这篇文章主要介绍了Python之正则表达式常用语法实例分析的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Python之正则表达式常用语法实例分析文章都会有所收获,下面我们一起来看看吧。
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。 re 模块使 Python 语言拥有全部的正则表达式功能。正则表达式是一个强大的字符处理工具,其本质是一个字符序列,可以方便检查一个字符串是否与我们定义的字符序列的某种模式相匹配
在python中,正则表达式可以通过import re模块使用,本文将全面介绍正则表达式的使用方法
写在正则表达式里面的普通字符都是表示:直接匹配他们;
但是有一些特殊字符,术语metacharacters(元字符)。它们出现在正则表达式字符串中,不上表示直接匹配他们,而是表达一些特别含义
这些特殊的元字符包括下面这些:
. * + ? \ [ ] ^ $ { } | ( )
我们来分别介绍一下他们的含义:
. 表示要匹配除了换行符之外的任何单个字符
比如,你要从下面的文本中,选择所有的颜色。
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
也就是要找到所有以色结尾,并且包括前面的一个字符的词语。也就可以这样写正则表达式.色
其中点代表了任意一个字符,注意是任一个字符。
.色合起来就是表示要找到任意一个字符后面是色这个字,合起来两个字的字符串
范例:
# 导入re模块 import re #输入文本内容 content='''苹果是绿色的 橙子是橙色的 香蕉是黄色的 乌鸦是黑色的''' p=re.compile(r'.色')#r表示不要进行python语法中对字符串的转译 for one in p.findall(content): print(one)

*-表示匹配前面的子表达式任意次,包括0次
比如,你要从下面的文本中,选择每行逗号后面的字符串内容,包括逗号本身。注意,这里的逗号是文本的逗号。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
就可以这样写正则表达式,.*。
范例:
# 导入re模块 import re #输入文本内容 content='''苹果,是绿色的 橙子,是橙色的 香蕉,是黄色的 乌鸦,是黑色的 猴子,''' p=re.compile(r',.*')#r表示不要进行python语法中对字符串的转译 for one in p.findall(content): print(one)

这样就包括逗号在内的后面的字符串都匹配进来了
+表示匹配前面的子表达式一次或多次,不包括0次
比如,还是上面的例子,你要从文本中,选择每行后面的字符串,包括逗号本身。但是添加一个条件,如果逗号后面没有内容,就不要选择了。
下面的文本中最后一行逗号后面没有内容,就不要选择了
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
就可以这样写正则表达式,.+
范例:
# 导入re模块 import re #输入文本内容 content='''苹果,是绿色的 橙子,是橙色的 香蕉,是黄色的 乌鸦,是黑色的 猴子,''' p=re.compile(r',.+')#r表示不要进行python语法中对字符串的转译 for one in p.findall(content): print(one)

这样最后一行逗号后面没有内容,所以最后一行也就不会匹配
花括号表示前面的字符匹配指定的次数
比如,下面文本
红彤彤,绿油油,黑乎乎,绿油油油油
表达式油{3,4}就表示匹配连续的油字至少3次,至多4次
范例:
# 导入re模块
import re
#输入文本内容
content='''红彤彤,绿油油,黑乎乎,绿油油油油'''
p=re.compile(r'绿油{3,4}')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)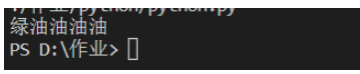
这里就匹配绿后面匹配油至少3次,至多4次的字符串
我们要把下面的字符串中的所有html标签提取出来

得到这样一个列表

很容易想到使用正则表达式<.*>
写出如下代码
# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))
但是运行结果,却是把整个字符串全部匹配上了

怎么回事?原来在正则表达式中,’*’,’+’,’?'都是贪婪的,使用他们时,会尽可能多的匹配内容,所以,<.*>中的星号(表示任意次数的重复),一直匹配到了字符串最后</tlitle>里面同样符合匹配模式。
为了解决整个问题,就需要使用非贪婪模式,也就是在星号后面加上?,变成这样<.*?>
代码改为
# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*?>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))

这样就单独去匹配出来了每一个标签
方括号表示要匹配某几种类型字符。
比如
[abc]可以匹配a,b,c里面的任意一个字符。等价于[a-c]
a-c中间的-表示一个范围从a到c
如果你想匹配所有小写字母,可以使用[a-z]
一些元字符在方括号内便失去了魔法,变得和普通字符一样了。
比如
[akm.]匹配a k m .里面的任意一个字符
在这里. 在括号不再表示匹配任意字符了,而就是表示匹配.这个字符
例如:
| 实例 | 描述 |
|---|---|
| [pP]ython | 匹配“Python”或者“python” |
| rub[ye] | 匹配“ruby”或者“rube” |
^表示匹配文本的起始位置
正则表达式可以设定单行模式和多行模式
如果是单行模式,表示匹配整个文本的开头位置。
如果是多行模式,表示匹配文本每行的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
范例:
# 导入re模块 import re #输入文本内容 source='''001-苹果-60 002-橙子-70 003-香蕉-80''' p=re.compile(r'^\d+')#r表示不要进行python语法中对字符串的转译 for one in p.findall(source): print(one)
运行结果如下

如果去掉complie的第二个参数re.M,运行结果如下

就只进行一行匹配,
因为在单行模式下,^只会匹配整个文本的开头位置
$表示匹配文本的结束位置
如果是单行模式,表示匹配整个文本的结束位置。
如果是多行模式,表示匹配文本每行的结束位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式\d+$
范例:
# 导入re模块 import re #输入文本内容 source='''001-苹果-60 002-橙子-70 003-香蕉-80''' p=re.compile(r'^\d+$',re.M)#re.M进行多行匹配 for one in p.findall(source): print(one)

成功匹配到每行最后的价格
主括号称之为正则表达式的组选择。是从正则表达式匹配的内容里面扣取出其中的某些部分
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式个^.*,。
但是,如果我们要求不要包括逗号呢?
当然不能直接这样写^.*
因为最后的逗号是特征所在,如果去掉它,就没法找逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用组选择符:括号。
我们这样写^(.*),
我们把要从整个表达式中提取的部分放在括号中,这样水果的名字就被单独的放在组group中了。
对应的Python代码如下
# 导入re模块 import re #输入文本内容 source='''苹果,苹果是绿色的 橙子,橙子是橙色的 香蕉,香蕉是黄色的''' p=re.compile(r'^(.*),',re.M)#re.M进行多行匹配 for one in p.findall(source): print(one)

这样我们就可以把,前的字符取出来了
反斜杠\在正则表达式中有多种用途
比如,我们要在下面的文本中搜索所有点前面的字符串,也包括点本身
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
如果,我们这样写正则表达式.*.,聪明的你肯定发现不对劲。
因为点是一个元字符,直接出现在正则表达式中,表示匹配任意的单个字符,不能表示.这个字符的本身的意思了
怎么办呢?
如果我们要搜索的内容本身就包含元字符,就可以使用反斜杠进行转义
这里我们就应用这样的表达式.*\.
范例:
# 导入re模块 import re #输入文本内容 source='''苹果.是绿色的 橙子.是橙色的 香蕉.是黄色的''' p=re.compile(r'.*\.')#r表示不要进行python语法中对字符串的转译 for one in p.findall(source): print(one)

成功匹配!
利用反斜杠还可以匹配某种字符类型
反斜杠后面接一些字符,表示匹配某种类型的一个字符
| 字符 | 功能 |
|---|---|
| \d | 匹配0~9之间的任意一个数字字符,等价于表达式[0-9] |
| \D | 匹配任意一个不上0-9之间的数字字符,等价于表达是[^0-9] |
| \s | 匹配任意一个空白字符,包括空格、tab、换行符等、等价于[\t\n\r\f\v] |
| \S | 匹配任意一个非空白字符,等价于[^\t\tn\r\f\v] |
| \w | 匹配任意一个文字字符,包括大小写、数字、下划线、等于[a-zA-A0-9] |
| \W | 匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9] |
反斜杠也可以用在方括号里面,比如[\s,.]:表示匹配任何空白字符,或者逗号,或者点
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(I)它们来指定。如re.l | re.M被设置成Ⅰ和M标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响lw,W,Nb,\B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
字符串对象的split()方法只适应于非常简单的字符串分割情形。当你需要更加灵活的切割字符串的时候,就不好用了。
比如,我们需要从下面字符串中提取武将的名字。
我们发现这些名字之间,有的是分号隔开,有的是逗号隔开,有的是空格隔开,而且分割符号周围还有不定数量的空格
names =“关羽;张飞,赵云,马超,黄忠 李逵”
这时,最好使用正则表达式里面的split方法:
范例:
# 导入re模块 import re #输入文本内容 names ="关羽;张飞,赵云,马超,黄忠 李逵" namelist=re.split(r'[;,\s]\s*',names) print(namelist)

正则表达式[;,ls]\s*指定了,分割符为分号、逗号、空格里面的任意一种均可,并且该符号周围可以有不定数量的空格。
关于“Python之正则表达式常用语法实例分析”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Python之正则表达式常用语法实例分析”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





