„еңЁд»Җд№Ҳең°ж–№е‘ўпјҹ
numpyиғҪеӨҹеё®жҲ‘们еӨ„зҗҶеӨ„зҗҶж•°еҖјеһӢж•°жҚ®пјҢдҪҶжҳҜиҝҷиҝҳдёҚеӨҹпјҢ еҫҲеӨҡж—¶еҖҷпјҢжҲ‘们зҡ„ж•°жҚ®йҷӨдәҶж•°еҖјд№ӢеӨ–пјҢиҝҳжңүеӯ—з¬ҰдёІпјҢиҝҳжңүж—¶й—ҙеәҸеҲ—зӯү
жҜ”еҰӮпјҡжҲ‘们йҖҡиҝҮзҲ¬иҷ«иҺ·еҸ–еҲ°дәҶеӯҳеӮЁеңЁж•°жҚ®еә“дёӯзҡ„ж•°жҚ®
жүҖд»ҘпјҢpandasеҮәзҺ°дәҶгҖӮ
д»Җд№ҲжҳҜPandas?
Pandasзҡ„еҗҚз§°жқҘиҮӘдәҺйқўжқҝж•°жҚ®пјҲpanel dataпјү
PandasжҳҜдёҖдёӘејәеӨ§зҡ„еҲҶжһҗз»“жһ„еҢ–ж•°жҚ®зҡ„е·Ҙе…·йӣҶпјҢеҹәдәҺNumPyжһ„е»әпјҢжҸҗдҫӣдәҶй«ҳзә§ж•°жҚ®з»“жһ„е’Ңж•°жҚ®ж“ҚдҪңе·Ҙе…·пјҢе®ғжҳҜдҪҝPythonжҲҗдёәејәеӨ§иҖҢй«ҳж•Ҳзҡ„ж•°жҚ®еҲҶжһҗзҺҜеўғзҡ„йҮҚиҰҒеӣ зҙ д№ӢдёҖгҖӮ
дёҖдёӘејәеӨ§зҡ„еҲҶжһҗе’Ңж“ҚдҪңеӨ§еһӢз»“жһ„еҢ–ж•°жҚ®йӣҶжүҖйңҖзҡ„е·Ҙе…·йӣҶ
еҹәзЎҖжҳҜNumPyпјҢжҸҗдҫӣдәҶй«ҳжҖ§иғҪзҹ©йҳөзҡ„иҝҗз®—
жҸҗдҫӣдәҶеӨ§йҮҸиғҪеӨҹеҝ«йҖҹдҫҝжҚ·ең°еӨ„зҗҶж•°жҚ®зҡ„еҮҪж•°е’Ңж–№жі•
еә”з”ЁдәҺж•°жҚ®жҢ–жҺҳпјҢж•°жҚ®еҲҶжһҗ
жҸҗдҫӣж•°жҚ®жё…жҙ—еҠҹиғҪ
1. Pandasзҡ„зҙўеј•ж“ҚдҪң
зҙўеј•еҜ№иұЎIndex
1. Seriesе’ҢDataFrameдёӯзҡ„зҙўеј•йғҪжҳҜIndexеҜ№иұЎ
зӨәдҫӢд»Јз Ғпјҡ
print(type(ser_obj.index))print(type(df_obj2.index))print(df_obj2.index)
иҝҗиЎҢз»“жһңпјҡ
<class 'pandas.indexes.range.RangeIndex'>
<class 'pandas.indexes.numeric.Int64Index'>
Int64Index([0, 1, 2, 3], dtype='int64')
2. зҙўеј•еҜ№иұЎдёҚеҸҜеҸҳпјҢдҝқиҜҒдәҶж•°жҚ®зҡ„е®үе…Ё
зӨәдҫӢд»Јз Ғпјҡ
# зҙўеј•еҜ№иұЎдёҚеҸҜеҸҳdf_obj2.index[0] = 2
иҝҗиЎҢз»“жһңпјҡ
---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-23-7f40a356d7d1> in <module>()
1 # зҙўеј•еҜ№иұЎдёҚеҸҜеҸҳ----> 2 df_obj2.index[0] = 2/Users/Power/anaconda/lib/python3.6/site-packages/pandas/indexes/base.py in __setitem__(self, key, value)
1402
1403 def __setitem__(self, key, value):-> 1404 raise TypeError("Index does not support mutable operations")
1405
1406 def __getitem__(self, key):TypeError: Index does not support mutable operations3. еёёи§Ғзҡ„Indexз§Қзұ»
IndexпјҢзҙўеј•
Int64IndexпјҢж•ҙж•°зҙўеј•
MultiIndexпјҢеұӮзә§зҙўеј•
DatetimeIndexпјҢж—¶й—ҙжҲізұ»еһӢ
3.1 Seriesзҙўеј•
1. index жҢҮе®ҡиЎҢзҙўеј•еҗҚ
зӨәдҫӢд»Јз Ғпјҡ
ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e'])print(ser_obj.head())
иҝҗиЎҢз»“жһңпјҡ
a 0
b 1
c 2
d 3
e 4
dtype: int64
2. иЎҢзҙўеј•
ser_obj[вҖҳlabelвҖҷ], ser_obj[pos]
зӨәдҫӢд»Јз Ғпјҡ
# иЎҢзҙўеј•print(ser_obj['b'])print(ser_obj[2])
иҝҗиЎҢз»“жһңпјҡ
1
2
3. еҲҮзүҮзҙўеј•
ser_obj[2:4], ser_obj[вҖҳlabel1вҖҷ: вҖҷlabel3вҖҷ]
жіЁж„ҸпјҢжҢүзҙўеј•еҗҚеҲҮзүҮж“ҚдҪңж—¶пјҢжҳҜеҢ…еҗ«з»Ҳжӯўзҙўеј•зҡ„гҖӮ
зӨәдҫӢд»Јз Ғпјҡ
# еҲҮзүҮзҙўеј•print(ser_obj[1:3])print(ser_obj['b':'d'])
иҝҗиЎҢз»“жһңпјҡ
b 1
c 2
dtype: int64
b 1
c 2
d 3
dtype: int64
4. дёҚиҝһз»ӯзҙўеј•
ser_obj[[вҖҳlabel1вҖҷ, вҖҷlabel2вҖҷ, вҖҳlabel3вҖҷ]]
зӨәдҫӢд»Јз Ғпјҡ
# дёҚиҝһз»ӯзҙўеј•print(ser_obj[[0, 2, 4]])print(ser_obj[['a', 'e']])
иҝҗиЎҢз»“жһңпјҡ
a 0
c 2
e 4
dtype: int64
a 0
e 4
dtype: int64
5. еёғе°”зҙўеј•
зӨәдҫӢд»Јз Ғпјҡ
# еёғе°”зҙўеј•ser_bool = ser_obj > 2print(ser_bool)print(ser_obj[ser_bool])print(ser_obj[ser_obj > 2])
иҝҗиЎҢз»“жһңпјҡ
a False
b False
c False
d True
e True
dtype: bool
d 3
e 4
dtype: int64
d 3
e 4
dtype: int64
3.2 DataFrameзҙўеј•
1. columns жҢҮе®ҡеҲ—зҙўеј•еҗҚ
зӨәдҫӢд»Јз Ғпјҡ
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])print(df_obj.head())
иҝҗиЎҢз»“жһңпјҡ
a b c d
0 -0.241678 0.621589 0.843546 -0.383105
1 -0.526918 -0.485325 1.124420 -0.653144
2 -1.074163 0.939324 -0.309822 -0.209149
3 -0.716816 1.844654 -2.123637 -1.323484
4 0.368212 -0.910324 0.064703 0.486016
2. еҲ—зҙўеј•
df_obj[[вҖҳlabelвҖҷ]]
зӨәдҫӢд»Јз Ғпјҡ
# еҲ—зҙўеј•print(df_obj['a']) # иҝ”еӣһSeriesзұ»еһӢ
иҝҗиЎҢз»“жһңпјҡ
0 -0.241678
1 -0.526918
2 -1.074163
3 -0.716816
4 0.368212
Name: a, dtype: float64
3. дёҚиҝһз»ӯзҙўеј•
df_obj[[вҖҳlabel1вҖҷ, вҖҳlabel2вҖҷ]]
зӨәдҫӢд»Јз Ғпјҡ
# дёҚиҝһз»ӯзҙўеј•print(df_obj[['a','c']])
иҝҗиЎҢз»“жһңпјҡ
a c
0 -0.241678 0.843546
1 -0.526918 1.124420
2 -1.074163 -0.309822
3 -0.716816 -2.123637
4 0.368212 0.064703
4. й«ҳзә§зҙўеј•пјҡж ҮзӯҫгҖҒдҪҚзҪ®е’Ңж··еҗҲ
Pandasзҡ„й«ҳзә§зҙўеј•жңү3з§Қ
1. loc ж Үзӯҫзҙўеј•
DataFrame дёҚиғҪзӣҙжҺҘеҲҮзүҮпјҢеҸҜд»ҘйҖҡиҝҮlocжқҘеҒҡеҲҮзүҮ
locжҳҜеҹәдәҺж ҮзӯҫеҗҚзҡ„зҙўеј•пјҢд№ҹе°ұжҳҜжҲ‘们иҮӘе®ҡд№үзҡ„зҙўеј•еҗҚ
зӨәдҫӢд»Јз Ғпјҡ
# ж Үзӯҫзҙўеј• loc# Seriesprint(ser_obj['b':'d'])print(ser_obj.loc['b':'d'])# DataFrameprint(df_obj['a'])# 第дёҖдёӘеҸӮж•°зҙўеј•иЎҢпјҢ第дәҢдёӘеҸӮж•°жҳҜеҲ—print(df_obj.loc[0:2, 'a'])
иҝҗиЎҢз»“жһңпјҡ
b 1
c 2
d 3
dtype: int64
b 1
c 2
d 3
dtype: int64
0 -0.241678
1 -0.526918
2 -1.074163
3 -0.716816
4 0.368212
Name: a, dtype: float64
0 -0.241678
1 -0.526918
2 -1.074163
Name: a, dtype: float64
2. iloc дҪҚзҪ®зҙўеј•
дҪңз”Ёе’ҢlocдёҖж ·пјҢдёҚиҝҮжҳҜеҹәдәҺзҙўеј•зј–еҸ·жқҘзҙўеј•
зӨәдҫӢд»Јз Ғпјҡ
# ж•ҙеһӢдҪҚзҪ®зҙўеј• iloc# Seriesprint(ser_obj[1:3])print(ser_obj.iloc[1:3])# DataFrameprint(df_obj.iloc[0:2, 0]) # жіЁж„Ҹе’Ңdf_obj.loc[0:2, 'a']зҡ„еҢәеҲ«
иҝҗиЎҢз»“жһңпјҡ
b 1
c 2
dtype: int64
b 1
c 2
dtype: int64
0 -0.241678
1 -0.526918
Name: a, dtype: float64
3. ix ж ҮзӯҫдёҺдҪҚзҪ®ж··еҗҲзҙўеј•
ixжҳҜд»ҘдёҠдәҢиҖ…зҡ„з»јеҗҲпјҢж—ўеҸҜд»ҘдҪҝз”Ёзҙўеј•зј–еҸ·пјҢеҸҲеҸҜд»ҘдҪҝз”ЁиҮӘе®ҡд№үзҙўеј•пјҢиҰҒи§Ҷжғ…еҶөдёҚеҗҢжқҘдҪҝз”ЁпјҢ
еҰӮжһңзҙўеј•ж—ўжңүж•°еӯ—еҸҲжңүиӢұж–ҮпјҢйӮЈд№Ҳиҝҷз§Қж–№ејҸжҳҜдёҚе»әи®®дҪҝз”Ёзҡ„пјҢе®№жҳ“еҜјиҮҙе®ҡдҪҚзҡ„ж··д№ұгҖӮ
зӨәдҫӢд»Јз Ғпјҡ
# ж··еҗҲзҙўеј• ix# Seriesprint(ser_obj.ix[1:3])print(ser_obj.ix['b':'c'])# DataFrameprint(df_obj.loc[0:2, 'a'])print(df_obj.ix[0:2, 0])
иҝҗиЎҢз»“жһңпјҡ
b 1
c 2
dtype: int64
b 1
c 2
dtype: int64
0 -0.241678
1 -0.526918
2 -1.074163
Name: a, dtype: float64
жіЁж„Ҹ
DataFrameзҙўеј•ж“ҚдҪңпјҢеҸҜе°Ҷе…¶зңӢдҪңndarrayзҡ„зҙўеј•ж“ҚдҪң
ж Үзӯҫзҡ„еҲҮзүҮзҙўеј•жҳҜеҢ…еҗ«жң«е°ҫдҪҚзҪ®зҡ„
2. Pandasзҡ„еҜ№йҪҗиҝҗз®—
Pandasзҡ„еҜ№йҪҗиҝҗз®—жҳҜж•°жҚ®жё…жҙ—зҡ„йҮҚиҰҒиҝҮзЁӢпјҢеҸҜд»ҘжҢүзҙўеј•еҜ№йҪҗиҝӣиЎҢиҝҗз®—пјҢеҰӮжһңжІЎеҜ№йҪҗзҡ„дҪҚзҪ®еҲҷиЎҘNaNпјҢжңҖеҗҺд№ҹеҸҜд»ҘеЎ«е……NaN
2.1 Seriesзҡ„еҜ№йҪҗиҝҗз®—
1. Series жҢүиЎҢгҖҒзҙўеј•еҜ№йҪҗ
зӨәдҫӢд»Јз Ғпјҡ
s1 = pd.Series(range(10, 20), index = range(10))s2 = pd.Series(range(20, 25), index = range(5))print('s1: ' )print(s1)print('') print('s2: ')print(s2)иҝҗиЎҢз»“жһңпјҡ
s1:
0 10
1 11
2 12
3 13
4 14
5 15
6 16
7 17
8 18
9 19
dtype: int64
s2:
0 20
1 21
2 22
3 23
4 24
dtype: int64
2. Seriesзҡ„еҜ№йҪҗиҝҗз®—
зӨәдҫӢд»Јз Ғпјҡ
# Series еҜ№йҪҗиҝҗз®—s1 + s2
иҝҗиЎҢз»“жһңпјҡ
0 30.0
1 32.0
2 34.0
3 36.0
4 38.0
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
dtype: float64
2.2 DataFrameзҡ„еҜ№йҪҗиҝҗз®—
1. DataFrameжҢүиЎҢгҖҒеҲ—зҙўеј•еҜ№йҪҗ
зӨәдҫӢд»Јз Ғпјҡ
df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b'])df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c'])print('df1: ')print(df1)print('') print('df2: ')print(df2)иҝҗиЎҢз»“жһңпјҡ
df1:
a b
0 1.0 1.0
1 1.0 1.0
df2:
a b c
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
2. DataFrameзҡ„еҜ№йҪҗиҝҗз®—
зӨәдҫӢд»Јз Ғпјҡ
# DataFrameеҜ№йҪҗж“ҚдҪңdf1 + df2
иҝҗиЎҢз»“жһңпјҡ
a b c0 2.0 2.0 NaN1 2.0 2.0 NaN2 NaN NaN NaN
2.3 еЎ«е……жңӘеҜ№йҪҗзҡ„ж•°жҚ®иҝӣиЎҢиҝҗз®—
fill_value
дҪҝз”Ёadd,sub,p,mulзҡ„еҗҢж—¶пјҢ
йҖҡиҝҮfill_valueжҢҮе®ҡеЎ«е……еҖјпјҢжңӘеҜ№йҪҗзҡ„ж•°жҚ®е°Ҷе’ҢеЎ«е……еҖјеҒҡиҝҗз®—
зӨәдҫӢд»Јз Ғпјҡ
print(s1)print(s2)s1.add(s2, fill_value = -1)print(df1)print(df2)df1.sub(df2, fill_value = 2.)
иҝҗиЎҢз»“жһңпјҡ
# print(s1)0 101 112 123 134 145 156 167 178 189 19dtype: int64# print(s2)0 201 212 223 234 24dtype: int64# s1.add(s2, fill_value = -1)0 30.01 32.02 34.03 36.04 38.05 14.06 15.07 16.08 17.09 18.0dtype: float64# print(df1)
a b0 1.0 1.01 1.0 1.0# print(df2)
a b c0 1.0 1.0 1.01 1.0 1.0 1.02 1.0 1.0 1.0# df1.sub(df2, fill_value = 2.)
a b c0 0.0 0.0 1.01 0.0 0.0 1.02 1.0 1.0 1.0
з®—жңҜж–№жі•иЎЁ:
| ж–№жі• | жҸҸиҝ° |
|---|
| addпјҢradd | еҠ жі•пјҲ+пјү |
| subпјҢrsub | еҮҸжі•пјҲ-пјү |
| pпјҢrp | йҷӨжі•пјҲ/пјү |
| floorpпјҢrfllorp | ж•ҙйҷӨпјҲ//пјү |
| mulпјҢrmul | д№ҳжі•пјҲ*пјү |
| powпјҢrpow | е№Ӯж¬Ўж–№пјҲ**пјү |
3. Pandasзҡ„еҮҪж•°еә”з”Ё
3.1 apply е’Ң applymap
1. еҸҜзӣҙжҺҘдҪҝз”ЁNumPyзҡ„еҮҪж•°
зӨәдҫӢд»Јз Ғпјҡ
# Numpy ufunc еҮҪж•°df = pd.DataFrame(np.random.randn(5,4) - 1)print(df)print(np.abs(df))
иҝҗиЎҢз»“жһңпјҡ
0 1 2 3
0 -0.062413 0.844813 -1.853721 -1.980717
1 -0.539628 -1.975173 -0.856597 -2.612406
2 -1.277081 -1.088457 -0.152189 0.530325
3 -1.356578 -1.996441 0.368822 -2.211478
4 -0.562777 0.518648 -2.007223 0.059411
0 1 2 3
0 0.062413 0.844813 1.853721 1.980717
1 0.539628 1.975173 0.856597 2.612406
2 1.277081 1.088457 0.152189 0.530325
3 1.356578 1.996441 0.368822 2.211478
4 0.562777 0.518648 2.007223 0.059411
2. йҖҡиҝҮapplyе°ҶеҮҪж•°еә”з”ЁеҲ°еҲ—жҲ–иЎҢдёҠ
зӨәдҫӢд»Јз Ғпјҡ
# дҪҝз”Ёapplyеә”з”ЁиЎҢжҲ–еҲ—ж•°жҚ®#f = lambda x : x.max()print(df.apply(lambda x : x.max()))
иҝҗиЎҢз»“жһңпјҡ
0 -0.062413
1 0.844813
2 0.368822
3 0.530325
dtype: float64
жіЁж„ҸжҢҮе®ҡиҪҙзҡ„ж–№еҗ‘пјҢй»ҳи®Өaxis=0пјҢж–№еҗ‘жҳҜеҲ—
зӨәдҫӢд»Јз Ғпјҡ
# жҢҮе®ҡиҪҙж–№еҗ‘пјҢaxis=1пјҢж–№еҗ‘жҳҜиЎҢprint(df.apply(lambda x : x.max(), axis=1))
иҝҗиЎҢз»“жһңпјҡ
0 0.844813
1 -0.539628
2 0.530325
3 0.368822
4 0.518648
dtype: float64
3. йҖҡиҝҮapplymapе°ҶеҮҪж•°еә”з”ЁеҲ°жҜҸдёӘж•°жҚ®дёҠ
зӨәдҫӢд»Јз Ғпјҡ
# дҪҝз”Ёapplymapеә”з”ЁеҲ°жҜҸдёӘж•°жҚ®f2 = lambda x : '%.2f' % xprint(df.applymap(f2))
иҝҗиЎҢз»“жһңпјҡ
0 1 2 3
0 -0.06 0.84 -1.85 -1.98
1 -0.54 -1.98 -0.86 -2.61
2 -1.28 -1.09 -0.15 0.53
3 -1.36 -2.00 0.37 -2.21
4 -0.56 0.52 -2.01 0.06
3.2 жҺ’еәҸ
1. зҙўеј•жҺ’еәҸ
sort_index()
жҺ’еәҸй»ҳи®ӨдҪҝз”ЁеҚҮеәҸжҺ’еәҸпјҢascending=False дёәйҷҚеәҸжҺ’еәҸ
зӨәдҫӢд»Јз Ғпјҡ
# Seriess4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5))print(s4)# зҙўеј•жҺ’еәҸs4.sort_index() # 0 0 1 3 3
иҝҗиЎҢз»“жһңпјҡ
0 10
3 11
1 12
3 13
0 14
dtype: int64
0 10
0 14
1 12
3 11
3 13
dtype: int64
еҜ№DataFrameж“ҚдҪңж—¶жіЁж„ҸиҪҙж–№еҗ‘
зӨәдҫӢд»Јз Ғпјҡ
# DataFramedf4 = pd.DataFrame(np.random.randn(3, 5),
index=np.random.randint(3, size=3),
columns=np.random.randint(5, size=5))print(df4)df4_isort = df4.sort_index(axis=1, ascending=False)print(df4_isort) # 4 2 1 1 0
иҝҗиЎҢз»“жһңпјҡ
1 4 0 1 2
2 -0.416686 -0.161256 0.088802 -0.004294 1.164138
1 -0.671914 0.531256 0.303222 -0.509493 -0.342573
1 1.988321 -0.466987 2.787891 -1.105912 0.889082
4 2 1 1 0
2 -0.161256 1.164138 -0.416686 -0.004294 0.088802
1 0.531256 -0.342573 -0.671914 -0.509493 0.303222
1 -0.466987 0.889082 1.988321 -1.105912 2.787891
2. жҢүеҖјжҺ’еәҸ
sort_values(by=вҖҳcolumn nameвҖҷ)
ж №жҚ®жҹҗдёӘе”ҜдёҖзҡ„еҲ—еҗҚиҝӣиЎҢжҺ’еәҸпјҢеҰӮжһңжңүе…¶д»–зӣёеҗҢеҲ—еҗҚеҲҷжҠҘй”ҷгҖӮ
зӨәдҫӢд»Јз Ғпјҡ
# жҢүеҖјжҺ’еәҸdf4_vsort = df4.sort_values(by=0, ascending=False)print(df4_vsort)
иҝҗиЎҢз»“жһңпјҡ
1 4 0 1 2
1 1.988321 -0.466987 2.787891 -1.105912 0.889082
1 -0.671914 0.531256 0.303222 -0.509493 -0.342573
2 -0.416686 -0.161256 0.088802 -0.004294 1.164138
3.3 еӨ„зҗҶзјәеӨұж•°жҚ®
зӨәдҫӢд»Јз Ғпјҡ
df_data = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],
[np.nan, 4., np.nan], [1., 2., 3.]])print(df_data.head())
иҝҗиЎҢз»“жһңпјҡ
0 1 2
0 -0.281885 -0.786572 0.487126
1 1.000000 2.000000 NaN
2 NaN 4.000000 NaN
3 1.000000 2.000000 3.000000
1. еҲӨж–ӯжҳҜеҗҰеӯҳеңЁзјәеӨұеҖјпјҡisnull()
зӨәдҫӢд»Јз Ғпјҡ
# isnullprint(df_data.isnull())
иҝҗиЎҢз»“жһңпјҡ
0 1 2
0 False False False
1 False False True
2 True False True
3 False False False
2. дёўејғзјәеӨұж•°жҚ®пјҡdropna()
ж №жҚ®axisиҪҙж–№еҗ‘пјҢдёўејғеҢ…еҗ«NaNзҡ„иЎҢжҲ–еҲ—гҖӮ зӨәдҫӢд»Јз Ғпјҡ
# dropnaprint(df_data.dropna()) # й»ҳи®ӨжҳҜжҢүиЎҢprint(df_data.dropna(axis=1)) # axis=1жҳҜжҢүеҲ—
иҝҗиЎҢз»“жһңпјҡ
0 1 2
0 -0.281885 -0.786572 0.487126
3 1.000000 2.000000 3.000000
1
0 -0.786572
1 2.000000
2 4.000000
3 2.000000
3. еЎ«е……зјәеӨұж•°жҚ®пјҡfillna()
зӨәдҫӢд»Јз Ғпјҡ
# fillnaprint(df_data.fillna(-100.))
иҝҗиЎҢз»“жһңпјҡ
0 1 2
0 -0.281885 -0.786572 0.487126
1 1.000000 2.000000 -100.000000
2 -100.000000 4.000000 -100.000000
3 1.000000 2.000000 3.000000
4. еұӮзә§зҙўеј•пјҲhierarchical indexingпјү
дёӢйқўеҲӣе»әдёҖдёӘSeriesпјҢ еңЁиҫ“е…Ҙзҙўеј•Indexж—¶пјҢиҫ“е…ҘдәҶз”ұдёӨдёӘеӯҗlistз»„жҲҗзҡ„listпјҢ第дёҖдёӘеӯҗlistжҳҜеӨ–еұӮзҙўеј•пјҢ第дәҢдёӘlistжҳҜеҶ…еұӮзҙўеј•гҖӮ
зӨәдҫӢд»Јз Ғпјҡ
import pandas as pdimport numpy as np
ser_obj = pd.Series(np.random.randn(12),index=[
['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c', 'd', 'd', 'd'],
[0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]
])print(ser_obj)
иҝҗиЎҢз»“жһңпјҡ
a 0 0.099174
1 -0.310414
2 -0.558047
b 0 1.742445
1 1.152924
2 -0.725332
c 0 -0.150638
1 0.251660
2 0.063387
d 0 1.080605
1 0.567547
2 -0.154148
dtype: float64
4.1 MultiIndexзҙўеј•еҜ№иұЎ
жү“еҚ°иҝҷдёӘSeriesзҡ„зҙўеј•зұ»еһӢпјҢжҳҫзӨәжҳҜMultiIndex
зӣҙжҺҘе°Ҷзҙўеј•жү“еҚ°еҮәжқҘпјҢеҸҜд»ҘзңӢеҲ°жңүlavels,е’ҢlabelsдёӨдёӘдҝЎжҒҜгҖӮlevelsиЎЁзӨәдёӨдёӘеұӮзә§дёӯеҲҶеҲ«жңүйӮЈдәӣж ҮзӯҫпјҢlabelsжҳҜжҜҸдёӘдҪҚзҪ®еҲҶеҲ«жҳҜд»Җд№Ҳж ҮзӯҫгҖӮ
зӨәдҫӢд»Јз Ғпјҡ
print(type(ser_obj.index))print(ser_obj.index)
иҝҗиЎҢз»“жһңпјҡ
<class 'pandas.indexes.multi.MultiIndex'>MultiIndex(levels=[['a', 'b', 'c', 'd'], [0, 1, 2]],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 2, 0, 1, 2]])
4.2 йҖүеҸ–еӯҗйӣҶ
ж №жҚ®зҙўеј•иҺ·еҸ–ж•°жҚ®гҖӮеӣ дёәзҺ°еңЁжңүдёӨеұӮзҙўеј•пјҢеҪ“йҖҡиҝҮеӨ–еұӮзҙўеј•иҺ·еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢеҸҜд»ҘзӣҙжҺҘеҲ©з”ЁеӨ–еұӮзҙўеј•зҡ„ж ҮзӯҫжқҘиҺ·еҸ–гҖӮ
еҪ“иҰҒйҖҡиҝҮеҶ…еұӮзҙўеј•иҺ·еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢеңЁlistдёӯдј е…ҘдёӨдёӘе…ғзҙ пјҢеүҚиҖ…жҳҜиЎЁзӨәиҰҒйҖүеҸ–зҡ„еӨ–еұӮзҙўеј•пјҢеҗҺиҖ…иЎЁзӨәиҰҒйҖүеҸ–зҡ„еҶ…еұӮзҙўеј•гҖӮ
1. еӨ–еұӮйҖүеҸ–пјҡ
ser_obj[вҖҳouter_labelвҖҷ]
зӨәдҫӢд»Јз Ғпјҡ
# еӨ–еұӮйҖүеҸ–print(ser_obj['c'])
иҝҗиЎҢз»“жһңпјҡ
0 -1.362096
1 1.558091
2 -0.452313
dtype: float64
2. еҶ…еұӮйҖүеҸ–пјҡ
ser_obj[:, вҖҳinner_labelвҖҷ]
зӨәдҫӢд»Јз Ғпјҡ
# еҶ…еұӮйҖүеҸ–print(ser_obj[:, 2])
иҝҗиЎҢз»“жһңпјҡ
a 0.826662
b 0.015426
c -0.452313
d -0.051063
dtype: float64
еёёз”ЁдәҺеҲҶз»„ж“ҚдҪңгҖҒйҖҸи§ҶиЎЁзҡ„з”ҹжҲҗзӯү
4.2 дәӨжҚўеҲҶеұӮйЎәеәҸ
swaplevel()
.swaplevel( )дәӨжҚўеҶ…еұӮдёҺеӨ–еұӮзҙўеј•гҖӮ
зӨәдҫӢд»Јз Ғпјҡ
print(ser_obj.swaplevel())
иҝҗиЎҢз»“жһңпјҡ
0 a 0.099174
1 a -0.310414
2 a -0.558047
0 b 1.742445
1 b 1.152924
2 b -0.725332
0 c -0.150638
1 c 0.251660
2 c 0.063387
0 d 1.080605
1 d 0.567547
2 d -0.154148
dtype: float64
4.3 дәӨжҚўе№¶жҺ’еәҸеҲҶеұӮ
sortlevel()
.sortlevel( )е…ҲеҜ№еӨ–еұӮзҙўеј•иҝӣиЎҢжҺ’еәҸпјҢеҶҚеҜ№еҶ…еұӮзҙўеј•иҝӣиЎҢжҺ’еәҸпјҢй»ҳи®ӨжҳҜеҚҮеәҸгҖӮ
зӨәдҫӢд»Јз Ғпјҡ
# дәӨжҚўе№¶жҺ’еәҸеҲҶеұӮprint(ser_obj.swaplevel().sortlevel())
иҝҗиЎҢз»“жһңпјҡ
0 a 0.099174
b 1.742445
c -0.150638
d 1.080605
1 a -0.310414
b 1.152924
c 0.251660
d 0.567547
2 a -0.558047
b -0.725332
c 0.063387
d -0.154148
dtype: float64
5. Pandasз»ҹи®Ўи®Ўз®—е’ҢжҸҸиҝ°
зӨәдҫӢд»Јз Ғпјҡ
arr1 = np.random.rand(4,3)pd1 = pd.DataFrame(arr1,columns=list('ABC'),index=list('abcd'))f = lambda x: '%.2f'% x
pd2 = pd1.applymap(f).astype(float)pd2иҝҗиЎҢз»“жһңпјҡ
A B C
a 0.87 0.26 0.67
b 0.69 0.89 0.17
c 0.94 0.33 0.04
d 0.35 0.46 0.29
5.1 еёёз”Ёзҡ„з»ҹи®Ўи®Ўз®—
sum, mean, max, minвҖҰ
axis=0 жҢүеҲ—з»ҹи®ЎпјҢaxis=1жҢүиЎҢз»ҹи®Ў
skipna жҺ’йҷӨзјәеӨұеҖјпјҢ й»ҳи®ӨдёәTrue
зӨәдҫӢд»Јз Ғпјҡ
pd2.sum() #й»ҳи®ӨжҠҠиҝҷдёҖеҲ—зҡ„Seriesи®Ўз®—,жүҖжңүиЎҢжұӮе’Ңpd2.sum(axis='columns') #жҢҮе®ҡжұӮжҜҸдёҖиЎҢзҡ„жүҖжңүеҲ—зҡ„е’Ңpd2.idxmax()#жҹҘзңӢжҜҸдёҖеҲ—жүҖжңүиЎҢзҡ„жңҖеӨ§еҖјжүҖеңЁзҡ„ж Үзӯҫзҙўеј•пјҢеҗҢж ·жҲ‘们д№ҹеҸҜд»ҘйҖҡиҝҮaxis='columns'жұӮжҜҸдёҖиЎҢжүҖжңүеҲ—зҡ„жңҖеӨ§еҖјзҡ„ж Үзӯҫзҙўеј•
иҝҗиЎҢз»“жһңпјҡ
A 2.85
B 1.94
C 1.17
dtype: float64
a 1.80
b 1.75
c 1.31
d 1.10
dtype: float64
A c
B b
C a
dtype: object

5.2 еёёз”Ёзҡ„з»ҹи®ЎжҸҸиҝ°
describe дә§з”ҹеӨҡдёӘз»ҹи®Ўж•°жҚ®
зӨәдҫӢд»Јз Ғпјҡ
pd2.describe()#жҹҘзңӢжұҮжҖ»
иҝҗиЎҢз»“жһңпјҡ
A B C
count 4.000000 4.00000 4.000000mean 0.712500 0.48500 0.292500std 0.263613 0.28243 0.271585min 0.350000 0.26000 0.04000025% 0.605000 0.31250 0.13750050% 0.780000 0.39500 0.23000075% 0.887500 0.56750 0.385000max 0.940000 0.89000 0.670000
#зҷҫеҲҶжҜ”:йҷӨд»ҘеҺҹжқҘзҡ„йҮҸpd2.pct_change() #жҹҘзңӢиЎҢзҡ„зҷҫеҲҶжҜ”еҸҳеҢ–пјҢеҗҢж ·жҢҮе®ҡaxis='columns'еҲ—дёҺеҲ—зҡ„зҷҫеҲҶжҜ”еҸҳеҢ–
A B C
a NaN NaN NaN
b -0.206897 2.423077 -0.746269c 0.362319 -0.629213 -0.764706d -0.627660 0.393939 6.250000
5.3 еёёз”Ёзҡ„з»ҹи®ЎжҸҸиҝ°ж–№жі•

6. ж•°жҚ®иҜ»еҸ–дёҺеӯҳеӮЁ
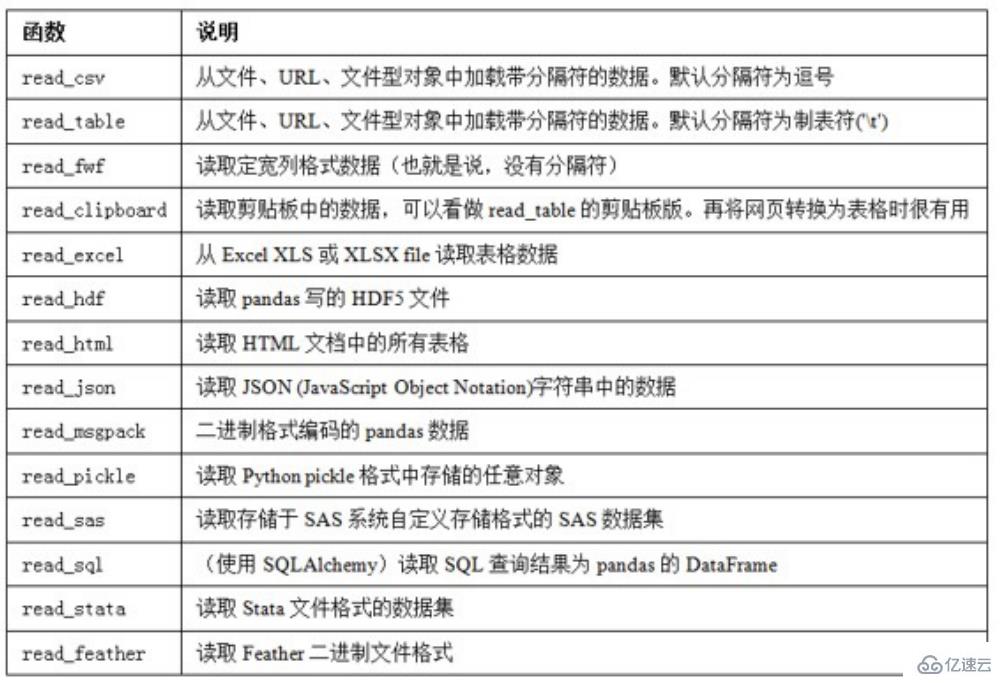
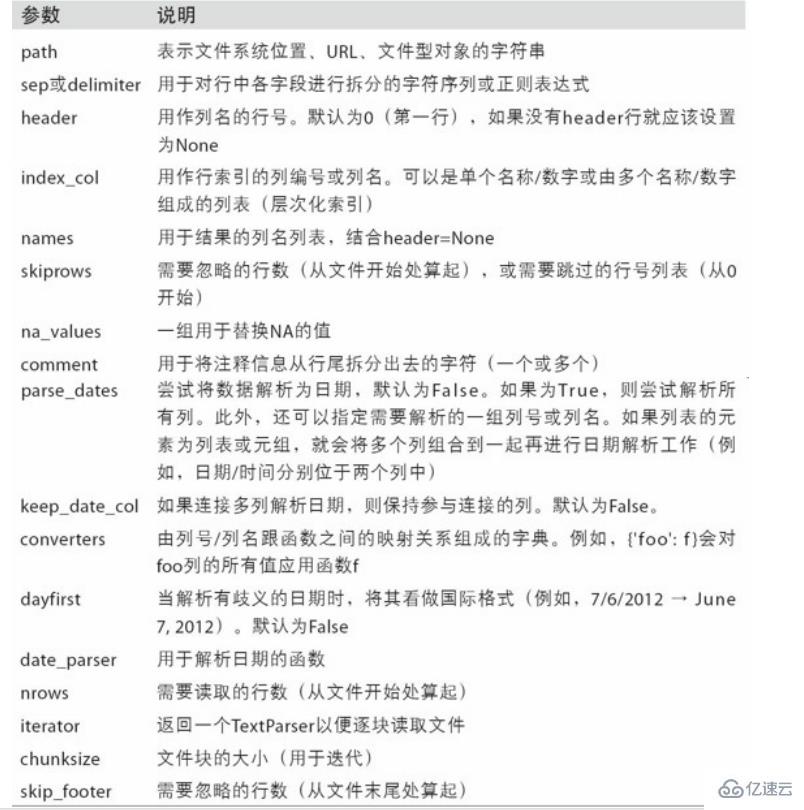
6.1 csvж–Ү件
иҜ»еҸ–csvж–Ү件read_csv(file_path or buf,usecols,encoding):file_pathпјҡж–Ү件и·Ҝеҫ„,usecols:жҢҮе®ҡиҜ»еҸ–зҡ„еҲ—еҗҚпјҢencoding:зј–з Ғ
data = pd.read_csv('d:/test_data/food_rank.csv',encoding='utf8')data.head()
name num0 й…ҘжІ№иҢ¶ 219.01 йқ’зЁһй…’ 95.02 й…ёеҘ¶ 62.03 зіҢзІ‘ 16.04 зҗөзҗ¶иӮү 2.0#жҢҮе®ҡиҜ»еҸ–зҡ„еҲ—еҗҚdata = pd.read_csv('d:/test_data/food_rank.csv',usecols=['name'])data.head()
name0 й…ҘжІ№иҢ¶1 йқ’зЁһй…’2 й…ёеҘ¶3 зіҢзІ‘4 зҗөзҗ¶иӮү#еҰӮжһңж–Ү件и·Ҝеҫ„жңүдёӯж–ҮпјҢеҲҷйңҖиҰҒзҹҘйҒ“еҸӮж•°engine='python'data = pd.read_csv('d:/ж•°жҚ®/food_rank.csv',engine='python',encoding='utf8')data.head()
name num0 й…ҘжІ№иҢ¶ 219.01 йқ’зЁһй…’ 95.02 й…ёеҘ¶ 62.03 зіҢзІ‘ 16.04 зҗөзҗ¶иӮү 2.0#е»әи®®ж–Ү件и·Ҝеҫ„е’Ңж–Ү件еҗҚпјҢдёҚиҰҒеҮәзҺ°дёӯж–ҮеҶҷе…Ҙcsvж–Ү件
DataFrame:to_csv(file_path or buf,sep,columns,header,index,na_rep,mode)пјҡfile_pathпјҡдҝқеӯҳж–Ү件и·Ҝеҫ„,й»ҳи®ӨNone,sep:еҲҶйҡ”з¬Ұ,й»ҳи®ӨвҖҷ,вҖҷ ,columns:жҳҜеҗҰдҝқз•ҷжҹҗеҲ—ж•°жҚ®,й»ҳи®ӨNone,headerпјҡжҳҜеҗҰдҝқз•ҷеҲ—еҗҚ,й»ҳи®ӨTrue,index:жҳҜеҗҰдҝқз•ҷиЎҢзҙўеј•,й»ҳи®ӨTrue,na_rep:жҢҮе®ҡеӯ—з¬ҰдёІжқҘд»Јжӣҝз©әеҖј,й»ҳи®ӨжҳҜз©әеӯ—з¬Ұ,mode:й»ҳи®ӨвҖҷwвҖҷ,иҝҪеҠ вҖҷaвҖҷ
**Series**:`Series.to_csv`\ (_path=None_,_index=True_,_sep='_,_'_,_na\_rep=''_,_header=False_,_mode='w'_,_encoding=None_\)
6.2 ж•°жҚ®еә“дәӨдә’
# еҜје…Ҙеҝ…иҰҒжЁЎеқ—import pandas as pdfrom sqlalchemy import create_engine#еҲқе§ӢеҢ–ж•°жҚ®еә“иҝһжҺҘ#з”ЁжҲ·еҗҚroot еҜҶз Ғ з«ҜеҸЈ 3306 ж•°жҚ®еә“ db2engine = create_engine('mysql+pymysql://root:@localhost:3306/db2')#жҹҘиҜўиҜӯеҸҘsql = '''
select * from class;
'''#дёӨдёӘеҸӮж•° sqlиҜӯеҸҘ ж•°жҚ®еә“иҝһжҺҘdf = pd.read_sql(sql,engine)df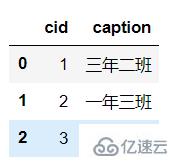
#ж–°е»әdf = pd.DataFrame({'id':[1,2,3,4],'num':[34,56,78,90]})df = pd.read_csv('ex1.csv')# #еҶҷе…ҘеҲ°ж•°жҚ®еә“df.to_sql('df2',engine,index=False)print("ok")иҝӣе…Ҙж•°жҚ®еә“жҹҘзңӢ
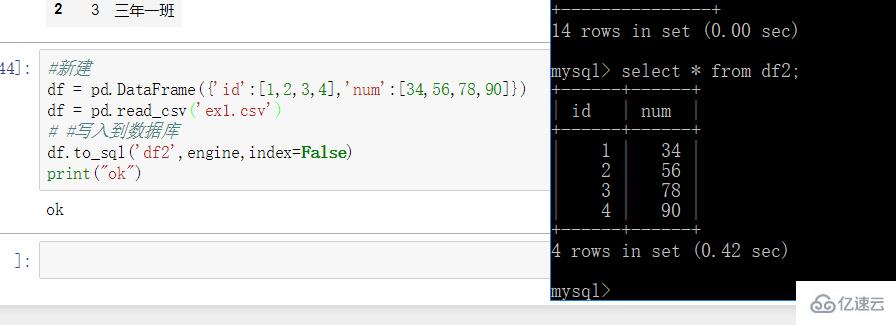
7. ж•°жҚ®жё…жҙ—
7.1 ж•°жҚ®жё…жҙ—е’ҢеҮҶеӨҮ
ж•°жҚ®жё…жҙ—жҳҜж•°жҚ®еҲҶжһҗе…ій”®зҡ„дёҖжӯҘпјҢзӣҙжҺҘеҪұе“Қд№ӢеҗҺзҡ„еӨ„зҗҶе·ҘдҪң
ж•°жҚ®йңҖиҰҒдҝ®ж”№еҗ—пјҹжңүд»Җд№ҲйңҖиҰҒдҝ®ж”№зҡ„еҗ—пјҹж•°жҚ®еә”иҜҘжҖҺд№Ҳи°ғж•ҙжүҚиғҪйҖӮз”ЁдәҺжҺҘдёӢжқҘзҡ„еҲҶжһҗе’ҢжҢ–жҺҳпјҹ
жҳҜдёҖдёӘиҝӯд»Јзҡ„иҝҮзЁӢпјҢе®һйҷ…йЎ№зӣ®дёӯеҸҜиғҪйңҖиҰҒдёҚжӯўдёҖж¬Ўең°жү§иЎҢиҝҷдәӣжё…жҙ—ж“ҚдҪң
1. еӨ„зҗҶзјәеӨұж•°жҚ®

2. ж•°жҚ®иҪ¬жҚў
2.1 еӨ„зҗҶйҮҚеӨҚж•°жҚ®
2.2 duplicated()жҳҜеҗҰдёәйҮҚеӨҚиЎҢ
duplicated\(\): иҝ”еӣһеёғе°”еһӢSeriesиЎЁзӨәжҜҸиЎҢжҳҜеҗҰдёәйҮҚеӨҚиЎҢ
зӨәдҫӢд»Јз Ғпјҡ
import numpy as npimport pandas as pd
df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,
'data2' : np.random.randint(0, 4, 8)})print(df_obj)print(df_obj.duplicated())иҝҗиЎҢз»“жһңпјҡ
# print(df_obj)
data1 data20 a 31 a 22 a 33 a 34 b 15 b 06 b 37 b 0# print(df_obj.duplicated())0 False1 False2 True3 True4 False5 False6 False7 Truedtype: bool
2.4 drop_duplicates()иҝҮж»ӨйҮҚеӨҚиЎҢ
зӨәдҫӢд»Јз Ғпјҡ
print(df_obj.drop_duplicates())print(df_obj.drop_duplicates('data2'))иҝҗиЎҢз»“жһңпјҡ
# print(df_obj.drop_duplicates())
data1 data20 a 31 a 24 b 15 b 06 b 3# print(df_obj.drop_duplicates('data2'))
data1 data20 a 31 a 24 b 15 b 02.5 еҲ©з”ЁеҮҪж•°жҲ–жҳ е°„иҝӣиЎҢж•°жҚ®иҪ¬жҚў
ж №жҚ®mapдј е…Ҙзҡ„еҮҪж•°еҜ№жҜҸиЎҢжҲ–жҜҸеҲ—иҝӣиЎҢиҪ¬жҚў
зӨәдҫӢд»Јз Ғпјҡ
ser_obj = pd.Series(np.random.randint(0,10,10))print(ser_obj)print(ser_obj.map(lambda x : x ** 2))
иҝҗиЎҢз»“жһңпјҡ
# print(ser_obj)0 11 42 83 64 85 66 67 48 79 3dtype: int64# print(ser_obj.map(lambda x : x ** 2))0 11 162 643 364 645 366 367 168 499 9dtype: int64
2.6 жӣҝжҚўеҖј
replaceж №жҚ®еҖјзҡ„еҶ…е®№иҝӣиЎҢжӣҝжҚў
зӨәдҫӢд»Јз Ғпјҡ
# еҚ•дёӘеҖјжӣҝжҚўеҚ•дёӘеҖјprint(ser_obj.replace(1, -100))# еӨҡдёӘеҖјжӣҝжҚўдёҖдёӘеҖјprint(ser_obj.replace([6, 8], -100))# еӨҡдёӘеҖјжӣҝжҚўеӨҡдёӘеҖјprint(ser_obj.replace([4, 7], [-100, -200]))
иҝҗиЎҢз»“жһңпјҡ
# print(ser_obj.replace(1, -100))0 -1001 42 83 64 85 66 67 48 79 3dtype: int64# print(ser_obj.replace([6, 8], -100))0 11 42 -1003 -1004 -1005 -1006 -1007 48 79 3dtype: int64# print(ser_obj.replace([4, 7], [-100, -200]))0 11 -1002 83 64 85 66 67 -1008 -2009 3dtype: int64
3. еӯ—з¬ҰдёІж“ҚдҪң
3.1 еӯ—з¬ҰдёІж–№жі•


3.2 жӯЈеҲҷиЎЁиҫҫејҸж–№жі•

3.3 pandasеӯ—з¬ҰдёІеҮҪж•°

7.2 ж•°жҚ®еҗҲ并
1. ж•°жҚ®еҗҲ并(pd.merge)
ж №жҚ®еҚ•дёӘжҲ–еӨҡдёӘй”®е°ҶдёҚеҗҢDataFrameзҡ„иЎҢиҝһжҺҘиө·жқҘ
зұ»дјјж•°жҚ®еә“зҡ„иҝһжҺҘж“ҚдҪң
pd.merge:(left, right, how=вҖҳinnerвҖҷ,on=None,left_on=None, right_on=None )
left:еҗҲ并时е·Ұиҫ№зҡ„DataFrame
right:еҗҲ并时еҸіиҫ№зҡ„DataFrame
how:еҗҲ并зҡ„ж–№ејҸ,й»ҳи®ӨвҖҷinnerвҖҷ, вҖҳouterвҖҷ, вҖҳleftвҖҷ, вҖҳrightвҖҷ
on:йңҖиҰҒеҗҲ并зҡ„еҲ—еҗҚ,еҝ…йЎ»дёӨиҫ№йғҪжңүзҡ„еҲ—еҗҚпјҢ并д»Ҙ left е’Ң right дёӯзҡ„еҲ—еҗҚзҡ„дәӨйӣҶдҪңдёәиҝһжҺҘй”®
left_on: left Dataframeдёӯз”ЁдҪңиҝһжҺҘй”®зҡ„еҲ—
right_on: right Dataframeдёӯз”ЁдҪңиҝһжҺҘй”®зҡ„еҲ—
еҶ…иҝһжҺҘ inner:еҜ№дёӨеј иЎЁйғҪжңүзҡ„й”®зҡ„дәӨйӣҶиҝӣиЎҢиҒ”еҗҲ
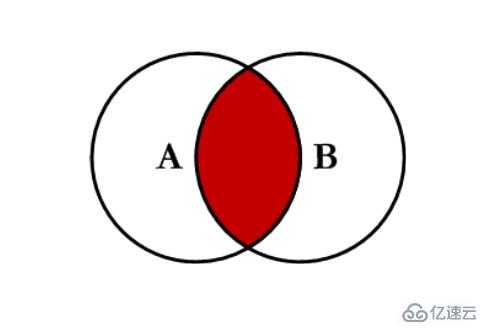
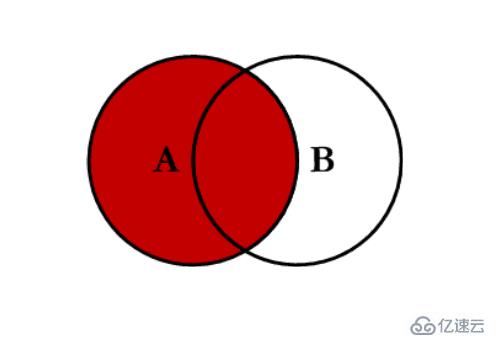
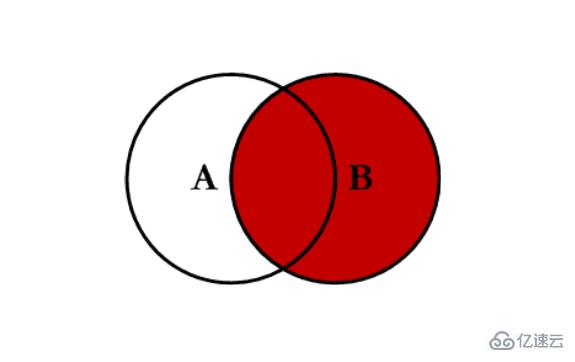
зӨәдҫӢд»Јз Ғпјҡ
import pandas as pdimport numpy as np
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})pd.merge(left,right,on='key') #жҢҮе®ҡиҝһжҺҘй”®keyиҝҗиЎҢз»“жһңпјҡ
key A B C D0 K0 A0 B0 C0 D01 K1 A1 B1 C1 D12 K2 A2 B2 C2 D23 K3 A3 B3 C3 D3
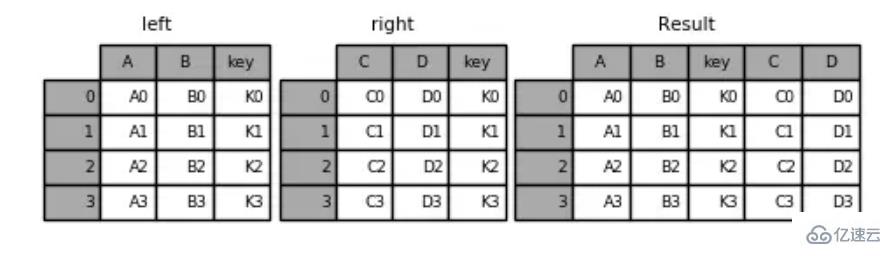
зӨәдҫӢд»Јз Ғпјҡ
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})pd.merge(left,right,on=['key1','key2']) #жҢҮе®ҡеӨҡдёӘй”®пјҢиҝӣиЎҢеҗҲ并иҝҗиЎҢз»“жһңпјҡ
key1 key2 A B C D0 K0 K0 A0 B0 C0 D01 K1 K0 A2 B2 C1 D12 K1 K0 A2 B2 C2 D2
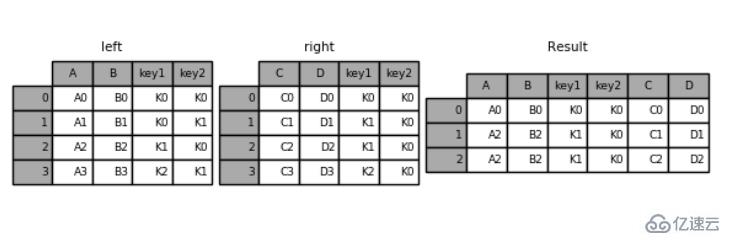
#жҢҮе®ҡе·ҰиҝһжҺҘleft = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})pd.merge(left, right, how='left', on=['key1', 'key2'])
key1 key2 A B C D0 K0 K0 A0 B0 C0 D01 K0 K1 A1 B1 NaN NaN2 K1 K0 A2 B2 C1 D13 K1 K0 A2 B2 C2 D24 K2 K1 A3 B3 NaN NaN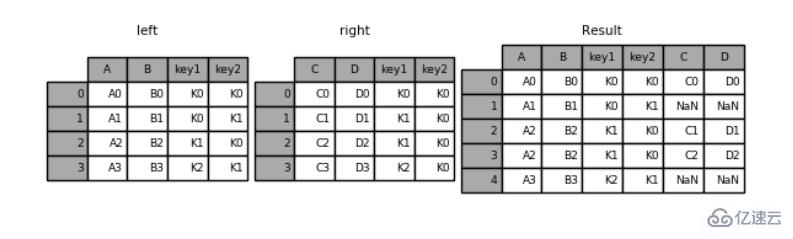
#жҢҮе®ҡеҸіиҝһжҺҘleft = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})pd.merge(left, right, how='right', on=['key1', 'key2'])
key1 key2 A B C D0 K0 K0 A0 B0 C0 D01 K1 K0 A2 B2 C1 D12 K1 K0 A2 B2 C2 D23 K2 K0 NaN NaN C3 D3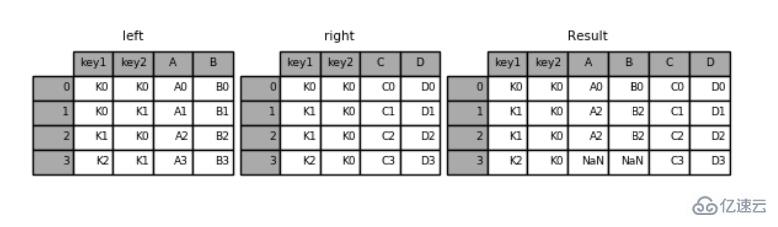
й»ҳи®ӨжҳҜвҖңеҶ…иҝһжҺҘвҖқ(inner)пјҢеҚіз»“жһңдёӯзҡ„й”®жҳҜдәӨйӣҶ
how: жҢҮе®ҡиҝһжҺҘж–№ејҸ
вҖңеӨ–иҝһжҺҘвҖқ(outer)пјҢз»“жһңдёӯзҡ„й”®жҳҜ并йӣҶ
зӨәдҫӢд»Јз Ғпјҡ
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,how='outer',on=['key1','key2'])иҝҗиЎҢз»“жһңпјҡ
key1 key2 A B C D0 K0 K0 A0 B0 C0 D01 K0 K1 A1 B1 NaN NaN2 K1 K0 A2 B2 C1 D13 K1 K0 A2 B2 C2 D24 K2 K1 A3 B3 NaN NaN5 K2 K0 NaN NaN C3 D3
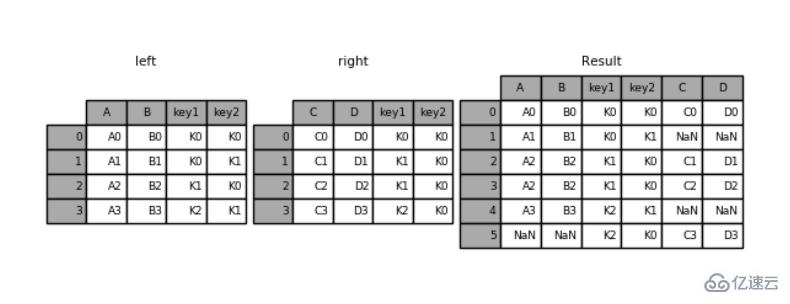
1. еӨ„зҗҶйҮҚеӨҚеҲ—еҗҚ
еҸӮж•°suffixesпјҡй»ҳи®Өдёә_x, _y
зӨәдҫӢд»Јз Ғпјҡ
# еӨ„зҗҶйҮҚеӨҚеҲ—еҗҚdf_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))иҝҗиЎҢз»“жһңпјҡ
data_left key data_right0 9 b 11 5 b 12 1 b 13 2 a 84 2 a 85 5 a 8
2. жҢүзҙўеј•иҝһжҺҘ
еҸӮж•°left_index=TrueжҲ–right_index=True
зӨәдҫӢд»Јз Ғпјҡ
# жҢүзҙўеј•иҝһжҺҘdf_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})df_obj2 = pd.DataFrame({'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))иҝҗиЎҢз»“жһңпјҡ
data1 key data20 3 b 61 4 b 66 8 b 62 6 a 04 3 a 05 0 a 0
2. ж•°жҚ®еҗҲ并(pd.concat)
жІҝиҪҙж–№еҗ‘е°ҶеӨҡдёӘеҜ№иұЎеҗҲ并еҲ°дёҖиө·
1. NumPyзҡ„concat
np.concatenate
зӨәдҫӢд»Јз Ғпјҡ
import numpy as npimport pandas as pd
arr1 = np.random.randint(0, 10, (3, 4))arr2 = np.random.randint(0, 10, (3, 4))print(arr1)print(arr2)print(np.concatenate([arr1, arr2])) # й»ҳи®Өaxis=0пјҢжҢүиЎҢжӢјжҺҘprint(np.concatenate([arr1, arr2], axis=1)) # жҢүеҲ—жӢјжҺҘ
иҝҗиЎҢз»“жһңпјҡ
# print(arr1)[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]]# print(arr2)[[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]# print(np.concatenate([arr1, arr2]))
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]
[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]# print(np.concatenate([arr1, arr2], axis=1)) [[3 3 0 8 6 8 7 3]
[2 0 3 1 1 6 8 7]
[4 8 8 2 1 4 7 1]]
2. pd.concat
жіЁж„ҸжҢҮе®ҡиҪҙж–№еҗ‘пјҢй»ҳи®Өaxis=0
joinжҢҮе®ҡеҗҲ并方ејҸпјҢй»ҳи®Өдёәouter
SeriesеҗҲ并时жҹҘзңӢиЎҢзҙўеј•жңүж— йҮҚеӨҚ
df1 = pd.DataFrame(np.arange(6).reshape(3,2),index=list('abc'),columns=['one','two'])df2 = pd.DataFrame(np.arange(4).reshape(2,2)+5,index=list('ac'),columns=['three','four'])pd.concat([df1,df2]) #й»ҳи®ӨеӨ–иҝһжҺҘпјҢaxis=0
four one three two
a NaN 0.0 NaN 1.0b NaN 2.0 NaN 3.0c NaN 4.0 NaN 5.0a 6.0 NaN 5.0 NaN
c 8.0 NaN 7.0 NaN
pd.concat([df1,df2],axis='columns') #жҢҮе®ҡaxis=1иҝһжҺҘ
one two three four
a 0 1 5.0 6.0b 2 3 NaN NaN
c 4 5 7.0 8.0#еҗҢж ·жҲ‘们д№ҹеҸҜд»ҘжҢҮе®ҡиҝһжҺҘзҡ„ж–№ејҸдёәinnerpd.concat([df1,df2],axis=1,join='inner')
one two three four
a 0 1 5 6c 4 5 7 87.3 йҮҚеЎ‘
1. stack
зӨәдҫӢд»Јз Ғпјҡ
import numpy as npimport pandas as pd
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])print(df_obj)stacked = df_obj.stack()print(stacked)
иҝҗиЎҢз»“жһңпјҡ
# print(df_obj)
data1 data20 7 91 7 82 8 93 4 14 1 2# print(stacked)0 data1 7
data2 91 data1 7
data2 82 data1 8
data2 93 data1 4
data2 14 data1 1
data2 2dtype: int64
2. unstack
зӨәдҫӢд»Јз Ғпјҡ
# й»ҳи®Өж“ҚдҪңеҶ…еұӮзҙўеј•print(stacked.unstack())# йҖҡиҝҮlevelжҢҮе®ҡж“ҚдҪңзҙўеј•зҡ„зә§еҲ«print(stacked.unstack(level=0))
иҝҗиЎҢз»“жһңпјҡ
# print(stacked.unstack())
data1 data20 7 91 7 82 8 93 4 14 1 2# print(stacked.unstack(level=0))
0 1 2 3 4data1 7 7 8 4 1data2 9 8 9 1 2
8. ж•°жҚ®еҲҶз»„иҒҡеҗҲ
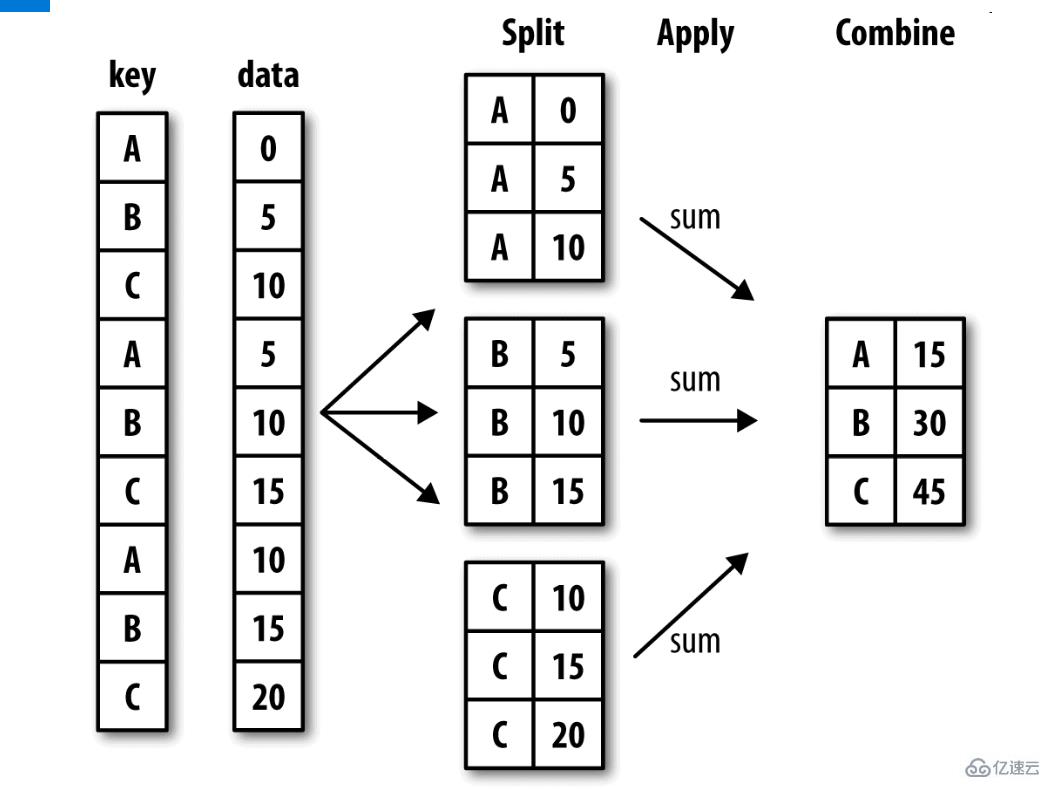
by:ж №жҚ®д»Җд№ҲиҝӣиЎҢеҲҶз»„пјҢз”ЁдәҺзЎ®е®ҡgroupbyзҡ„з»„
as_index:еҜ№дәҺиҒҡеҗҲиҫ“еҮә,иҝ”еӣһд»Ҙз»„дҫҝзӯҫдёәзҙўеј•зҡ„еҜ№иұЎпјҢд»…еҜ№DataFrame
df1 = pd.DataFrame({'fruit':['apple','banana','orange','apple','banana'],
'color':['red','yellow','yellow','cyan','cyan'],
'price':[8.5,6.8,5.6,7.8,6.4]})#жҹҘзңӢзұ»еһӢtype(df1.groupby('fruit'))pandas.core.groupby.groupby.DataFrameGroupBy #GruopByеҜ№иұЎпјҢе®ғжҳҜдёҖдёӘеҢ…еҗ«з»„еҗҚпјҢе’Ңж•°жҚ®еқ—зҡ„2з»ҙе…ғз»„еәҸеҲ—пјҢж”ҜжҢҒиҝӯд»Јfor name, group in df1.groupby('fruit'):
print(name) #иҫ“еҮәз»„еҗҚ
apple
banana
orange print(group) # иҫ“еҮәж•°жҚ®еқ—
fruit color price 0 apple red 8.5
3 apple cyan 7.8
fruit color price 1 banana yellow 6.8
4 banana cyan 6.4
fruit color price 2 orange yellow 5.6
#иҫ“еҮәgroupзұ»еһӢ
print(type(group)) #ж•°жҚ®еқ—жҳҜdataframeзұ»еһӢ
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>
<class 'pandas.core.frame.DataFrame'>#йҖүжӢ©д»»ж„Ҹзҡ„ж•°жҚ®еқ—dict(list(df1.groupby('fruit')))['apple'] #еҸ–еҮәappleз»„зҡ„ж•°жҚ®еқ—
fruit color price0 apple red 8.53 apple cyan 7.8иҒҡеҗҲ
| еҮҪж•°еҗҚ | жҸҸиҝ° |
|---|
| count | еҲҶз»„дёӯйқһNAеҖјзҡ„ж•°йҮҸ |
| sum | йқһNAеҖјзҡ„е’Ң |
| mean | йқһNAеҖјзҡ„е№іеқҮеҖј |
| median | йқһNAеҖјзҡ„дёӯдҪҚж•° |
| std, var | ж ҮеҮҶе·®е’Ңж–№е·® |
| min, max | йқһNAзҡ„жңҖе°ҸеҖјпјҢжңҖеӨ§еҖј |
| prod | йқһNAеҖјзҡ„д№ҳз§Ҝ |
| first, last | йқһNAеҖјзҡ„第дёҖдёӘ,жңҖеҗҺдёҖдёӘ |
#GroupbyеҜ№иұЎе…·жңүдёҠиЎЁдёӯзҡ„иҒҡеҗҲж–№жі•#ж №жҚ®fruitжқҘжұӮpriceзҡ„е№іеқҮеҖјdf1['price'].groupby(df1['fruit']).mean()fruit
apple 8.15banana 6.60orange 5.60Name: price, dtype: float64
#жҲ–иҖ…df1.groupby('fruit')['price'].mean()# as_index=FalseпјҲдёҚжҠҠеҲҶз»„еҗҺзҡ„еҖјдҪңдёәзҙўеј•пјҢйҮҚж–°з”ҹжҲҗй»ҳи®Өзҙўеј•пјүdf1.groupby('fruit',as_index=False)['price'].mean()
fruit price0 apple 8.151 banana 6.602 orange 5.60"""
еҰӮжһңжҲ‘зҺ°еңЁжңүдёӘйңҖжұӮпјҢи®Ўз®—жҜҸз§Қж°ҙжһңзҡ„е·®еҖј,
1.дёҠиЎЁдёӯзҡ„иҒҡеҗҲеҮҪж•°дёҚиғҪж»Ўи¶ідәҺжҲ‘们зҡ„йңҖжұӮпјҢжҲ‘们йңҖиҰҒдҪҝз”ЁиҮӘе®ҡд№үзҡ„иҒҡеҗҲеҮҪж•°
2.еңЁеҲҶз»„еҜ№иұЎдёӯпјҢдҪҝз”ЁжҲ‘们иҮӘе®ҡд№үзҡ„иҒҡеҗҲеҮҪж•°
"""#е®ҡд№үдёҖдёӘи®Ўз®—е·®еҖјзҡ„еҮҪж•°def diff_value(arr):
return arr.max() - arr.min()#дҪҝз”ЁиҮӘе®ҡд№үиҒҡеҗҲеҮҪж•°пјҢжҲ‘们йңҖиҰҒе°ҶеҮҪж•°дј йҖ’з»ҷaggжҲ–aggregateж–№жі•пјҢжҲ‘们дҪҝз”ЁиҮӘе®ҡд№үиҒҡеҗҲеҮҪж•°ж—¶пјҢдјҡжҜ”жҲ‘们表дёӯзҡ„иҒҡеҗҲеҮҪж•°ж…ўзҡ„еӨҡпјҢеӣ дёәиҰҒиҝӣиЎҢеҮҪж•°и°ғз”ЁпјҢж•°жҚ®йҮҚж–°жҺ’еҲ—df1.groupby('fruit')['price'].agg(diff_value)fruit
apple 0.7banana 0.4orange 0.0Name: price, dtype: float64йҖҡиҝҮеӯ—е…ёжҲ–SeriesеҜ№иұЎиҝӣиЎҢеҲҶз»„пјҡ
m = {'a':'red', 'b':'blue'}people.groupby(m, axis=1).sum()s1 = pd.Series(m)people.groupby(s1, axis=1).sum()йҖҡиҝҮеҮҪж•°иҝӣиЎҢеҲҶз»„пјҡ
people.groupyby(len).sum()
9. Pandasдёӯзҡ„ж—¶й—ҙеәҸеҲ—
ж—¶й—ҙеәҸеҲ—пјҲtime seriesпјүж•°жҚ®жҳҜдёҖз§ҚйҮҚиҰҒзҡ„з»“жһ„еҢ–ж•°жҚ®еҪўејҸгҖӮ
еңЁеӨҡдёӘж—¶й—ҙзӮ№и§ӮеҜҹжҲ–жөӢйҮҸеҲ°зҡ„д»»дҪ•ж—¶й—ҙйғҪеҸҜд»ҘеҪўжҲҗдёҖж®өж—¶й—ҙеәҸеҲ—гҖӮеҫҲеӨҡж—¶й—ҙпјҢ ж—¶й—ҙеәҸеҲ—жҳҜеӣәе®ҡйў‘зҺҮзҡ„пјҢ д№ҹе°ұжҳҜиҜҙпјҢ ж•°жҚ®зӮ№жҳҜж №жҚ®жҹҗз§Қ规еҫӢе®ҡжңҹеҮәзҺ°зҡ„пјҲжҜ”еҰӮжҜҸ15з§’вҖҰпјүгҖӮ
ж—¶й—ҙеәҸеҲ—д№ҹеҸҜд»ҘжҳҜдёҚе®ҡжңҹзҡ„гҖӮж—¶й—ҙеәҸеҲ—ж•°жҚ®зҡ„ж„Ҹд№үеҸ–еҶідәҺе…·дҪ“зҡ„еә”з”ЁеңәжҷҜгҖӮ
дё»иҰҒз”ұд»ҘдёӢеҮ з§Қпјҡ
ж—¶й—ҙжҲіпјҲtimestampпјүпјҢзү№е®ҡзҡ„ж—¶еҲ»гҖӮ
еӣәе®ҡж—¶жңҹпјҲperiodпјүпјҢеҰӮ2007е№ҙ1жңҲжҲ–2010е№ҙе…Ёе№ҙгҖӮ
ж—¶й—ҙй—ҙйҡ”пјҲintervalпјүпјҢз”ұиө·е§Ӣе’Ңз»“жқҹж—¶й—ҙжҲіиЎЁзӨәгҖӮж—¶жңҹпјҲperiodпјүеҸҜд»Ҙиў«зңӢеҒҡй—ҙйҡ”пјҲintervalпјүзҡ„зү№дҫӢгҖӮ
9.1 ж—¶й—ҙе’Ңж—Ҙжңҹж•°жҚ®зұ»еһӢеҸҠе…¶е·Ҙе…·
Pythonж ҮеҮҶеә“еҢ…еҗ«з”ЁдәҺж—ҘжңҹпјҲdateпјүе’Ңж—¶й—ҙпјҲtimeпјүж•°жҚ®зҡ„ж•°жҚ®зұ»еһӢпјҢиҖҢдё”иҝҳжңүж—ҘеҺҶж–№йқўзҡ„еҠҹиғҪгҖӮжҲ‘们主иҰҒдјҡз”ЁеҲ°datetimeгҖҒtimeд»ҘеҸҠcalendarжЁЎеқ—гҖӮ
datetime.datetimeпјҲд№ҹеҸҜд»Ҙз®ҖеҶҷдёәdatetimeпјүжҳҜз”Ёеҫ—жңҖеӨҡзҡ„ж•°жҚ®зұ»еһӢпјҡ
In [10]: from datetime import datetime
In [11]: now = datetime.now()In [12]: now
Out[12]: datetime.datetime(2017, 9, 25, 14, 5, 52, 72973)In [13]: now.year, now.month, now.day
Out[13]: (2017, 9, 25)
datetimeд»ҘжҜ«з§’еҪўејҸеӯҳеӮЁж—Ҙжңҹе’Ңж—¶й—ҙгҖӮtimedeltaиЎЁзӨәдёӨдёӘdatetimeеҜ№иұЎд№Ӣй—ҙзҡ„ж—¶й—ҙе·®пјҡ
In [14]: delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)In [15]: delta
Out[15]: datetime.timedelta(926, 56700)In [16]: delta.days
Out[16]: 926In [17]: delta.seconds
Out[17]: 56700
еҸҜд»Ҙз»ҷdatetimeеҜ№иұЎеҠ дёҠпјҲжҲ–еҮҸеҺ»пјүдёҖдёӘжҲ–еӨҡдёӘtimedeltaпјҢиҝҷж ·дјҡдә§з”ҹдёҖдёӘж–°еҜ№иұЎпјҡ
In [18]: from datetime import timedelta
In [19]: start = datetime(2011, 1, 7)In [20]: start + timedelta(12)Out[20]: datetime.datetime(2011, 1, 19, 0, 0)In [21]: start - 2 * timedelta(12)Out[21]: datetime.datetime(2010, 12, 14, 0, 0)

9.2 еӯ—з¬ҰдёІе’Ңdatetimeзҡ„зӣёдә’иҪ¬жҚў
еҲ©з”ЁstrжҲ–strftimeж–№жі•пјҲдј е…ҘдёҖдёӘж јејҸеҢ–еӯ—з¬ҰдёІпјүпјҢdatetimeеҜ№иұЎе’Ңpandasзҡ„TimestampеҜ№иұЎпјҲзЁҚеҗҺе°ұдјҡд»Ӣз»ҚпјүеҸҜд»Ҙиў«ж јејҸеҢ–дёәеӯ—з¬ҰдёІпјҡ
In [22]: stamp = datetime(2011, 1, 3)In [23]: str(stamp)Out[23]: '2011-01-03 00:00:00'In [24]: stamp.strftime('%Y-%m-%d')Out[24]: '2011-01-03'
datetime.strptimeеҸҜд»Ҙз”Ёиҝҷдәӣж јејҸеҢ–зј–з Ғе°Ҷеӯ—з¬ҰдёІиҪ¬жҚўдёәж—Ҙжңҹпјҡ
In [26]: datetime.strptime(value, '%Y-%m-%d')Out[26]: datetime.datetime(2011, 1, 3, 0, 0)In [27]: datestrs = ['7/6/2011', '8/6/2011']In [28]: [datetime.strptime(x, '%m/%d/%Y') for x in datestrs]Out[28]: [datetime.datetime(2011, 7, 6, 0, 0),
datetime.datetime(2011, 8, 6, 0, 0)]
datetime.strptimeжҳҜйҖҡиҝҮе·ІзҹҘж јејҸиҝӣиЎҢж—Ҙжңҹи§Јжһҗзҡ„жңҖдҪіж–№ејҸгҖӮдҪҶжҳҜжҜҸж¬ЎйғҪиҰҒзј–еҶҷж јејҸе®ҡд№үжҳҜеҫҲйә»зғҰзҡ„дәӢжғ…пјҢе°Өе…¶жҳҜеҜ№дәҺдёҖдәӣеёёи§Ғзҡ„ж—Ҙжңҹж јејҸгҖӮ
иҝҷз§Қжғ…еҶөдёӢпјҢдҪ еҸҜд»Ҙз”ЁdateutilиҝҷдёӘ第дёүж–№еҢ…дёӯзҡ„parser.parseж–№жі•пјҲpandasдёӯе·Із»ҸиҮӘеҠЁе®үиЈ…еҘҪдәҶпјүпјҡ
In [29]: from dateutil.parser import parse
In [30]: parse('2011-01-03')Out[30]: datetime.datetime(2011, 1, 3, 0, 0)dateutilеҸҜд»Ҙи§ЈжһҗеҮ д№ҺжүҖжңүдәәзұ»иғҪеӨҹзҗҶи§Јзҡ„ж—ҘжңҹиЎЁзӨәеҪўејҸпјҡ
In [31]: parse('Jan 31, 1997 10:45 PM')Out[31]: datetime.datetime(1997, 1, 31, 22, 45)еңЁеӣҪйҷ…йҖҡз”Ёзҡ„ж јејҸдёӯпјҢж—ҘеҮәзҺ°еңЁжңҲзҡ„еүҚйқўеҫҲжҷ®йҒҚпјҢдј е…Ҙdayfirst=TrueеҚіеҸҜи§ЈеҶіиҝҷдёӘй—®йўҳпјҡ
In [32]: parse('6/12/2011', dayfirst=True)Out[32]: datetime.datetime(2011, 12, 6, 0, 0)PandasйҖҡеёёжҳҜз”ЁдәҺеӨ„зҗҶжҲҗз»„ж—Ҙжңҹзҡ„пјҢдёҚз®Ўиҝҷдәӣж—ҘжңҹжҳҜDataFrameзҡ„иҪҙзҙўеј•иҝҳжҳҜеҲ—гҖӮto_datetimeж–№жі•еҸҜд»Ҙи§ЈжһҗеӨҡз§ҚдёҚеҗҢзҡ„ж—ҘжңҹиЎЁзӨәеҪўејҸгҖӮеҜ№ж ҮеҮҶж—Ҙжңҹж јејҸпјҲеҰӮISO8601пјүзҡ„и§Јжһҗйқһеёёеҝ«пјҡ
In [33]: datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']In [34]: pd.to_datetime(datestrs)Out[34]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
е®ғиҝҳеҸҜд»ҘеӨ„зҗҶзјәеӨұеҖјпјҲNoneгҖҒз©әеӯ—з¬ҰдёІзӯүпјүпјҡ
In [35]: idx = pd.to_datetime(datestrs + [None])In [36]: idx
Out[36]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dty
pe='datetime64[ns]', freq=None)In [37]: idx[2]Out[37]: NaT
In [38]: pd.isnull(idx)Out[38]: array([False, False, True], dtype=bool)
NaTпјҲNot a TimeпјүжҳҜPandasдёӯж—¶й—ҙжҲіж•°жҚ®зҡ„nullеҖјгҖӮ
ж—¶й—ҙеәҸеҲ—еҹәзЎҖ
pandasжңҖеҹәжң¬зҡ„ж—¶й—ҙеәҸеҲ—зұ»еһӢе°ұжҳҜд»Ҙж—¶й—ҙжҲіпјҲйҖҡеёёд»ҘPythonеӯ—з¬ҰдёІжҲ–datatimeеҜ№иұЎиЎЁзӨәпјүдёәзҙўеј•зҡ„Seriesпјҡ
In [39]: from datetime import datetime
In [40]: dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
....: datetime(2011, 1, 7), datetime(2011, 1, 8),
....: datetime(2011, 1, 10), datetime(2011, 1, 12)]In [41]: ts = pd.Series(np.random.randn(6), index=dates)In [42]: ts
Out[42]: 2011-01-02 -0.2047082011-01-05 0.4789432011-01-07 -0.5194392011-01-08 -0.5557302011-01-10 1.9657812011-01-12 1.393406dtype: float64
иҝҷдәӣdatetimeеҜ№иұЎе®һйҷ…дёҠжҳҜиў«ж”ҫеңЁдёҖдёӘDatetimeIndexдёӯзҡ„пјҡ
In [43]: ts.index
Out[43]: DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)
и·ҹе…¶д»–SeriesдёҖж ·пјҢдёҚеҗҢзҙўеј•зҡ„ж—¶й—ҙеәҸеҲ—д№Ӣй—ҙзҡ„з®—жңҜиҝҗз®—дјҡиҮӘеҠЁжҢүж—ҘжңҹеҜ№йҪҗпјҡ
In [44]: ts + ts[::2]Out[44]: 2011-01-02 -0.4094152011-01-05 NaN2011-01-07 -1.0388772011-01-08 NaN2011-01-10 3.9315612011-01-12 NaN
dtype: float64
ts[::2] жҳҜжҜҸйҡ”дёӨдёӘеҸ–дёҖдёӘгҖӮ
9.3 зҙўеј•гҖҒйҖүеҸ–гҖҒеӯҗйӣҶжһ„йҖ
еҪ“дҪ ж №жҚ®ж Үзӯҫзҙўеј•йҖүеҸ–ж•°жҚ®ж—¶пјҢж—¶й—ҙеәҸеҲ—е’Ңе…¶е®ғзҡ„pandas.SeriesеҫҲеғҸпјҡ
In [48]: stamp = ts.index[2]In [49]: ts[stamp]Out[49]: -0.51943871505673811
иҝҳжңүдёҖз§Қжӣҙдёәж–№дҫҝзҡ„з”Ёжі•пјҡдј е…ҘдёҖдёӘеҸҜд»Ҙиў«и§ЈйҮҠдёәж—Ҙжңҹзҡ„еӯ—з¬ҰдёІпјҡ
In [50]: ts['1/10/2011']Out[50]: 1.9657805725027142In [51]: ts['20110110']Out[51]: 1.9657805725027142
9.4 ж—Ҙжңҹзҡ„иҢғеӣҙгҖҒйў‘зҺҮд»ҘеҸҠ移еҠЁ
Pandasдёӯзҡ„еҺҹз”ҹж—¶й—ҙеәҸеҲ—дёҖиҲ¬иў«и®ӨдёәжҳҜдёҚ规еҲҷзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢе®ғ们没жңүеӣәе®ҡзҡ„йў‘зҺҮгҖӮеҜ№дәҺеӨ§йғЁеҲҶеә”з”ЁзЁӢеәҸиҖҢиЁҖпјҢиҝҷжҳҜж— жүҖи°“зҡ„гҖӮдҪҶжҳҜпјҢе®ғеёёеёёйңҖиҰҒд»Ҙжҹҗз§ҚзӣёеҜ№еӣәе®ҡзҡ„йў‘зҺҮиҝӣиЎҢеҲҶжһҗпјҢжҜ”еҰӮжҜҸж—ҘгҖҒжҜҸжңҲгҖҒжҜҸ15еҲҶй’ҹзӯүпјҲиҝҷж ·иҮӘ然дјҡеңЁж—¶й—ҙеәҸеҲ—дёӯеј•е…ҘзјәеӨұеҖјпјүгҖӮ
е№ёиҝҗзҡ„жҳҜпјҢpandasжңүдёҖж•ҙеҘ—ж ҮеҮҶж—¶й—ҙеәҸеҲ—йў‘зҺҮд»ҘеҸҠз”ЁдәҺйҮҚйҮҮж ·гҖҒйў‘зҺҮжҺЁж–ӯгҖҒз”ҹжҲҗеӣәе®ҡйў‘зҺҮж—ҘжңҹиҢғеӣҙзҡ„е·Ҙе…·гҖӮ
дҫӢеҰӮпјҢжҲ‘们еҸҜд»Ҙе°Ҷд№ӢеүҚйӮЈдёӘж—¶й—ҙеәҸеҲ—иҪ¬жҚўдёәдёҖдёӘе…·жңүеӣәе®ҡйў‘зҺҮпјҲжҜҸж—Ҙпјүзҡ„ж—¶й—ҙеәҸеҲ—пјҢеҸӘйңҖи°ғз”ЁresampleеҚіеҸҜпјҡ
In [72]: ts
Out[72]: 2011-01-02 -0.2047082011-01-05 0.4789432011-01-07 -0.5194392011-01-08 -0.5557302011-01-10 1.9657812011-01-12 1.393406dtype: float64
In [73]: resampler = ts.resample('D')еӯ—з¬ҰдёІвҖңDвҖқжҳҜжҜҸеӨ©зҡ„ж„ҸжҖқгҖӮ
йў‘зҺҮзҡ„иҪ¬жҚўпјҲжҲ–йҮҚйҮҮж ·пјүжҳҜдёҖдёӘжҜ”иҫғеӨ§зҡ„дё»йўҳгҖӮиҝҷйҮҢпјҢжҲ‘е°Ҷе‘ҠиҜүдҪ еҰӮдҪ•дҪҝз”Ёеҹәжң¬зҡ„йў‘зҺҮе’Ңе®ғзҡ„еҖҚж•°гҖӮ
з”ҹжҲҗж—ҘжңҹиҢғеӣҙ
иҷҪ然жҲ‘д№ӢеүҚз”Ёзҡ„ж—¶еҖҷжІЎжңүжҳҺиҜҙпјҢдҪҶдҪ еҸҜиғҪе·Із»ҸзҢңеҲ°pandas.date_rangeеҸҜз”ЁдәҺж №жҚ®жҢҮе®ҡзҡ„йў‘зҺҮз”ҹжҲҗжҢҮе®ҡй•ҝеәҰзҡ„ DatetimeIndexпјҡ
In [74]: index = pd.date_range('2012-04-01', '2012-06-01')In [75]: index
Out[75]: DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')й»ҳи®Өжғ…еҶөдёӢпјҢdate_rangeдјҡдә§з”ҹжҢүеӨ©и®Ўз®—зҡ„ж—¶й—ҙзӮ№гҖӮеҰӮжһңеҸӘдј е…Ҙиө·е§ӢжҲ–з»“жқҹж—ҘжңҹпјҢйӮЈе°ұиҝҳеҫ—дј е…ҘдёҖдёӘиЎЁзӨәдёҖж®өж—¶й—ҙзҡ„ж•°еӯ—пјҡ
In [76]: pd.date_range(start='2012-04-01', periods=20)Out[76]: DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')In [77]: pd.date_range(end='2012-06-01', periods=20)Out[77]: DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27','2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
иө·е§Ӣе’Ңз»“жқҹж—Ҙжңҹе®ҡд№үдәҶж—Ҙжңҹзҙўеј•зҡ„дёҘж јиҫ№з•ҢгҖӮ
дҫӢеҰӮпјҢеҰӮжһңдҪ жғіиҰҒз”ҹжҲҗдёҖдёӘз”ұжҜҸжңҲжңҖеҗҺдёҖдёӘе·ҘдҪңж—Ҙз»„жҲҗзҡ„ж—Ҙжңҹзҙўеј•пјҢеҸҜд»Ҙдј е…Ҙ"BM"йў‘зҺҮпјҲиЎЁзӨәbusiness end of monthпјүпјҢиҝҷж ·е°ұеҸӘдјҡеҢ…еҗ«ж—¶й—ҙй—ҙйҡ”еҶ…пјҲжҲ–еҲҡеҘҪеңЁиҫ№з•ҢдёҠзҡ„пјүз¬ҰеҗҲйў‘зҺҮиҰҒжұӮзҡ„ж—Ҙжңҹпјҡ
In [78]: pd.date_range('2000-01-01', '2000-12-01', freq='BM')Out[78]: DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
йҮҚйҮҮж ·еҸҠйў‘зҺҮиҪ¬жҚў
йҮҚйҮҮж ·пјҲresamplingпјүжҢҮзҡ„жҳҜе°Ҷж—¶й—ҙеәҸеҲ—д»ҺдёҖдёӘйў‘зҺҮиҪ¬жҚўеҲ°еҸҰдёҖдёӘйў‘зҺҮзҡ„еӨ„зҗҶиҝҮзЁӢгҖӮ
е°Ҷй«ҳйў‘зҺҮж•°жҚ®иҒҡеҗҲеҲ°дҪҺйў‘зҺҮз§°дёәйҷҚйҮҮж ·пјҲdownsamplingпјүпјҢиҖҢе°ҶдҪҺйў‘зҺҮж•°жҚ®иҪ¬жҚўеҲ°й«ҳйў‘зҺҮеҲҷз§°дёәеҚҮйҮҮж ·пјҲupsamplingпјүгҖӮ并дёҚжҳҜжүҖжңүзҡ„йҮҚйҮҮж ·йғҪиғҪиў«еҲ’еҲҶеҲ°иҝҷдёӨдёӘеӨ§зұ»дёӯгҖӮ
дҫӢеҰӮпјҢе°ҶW-WEDпјҲжҜҸе‘ЁдёүпјүиҪ¬жҚўдёәW-FRIж—ўдёҚжҳҜйҷҚйҮҮж ·д№ҹдёҚжҳҜеҚҮйҮҮж ·гҖӮ
PandasеҜ№иұЎйғҪеёҰжңүдёҖдёӘresampleж–№жі•пјҢе®ғжҳҜеҗ„з§Қйў‘зҺҮиҪ¬жҚўе·ҘдҪңзҡ„дё»еҠӣеҮҪж•°гҖӮresampleжңүдёҖдёӘзұ»дјјдәҺgroupbyзҡ„APIпјҢи°ғз”ЁresampleеҸҜд»ҘеҲҶз»„ж•°жҚ®пјҢ然еҗҺдјҡи°ғз”ЁдёҖдёӘиҒҡеҗҲеҮҪж•°пјҡ
In [208]: rng = pd.date_range('2000-01-01', periods=100, freq='D')In [209]: ts = pd.Series(np.random.randn(len(rng)), index=rng)In [210]: ts
Out[210]: 2000-01-01 0.6316342000-01-02 -1.5943132000-01-03 -1.5199372000-01-04 1.1087522000-01-05 1.2558532000-01-06 -0.0243302000-01-07 -2.0479392000-01-08 -0.2726572000-01-09 -1.6926152000-01-10 1.423830
... 2000-03-31 -0.0078522000-04-01 -1.6388062000-04-02 1.4012272000-04-03 1.7585392000-04-04 0.6289322000-04-05 -0.4237762000-04-06 0.7897402000-04-07 0.9375682000-04-08 -2.2532942000-04-09 -1.772919Freq: D, Length: 100, dtype: float64
In [211]: ts.resample('M').mean()Out[211]: 2000-01-31 -0.1658932000-02-29 0.0786062000-03-31 0.2238112000-04-30 -0.063643Freq: M, dtype: float64
In [212]: ts.resample('M', kind='period').mean()Out[212]: 2000-01 -0.1658932000-02 0.0786062000-03 0.2238112000-04 -0.063643Freq: M, dtype: float64resampleжҳҜдёҖдёӘзҒөжҙ»й«ҳж•Ҳзҡ„ж–№жі•пјҢеҸҜз”ЁдәҺеӨ„зҗҶйқһеёёеӨ§зҡ„ж—¶й—ҙеәҸеҲ—гҖӮ
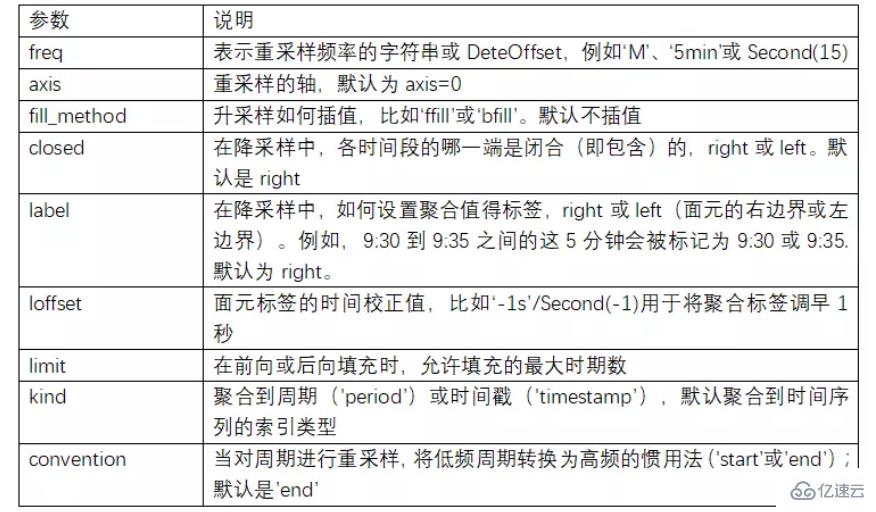
вҖңPython Pandasзҡ„зҹҘиҜҶзӮ№жңүе“ӘдәӣвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





