жҖҺд№Ҳз”ЁPythonВ PandasеӨ„зҗҶCSVж–Ү件
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңжҖҺд№Ҳз”ЁPython PandasеӨ„зҗҶCSVж–Ү件вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңжҖҺд№Ҳз”ЁPython PandasеӨ„зҗҶCSVж–Ү件вҖқеҗ§!
иҜ»еҸ–Pandasж–Ү件
df = pd.read_csv(file_path, encoding='GB2312')
print(df.info())
жіЁж„ҸпјҡPandasзҡ„иҜ»еҸ–ж јејҸй»ҳи®ӨжҳҜUTF-8пјҢеңЁдёӯж–ҮCSVдёӯдјҡжҠҘй”ҷпјҡ
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd1 in position 2: invalid continuation byte
дҝ®ж”№зј–з Ғдёә GB2312 пјҢеҚіеҸҜпјҢжҲ–иҖ…еҝҪз•ҘencodeиҪ¬д№үй”ҷиҜҜпјҢеҰӮдёӢпјҡ
df = pd.read_csv(file_path, encoding='GB2312')
df = pd.read_csv(file_path, encoding='unicode_escape')
df.info()жҳҫзӨәdfзҡ„еҹәжң¬дҝЎжҒҜпјҢдҫӢеҰӮпјҡ
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3840 entries, 0 to 3839
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 е®һйӘҢж—¶й—ҙжү№ж¬Ў 3840 non-null object
1 зү©й•ңеҖҚж•° 3840 non-null object
2 жқҝеӯҗзј–еҸ· 3840 non-null object
3 жқҝеӯҗзј–еҸ·еҸҠзү©й•ңеҖҚж•° 3840 non-null object
4 еӣҫеҗҚз§° 3840 non-null object
5 з»Ҷиғһзұ»еһӢ 3840 non-null object
6 жқҝеӯҗеӯ”дҪҚзҪ® 3840 non-null object
7 еӯ”жӢҚж‘„дҪҚзҪ® 3840 non-null int64
8 з»Ҷиғһеҹ№е…»еҹә 3840 non-null object
9 з»Ҷиғһеҹ№е…»ж—¶й—ҙпјҲе°Ҹж—¶пјү 3840 non-null int64
10 жү°еҠЁзұ»еҲ« 3840 non-null object
11 жү°еҠЁеӨ„зҗҶж—¶й—ҙпјҲе°Ҹж—¶пјү 3840 non-null int64
12 жү°еҠЁеӨ„зҗҶжө“еәҰпјҲug/mlпјү 3840 non-null float64
13 ж ҮжіЁжҝҖжҙ»(1/0) 3840 non-null int64
14 unique 3840 non-null object
15 tvt 3840 non-null int64
dtypes: float64(1), int64(5), object(10)
memory usage: 480.1+ KB
з»ҹи®ЎеҲ—еҖјеҮәзҺ°зҡ„ж¬Ўж•°
df[еҲ—еҗҚ].value_counts()пјҢеҰӮdf["жү°еҠЁзұ»еҲ«"].value_counts()пјҡ
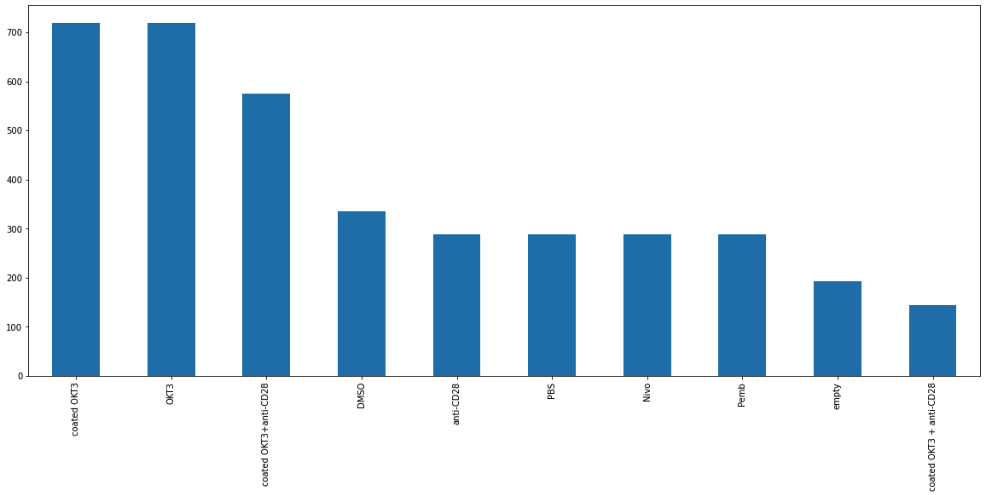
df["жү°еҠЁзұ»еҲ«"].value_counts()
иҫ“еҮәпјҡ
coated OKT3 720
OKT3 720
coated OKT3+anti-CD28 576
DMSO 336
anti-CD28 288
PBS 288
Nivo 288
Pemb 288
empty 192
coated OKT3 + anti-CD28 144
Name: жү°еҠЁзұ»еҲ«, dtype: int64
зӣҙжҺҘз»ҳеҲ¶value_counts()зҡ„жҹұеҪўеӣҫпјҢеҸӮиҖғPandas - Chart Visualizationпјҡ
import matplotlib.pyplot as plt
%matplotlib inline
plt.close("all")
plt.figure(figsize=(20, 8))
df["жү°еҠЁзұ»еҲ«"].value_counts().plot(kind="bar")
# plt.xticks(rotation='vertical', fontsize=10)
plt.show()жҹұеҪўеӣҫпјҡ
зӯӣйҖүзү№е®ҡеҲ—еҖј
df.loc[зӯӣйҖүжқЎд»¶]пјҢзӯӣйҖүзү№е®ҡеҲ—еҖјд№ӢеҗҺпјҢйҮҚж–°иөӢеҖјпјҢеҸӘеӨ„зҗҶзӯӣйҖүеҖјпјҢд№ҹеҸҜд»ҘеҶҷе…Ҙcsvж–Ү件гҖӮ
df_plate1 = df.loc[df["жқҝеӯҗзј–еҸ·"] == "plate1"]
df_plate1.info()
# df.loc[df["жқҝеӯҗзј–еҸ·"] == "plate1"].to_csv("batch4_IOStrain_klasses_utf8_plate1.csv") # еӯҳеӮЁCSVж–Ү件注ж„ҸпјҡзӯӣйҖүзҡ„еҶ…еӨ–дёӨдёӘdfйңҖиҰҒзӣёеҗҢпјҢеҗҰеҲҷжҠҘй”ҷ
pandas loc IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match).
иҫ“еҮәпјҢж•°жҚ®йҮҸз”ұ3840дёӢйҷҚдёә1280гҖӮ
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1280 entries, 0 to 1279
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 е®һйӘҢж—¶й—ҙжү№ж¬Ў 1280 non-null object
1 зү©й•ңеҖҚж•° 1280 non-null object
2 жқҝеӯҗзј–еҸ· 1280 non-null object
3 жқҝеӯҗзј–еҸ·еҸҠзү©й•ңеҖҚж•° 1280 non-null object
4 еӣҫеҗҚз§° 1280 non-null object
5 з»Ҷиғһзұ»еһӢ 1280 non-null object
6 жқҝеӯҗеӯ”дҪҚзҪ® 1280 non-null object
7 еӯ”жӢҚж‘„дҪҚзҪ® 1280 non-null int64
8 з»Ҷиғһеҹ№е…»еҹә 1280 non-null object
9 з»Ҷиғһеҹ№е…»ж—¶й—ҙпјҲе°Ҹж—¶пјү 1280 non-null int64
10 жү°еҠЁзұ»еҲ« 1280 non-null object
11 жү°еҠЁеӨ„зҗҶж—¶й—ҙпјҲе°Ҹж—¶пјү 1280 non-null int64
12 жү°еҠЁеӨ„зҗҶжө“еәҰпјҲug/mlпјү 1280 non-null float64
13 ж ҮжіЁжҝҖжҙ»(1/0) 1280 non-null int64
14 unique 1280 non-null object
15 tvt 1280 non-null int64
dtypes: float64(1), int64(5), object(10)
memory usage: 170.0+ KB
йҒҚеҺҶж•°жҚ®иЎҢ
for idx, row in df_plate1_lb0.iterrows():пјҢйҖҡиҝҮrow[вҖңеҲ—еҗҚвҖқ]пјҢиҫ“еҮәе…·дҪ“зҡ„еҖјпјҢеҰӮдёӢпјҡ
for idx, row in df_plate1_lb0.iterrows():
img_name = row["еӣҫеҗҚз§°"]
img_ch_format = img_format.format(img_name, "{}")
for i in range(1, 7):
img_path = os.path.join(plate1_img_folder, img_ch_format.format(i))
img = cv2.imread(img_path)
print('[Info] img shape: {}'.format(img.shape))
breakиҫ“еҮәпјҡ
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
[Info] img shape: (1080, 1080, 3)
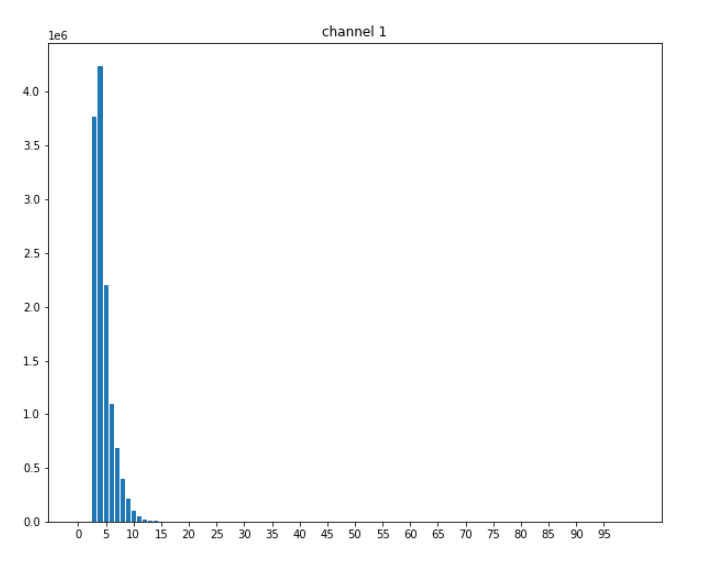
з»ҳеҲ¶зӣҙж–№еӣҫ(жҹұзҠ¶еӣҫ)
з»ҹи®ЎеҺ»йҷӨиғҢжҷҜйўңиүІзҡ„зҒ°еәҰеӣҫеӯ—е…ё
# еҺ»йҷӨиғҢжҷҜйўңиүІ
pix_bkg = np.argmax(np.bincount(img_gray.ravel()))
img_gray = np.where(img_gray <= pix_bkg + 2, 0, img_gray)
img_gray = img_gray.astype(np.uint8)
# з”ҹжҲҗж•°еҖјж•°з»„
hist = cv2.calcHist([img_gray], [0], None, [256], [0, 256])
hist = hist.ravel()
# ж•°еҖјеӯ—е…ё
hist_dict = collections.defaultdict(int)
for i, v in enumerate(hist):
hist_dict[i] += int(v)
# еҺ»йҷӨиғҢжҷҜйўңиүІпјҢе·Із»ҸйғҪз»ҹи®ЎеҲ°0пјҢжүҖд»Ҙ0еҖјйқһеёёеӨ§пјҢеҲ йҷӨ0еҖјпјҢи§ӮеҜҹеҲҶеёғ
hist_dict[0] = 0
з»ҳеҲ¶жҹұзҠ¶еӣҫпјҡ
plt.subplotsпјҡи®ҫзҪ®еӨҡдёӘеӯҗеӣҫпјҢfigsizeиғҢжҷҜе°әеҜёпјҢfacecolorиғҢжҷҜйўңиүІ
ax.set_titleпјҡи®ҫзҪ®ж Үйўҳ
ax.barпјҡxиҪҙзҡ„еҖјпјҢyиҪҙзҡ„еҖј
ax.set_xticksпјҡxиҪҙзҡ„жҳҫзӨәй—ҙйҡ”
plt.savefigпјҡеӯҳеӮЁеӣҫеғҸ
plt.showпјҡеұ•зӨә
fig, ax = plt.subplots(1, 1, figsize=(10, 8), facecolor='white')
ax.set_title('channel {}'.format(ci))
n_bins = 100
ax.bar(range(n_bins+1), [hist_dict.get(xtick, 0) for xtick in range(n_bins+1)])
ax.set_xticks(range(0, n_bins, 5))
plt.savefig(res_path)
plt.show()ж•Ҳжһңпјҡ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңжҖҺд№Ҳз”ЁPython PandasеӨ„зҗҶCSVж–Ү件вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ





