这篇“Flink怎么使用Savepoint”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Flink怎么使用Savepoint”文章吧。
什么是 savepoint,为什么要使用 savepoint ?
保障 flink 作业在 配置迭代、flink 版本升级、蓝绿部署中的数据一致性,提高容错、降低恢复时间;
在此之前引入几个概念:
Flink 通过状态快照实现容错处理
Flink 中的状态: keyed state, operator state ..
Flink 中的状态后端:A. 状态数据如何存?B. 运行时存在哪里?C. 状态快照保存在哪?

注1:自 1.13 版本之后,设置 Working State 和 设置 Snapshot State 拆离成了两个接口,便于读者更易于理解;
StateBackend
CheckpointStorage
注2:一般默认使用 FsStateBackend,运行时状态放在堆中保障性能,快照备份时数据存于 Hdfs 保障容错性;当业务有大状态的 flink 作业存在时,可以通过配置化的方式将用户作业的状态后端设置为 RocksDBSateBackend。
Checkpoint – a snapshot taken automatically by Flink for the purpose of being able to recover from faults. Checkpoints can be incremental, and are optimized for being restored quickly.
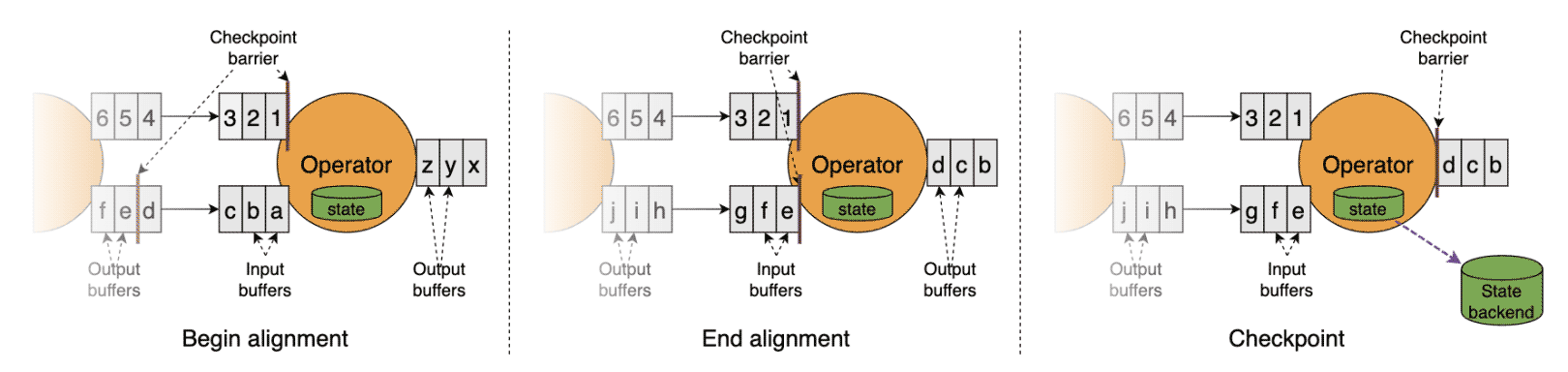
Alignment checkpoint
Unaligment checkpoint
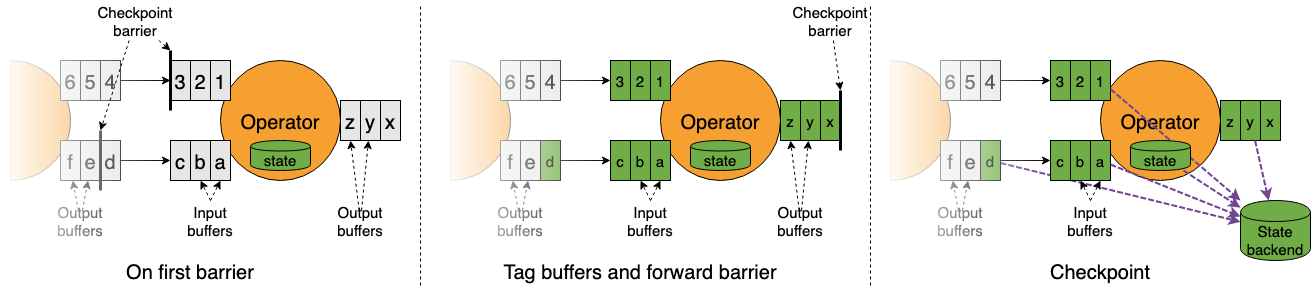
未对齐的 checkpoint 确保障碍物尽快到达接收器。
适用于至少有一条缓慢移动的数据路径的应用程序,避免对齐时间过长。然而,
会增加了额外的输入/输出压力,会造成 checkpoint size 的增加,当状态后后端 IO 有瓶颈时,不合适;
注:一般默认使用 Alignment checkpoint;当出现被压时,一般优先采用
1. 优化逻辑 2. 增加并发能力的方式进行处理;
Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。
Savepoint 是依据 Flink checkpointing 机制所创建的流作业执行状态的一致镜像;
Checkpoint 的主要目的是为意外失败的作业提供恢复机制(如 tm/jm 进程挂了)。
Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交互。
Savepoint 由用户创建,拥有和删除。 他们的用例是计划的,手动备份和恢复。
Savepoint 应用场景,升级 Flink 版本,调整用户逻辑,改变并行度,以及进行红蓝部署等。 Savepoint 更多地关注可移植性和对前面提到的作业更改的支持。
除去这些概念上的差异,Checkpoint 和 Savepoint 的当前实现基本上使用相同的代码并生成相同的格式(rocksDB 增量 checkpoint 除外,未来可能有更多类似的实现)
触发 savepoint 保留到 hdfs, 在重新调度作业时,提供给用户选择即可。
关键点:执行 savepoint 需要指定 jobId,因此在设计数据平台的元数据时,需要保留 jobId 数据。
使用 YARN 触发 Savepoint # $ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId 这将触发 ID 为 :jobId 和 YARN 应用程序 ID :yarnAppId 的作业的 Savepoint,并返回创建的 Savepoint 的路径。 使用 Savepoint 取消作业 # $ bin/flink cancel -s [:targetDirectory] :jobId 这将自动触发 ID 为 :jobid 的作业的 Savepoint,并取消该作业。此外,你可以指定一个目标文件系统目录来存储 Savepoint 。该目录需要能被 JobManager(s) 和 TaskManager(s) 访问。 从 Savepoint 恢复 # $ bin/flink run -s :savepointPath [:runArgs] 这将提交作业并指定要从中恢复的 Savepoint 。 你可以给出 Savepoint 目录或 _metadata 文件的路径。 跳过无法映射的状态恢复 # 默认情况下,resume 操作将尝试将 Savepoint 的所有状态映射回你要还原的程序。 如果删除了运算符,则可以通过 --allowNonRestoredState(short:-n)选项跳过无法映射到新程序的状态: $ bin/flink run -s :savepointPath -n [:runArgs] 删除 Savepoint # $ bin/flink savepoint -d :savepointPath 这将删除存储在 :savepointPath 中的 Savepoint。
当流处理应用程序发生错误的时候,结果可能会产生丢失或者重复。Flink 根据你为应用程序和集群的配置,可以产生以下结果:
Flink 不会从快照中进行恢复(at most once)
没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着 每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
sources 必须是可重放的,并且
sinks 必须是事务性的(或幂等的)
以上就是关于“Flink怎么使用Savepoint”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





