这篇文章主要介绍了怎么使用Python数据可视化制作全球地震散点图的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇怎么使用Python数据可视化制作全球地震散点图文章都会有所收获,下面我们一起来看看吧。
首先我们先打开下载好的数据集浏览一下:

你会发现其中的数据密密麻麻,根本不是人读的,因此,接下来我们将对数据进行处理,让它变得简单易读。
import json#导入json模块,以便于加载文件中的数据 filename='eq_data_1_day_m1.json' with open(filename) as f: all_eq_data=json.load(f)#json.load(),将数据转化为Python能够处理的格式 readable_file='eq_data_1_day_m1.json'#创建一个文件,以便将这些数据以易于阅读的方式写入其中 with open(readable_file,'w') as f: json.dump(all_eq_data,f,indent=4)#json.dump()将数据读入其中 #参数indent让dump()使用与数据结构匹配的缩进量来设置数据的格式
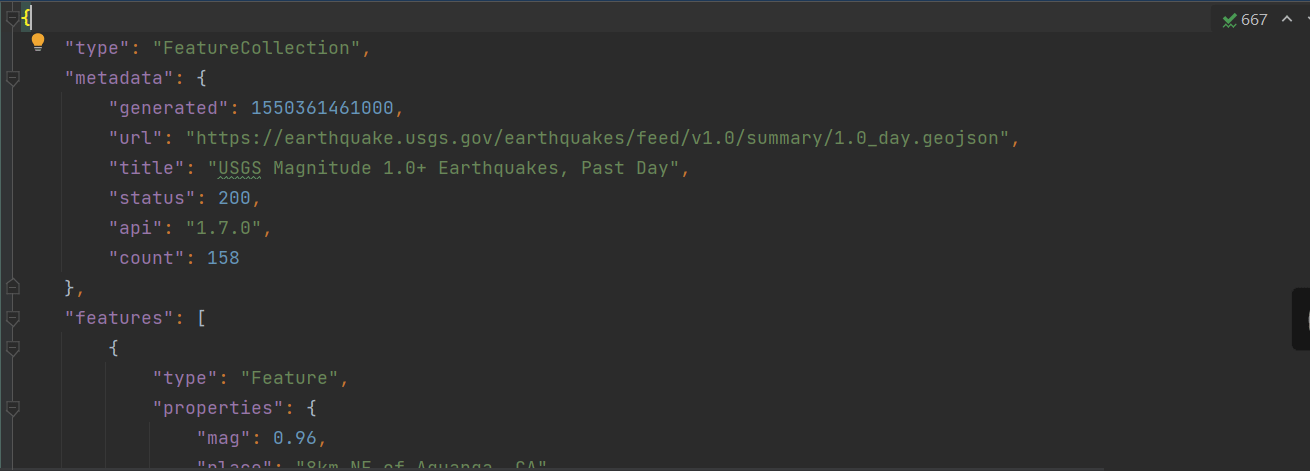
经过处理之后,我们再打开这个文件会发现里面的数据变得清晰了许多。
从中我们能够快速获取数据的很多信息,比如地震的次数,类型等等,不仅如此,我们还能够知道有关这些数据的一些信息,比如,它的生成时间,他在网页上怎么获取等等。
如果indent是非负整数或字符串,则JSON数组元素和对象成员将使用该缩进级别进行打印。如果indent为0,负数或“”只会插入换行符。
None(默认)则选择最紧凑的表示形式。,使用正整数缩进会使每个级别缩进多个空格。,如果缩进是字符串(例如“
t”),则该字符串用于缩进每个级别。
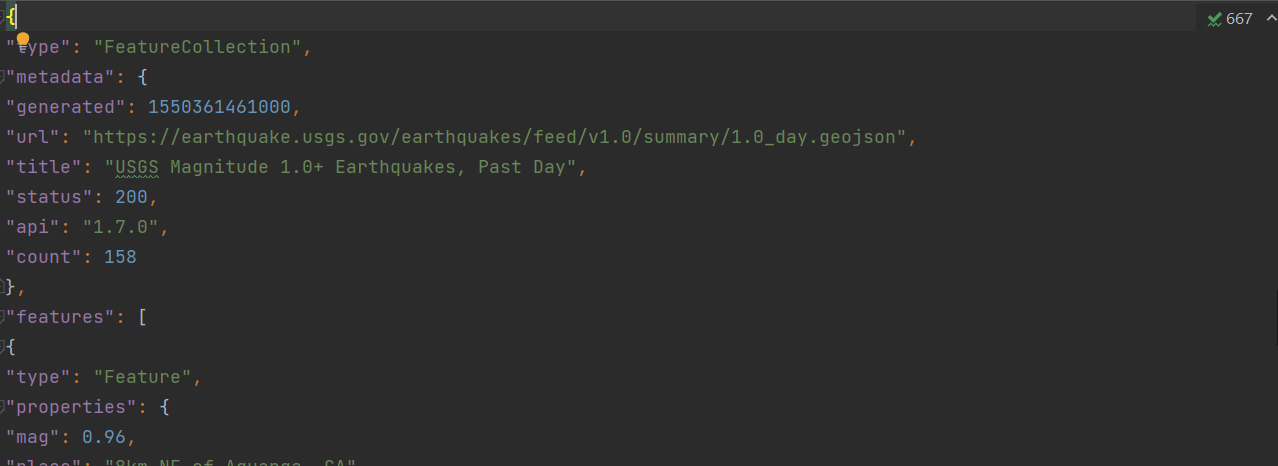
当我们将缩进量修改为0时,文件的排版也会发生变化:
json.dump(all_eq_data,f,indent=0)
import json filename='eq_data_1_day_m1.json' with open(filename) as f: all_eq_data=json.load(f)#对文件进行处理 all_eq_dicts=all_eq_data['features'] print(len(all_eq_dicts))#提取出这个文件记录的所有地震
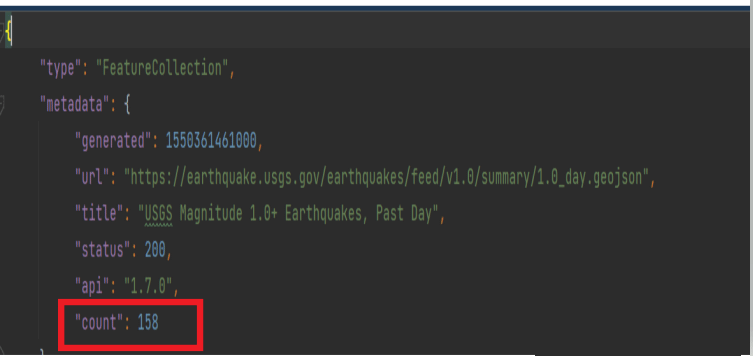
输出结果如下:
158
是的,从文件的开头,我们就可以确定地震的次数为158次,因此输出结果正确:
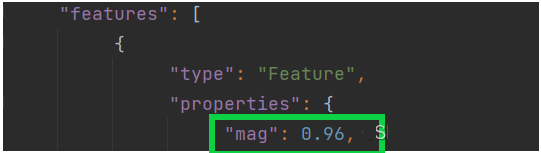
方法即是新建立一个列表用来存放震源的有关数据,再提取字典features的properties部分的mag.
代码如下:
import json filename='eq_data_1_day_m1.json' with open(filename) as f: all_eq_data=json.load(f) all_eq_dicts=all_eq_data['features'] mags=[] for eq_dict in all_eq_dicts: mag=eq_dict['properties']['mag'] mags.append(mag) print(mags[:10])#打印前十次的震级数据
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
首先,我们需要在文件中找到关于经度和维度的部分,如下所示,我们在文件中查找到,它是存在于geometry字典下,coordinates键中的。
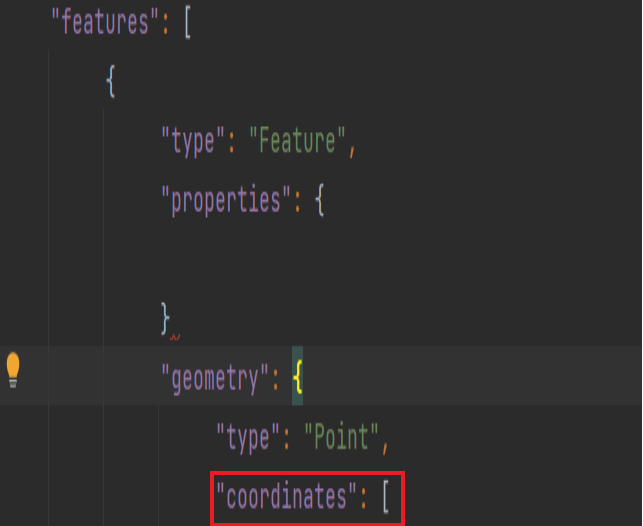
---snip--- all_eq_dicts=all_eq_data['features'] mags,titles,lons,lats=[],[],[],[] for eq_dict in all_eq_dicts: mag=eq_dict['properties']['mag'] title=eq_dict['properties']['title'] lon=eq_dict['geometry']['coordinates'][0]#提取coordinates键中索引值为0的数据 lat=eq_dict['geometry']['coordinates'][1] mags.append(mag) titles.append(title) lons.append(lon) lats.append(lat) print(mags[:10]) print(titles[:2]) print(lons[:5])#输出前五个经度 print(lats[:5])#输出前五个维度
输出结果如下:
[0.96, 1.2, 4.3, 3.6, 2.1, 4, 1.06, 2.3, 4.9, 1.8]
['M 1.0 - 8km NE of Aguanga, CA', 'M 1.2 - 11km NNE of North Nenana, Alaska']
[-116.7941667, -148.9865, -74.2343, -161.6801, -118.5316667]
[33.4863333, 64.6673, -12.1025, 54.2232, 35.3098333]
通过我们前面提取的有关震源的数据,下面我们可对提取的数据进行可视化作图:
import plotly.express as px#Plotly Express是Plotly的高级接口,相当于Matplotlib是一个工具
fig=px.scatter(
x=lons,
y=lats,
labels={'x':'经度','y':'维度'},
range_x=[-200,200],
range_y=[-90,90],
#width和height代表图表的高度和宽度均为800像素
width=800,
height=800,
title="全球地震散点图",
)
fig.write_html('global_earthquakes.html')#将可视化图保存为html文件
fig.show()散点图配置完成后,下面我们在程序目录下寻找我们保存的可视化图(global_earthquakes.html),再使用浏览器打开该html文件
如下所示,即为散点图:
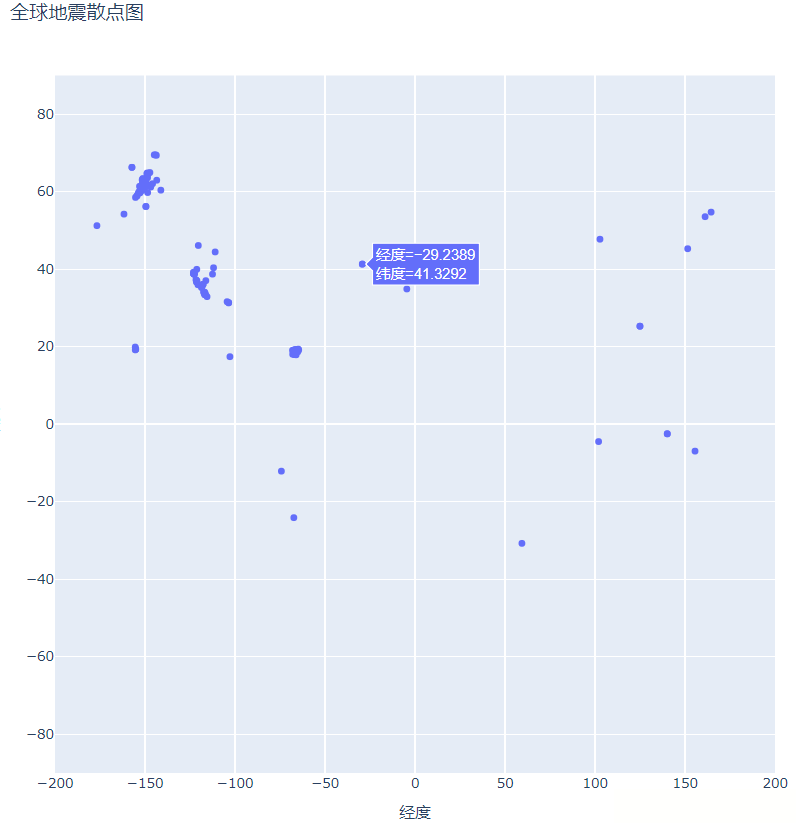
上面我们绘制地震散点图是通过手动配置经纬度,通过将x,y和经度,纬度建立联系:
x=lons,
y=lats,
labels={'x':'经度','y':'维度'},但这在数据处理过程中并不是最简单的方式,下面我们介绍另一种图表指定数据的方式,需要结合我们上面所提到的pandas数据分析工具。
import pandas as pd#导入pandas模块x data=pd.DataFrame(data=zip(lons,lats,titles,mags),colums=['经度','纬度','位置','震级'])#使用DataFrame将需要处理的数据封装,注意:DataFrame后面的两个参数是可选的,如果这两个参数存在的话,这两个参数的长度要和DataFrame的长度匹配 #zip()函数的作用:将可迭代的对象中的对应元素打包为多个元祖,再返回由这些元祖组成的列表 data.head()
它是Python中pandas库中的一种数据结构,和excel比较相似,它不仅可以设置列名columns和行名index,而且它的单元格可以存放数值,字符串等。
data.head():返回数据的前几行数据,默认是前五行,如果需要指定则写data.head(‘指定的行数’)
data.tail():返回data的后几行数据,默认为后五行,如果需要指定则写data.tail(‘指定的行数’)
数据封装好之后,参数的配置方式可修改为:
data, x='经度', y='纬度',
现在我们通过这种参数配置方式进行地震散点图的绘制:
#创建地震列表,提取数据
import json
filename='eq_data_1_day_m1.json'
with open(filename) as f:
all_eq_data=json.load(f)
all_eq_dicts=all_eq_data['features']
mags,titles,lons,lats=[],[],[],[]
for eq_dict in all_eq_dicts:
mag=eq_dict['properties']['mag']
title=eq_dict['properties']['title']
lon=eq_dict['geometry']['coordinates'][0]#提取coordinates键中索引值为0的数据
lat=eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
#参数配置设置
import pandas as pd
data=pd.DataFrame(
data=zip(lons,lats,titles,mags),columns=['经度','纬度','位置','震级']
)
data.head()
#绘制散点图
import plotly.express as px
fig = px.scatter(
data,
x='经度',
y='纬度',
range_x=[-200, 200],
range_y=[-90, 90],
width=800,
height=800,
title="全球地震散点图",
)
fig.write_html('global_earthquake.html')
fig.show()配置完成后,下面我们在程序目录下寻找我们保存的可视化图(global_earthquakes.html),再使用浏览器打开该html文件如下图所示:
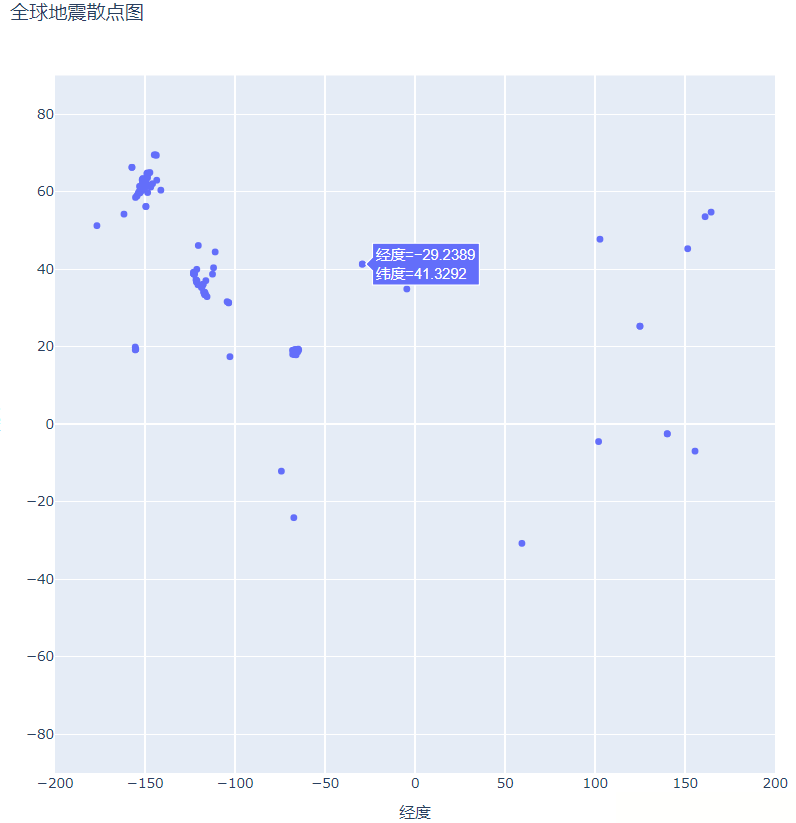
通过输出结果,我们可得出,无论使用那种参数配置方式,其输出结果都是相同的,但第二种这种以键值对的方式,更加清晰。
和我们上篇文章提到的与温度有关的散点图相类似,我们希望知道最高温度和最低温度等这些特殊且重要的信息,那么震源散点图也是如此,上图我们所设计的震源散点图只是将纬度和经度在图上呈现出来了,但震源并没有体现。
下面,我们将震级也呈现在散点图上:
方法:使用size参数设计散点图中每个尺寸的大小:
size='震级', size_max=10,
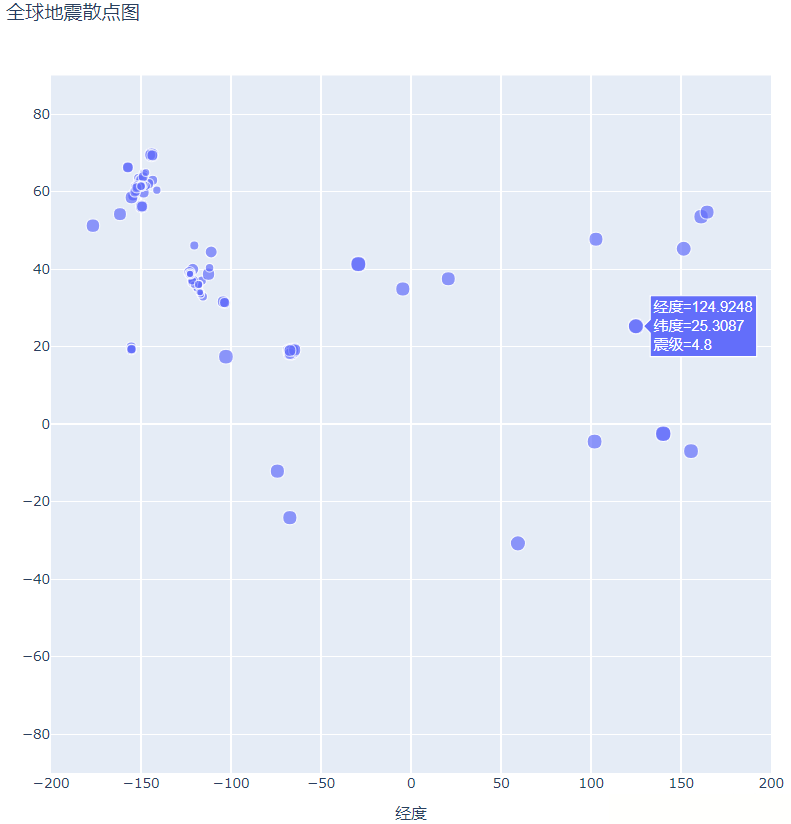
对比上面的两幅图,我们会发现散点图中关于地震的信息还增加了震级,不仅如此,散点的尺寸大小也与震级的大小有关,震级越大,散点的尺寸越大,这样一来,我们很容易观察到不同地方的地震强度,但这还不够直观,为了能够更加直白的呈现地震的情况,我们还设计散点的颜色以便更加清晰的显示。
方法:
color='震级', #默认渐变色的范围是从蓝到红再到黄,数值越小标记越蓝,而数值越大则标记越黄。
把在网上下载好的近30天的数据文件复制到该程序目录下,将参数color添加其中,再绘制散点图。,注意修改文件名。
如下图所示:
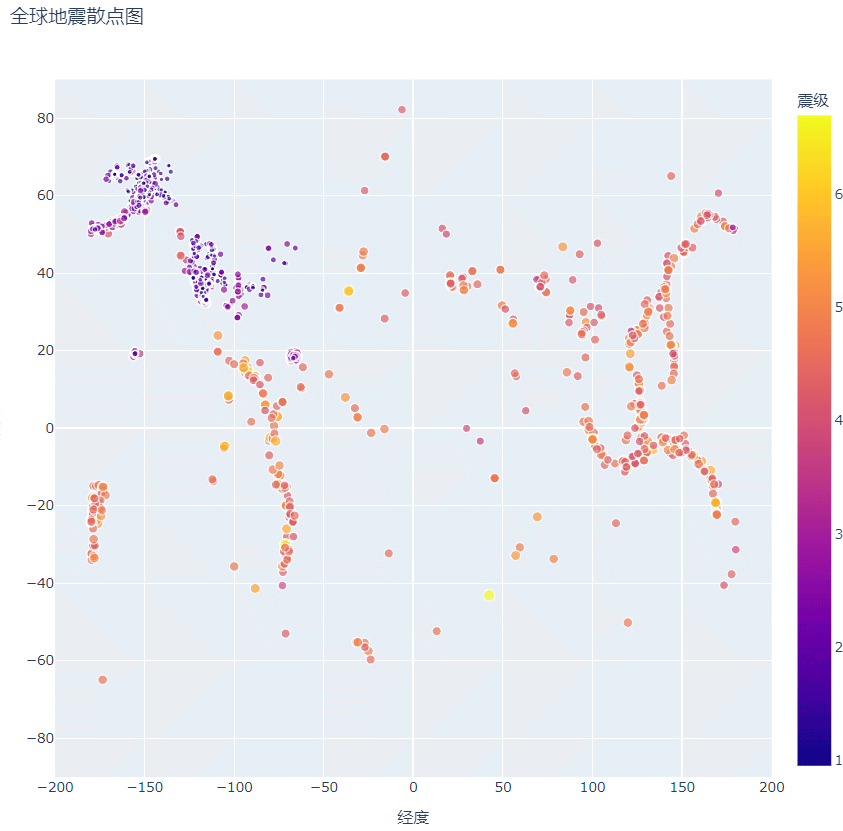
美化后的散点图,不仅在颜色上漂亮了许多,渐变的颜色也更加清晰的反映了地震的严重程度。
获取Plotly Express中所有的渐变色:
不仅如此,Plotly Express还为我们提供了许多的渐变色,而这些渐变色是在px.colors.named_colorscales()中定义的,下面来获取这些渐变色:
import plotly.express as px for key in px.colors.named_colorscales(): print(key,end='/')
输出结果如下:
aggrnyl/agsunset/blackbody/bluered/blues/blugrn/bluyl/brwnyl/bugn/bupu/burg/burgyl/cividis
/darkmint/electric/emrld/gnbu/greens/greys/hot/inferno/jet/magenta/magma/mint/orrd/oranges
/oryel/peach/pinkyl/plasma/plotly3/pubu/pubugn/purd/purp/purples/purpor/rainbow/rdbu/rdpu
/redor/reds/sunset/sunsetdark/teal/tealgrn/turbo/viridis/ylgn/ylgnbu/ylorbr/ylorrd/algae
/amp/deep/dense/gray/haline/ice/matter/solar/speed/tempo/thermal/turbid/armyrose/brbg/earth
/fall/geyser/prgn/piyg/picnic/portland/puor/rdgy/rdylbu/rdylgn/spectral/tealrose/temps/tropic
/balance/curl/delta/oxy/edge/hsv/icefire/phase/twilight/mrybm/mygbm/
此外,我们还可将对应配色列表进行反转:
方法:
px.colors.diverging.RdYlGn[::-1]
此外,Plotly除了有px.colors.diverging表示连续的配色方案,还有px.colors.sequential和px.colors.qualitative表示离散变量。每个渐变色都有起始色和终止色,有些渐变色还定义了一个或多个中间色。
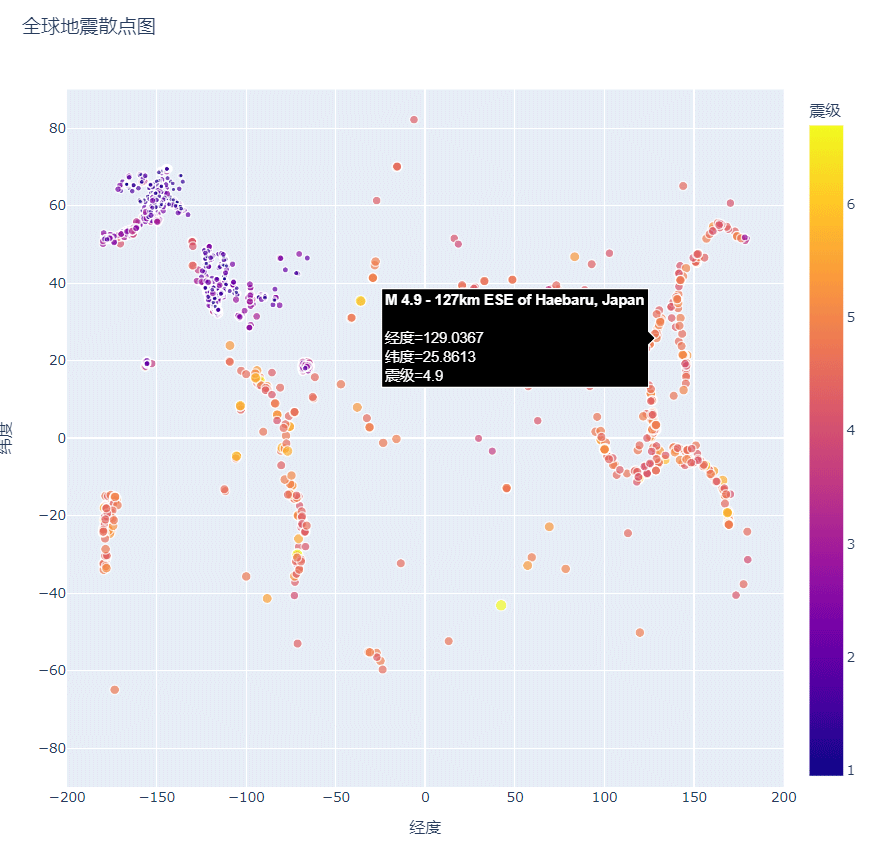
添加鼠标指向时显示的文本:
方法,使用参数hover_name,参数配置为data的‘位置’
hover_name='位置',
修改后,散点图的输出如下所示:
关于“怎么使用Python数据可视化制作全球地震散点图”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“怎么使用Python数据可视化制作全球地震散点图”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





