C++11зәҝзЁӢгҖҒдә’ж–ҘйҮҸеҸҠжқЎд»¶еҸҳйҮҸжҖҺд№ҲеҲӣе»ә
иҝҷзҜҮвҖңC++11зәҝзЁӢгҖҒдә’ж–ҘйҮҸеҸҠжқЎд»¶еҸҳйҮҸжҖҺд№ҲеҲӣе»әвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңC++11зәҝзЁӢгҖҒдә’ж–ҘйҮҸеҸҠжқЎд»¶еҸҳйҮҸжҖҺд№ҲеҲӣе»әвҖқж–Үз« еҗ§гҖӮ
еүҚиЁҖ
C++11д№ӢеүҚпјҢC++иҜӯиЁҖжІЎжңүеҜ№е№¶еҸ‘зј–зЁӢжҸҗдҫӣиҜӯиЁҖзә§еҲ«зҡ„ж”ҜжҢҒпјҢиҝҷдҪҝеҫ—жҲ‘们еңЁзј–зЁӢеҶҷеҸҜ移жӨҚзҡ„并еҸ‘зЁӢеәҸж—¶пјҢеӯҳеңЁиҜёеӨҡдёҚдҫҝгҖӮзҺ°еңЁC++11еўһеҠ дәҶзәҝзЁӢд»ҘеҸҠзәҝзЁӢзӣёе…ізҡ„зұ»пјҢеҫҲж–№дҫҝең°ж”ҜжҢҒдәҶ并еҸ‘зј–зЁӢпјҢдҪҝеҫ—зј–еҶҷеӨҡзәҝзЁӢзЁӢеәҸзҡ„еҸҜ移жӨҚжҖ§еҫ—еҲ°дәҶеҫҲеӨ§зҡ„жҸҗй«ҳ
1гҖҒеҲӣе»ә第дёҖдёӘзәҝзЁӢ
//еҲӣе»әзәҝзЁӢйңҖиҰҒеј•е…ҘеӨҙж–Ү件thread
#include<thread>
#include<iostream>
void ThreadMain()
{
cout << "begin thread main" << endl;
}
int main()
{
//еҲӣе»әж–°зәҝзЁӢt并еҗҜеҠЁ
thread t(ThreadMain);
//дё»зәҝзЁӢ(mainзәҝзЁӢ)зӯүеҫ…tжү§иЎҢе®ҢжҜ•
if (t.joinable()) //еҝ…дёҚеҸҜе°‘
{
//зӯүеҫ…еӯҗзәҝзЁӢйҖҖеҮә
t.join(); //еҝ…дёҚеҸҜе°‘
}
return 0;
}жҲ‘们йғҪзҹҘйҒ“пјҢеҜ№дәҺдёҖдёӘеҚ•зәҝзЁӢжқҘиҜҙпјҢд№ҹе°ұmainзәҝзЁӢжҲ–иҖ…еҸ«еҒҡдё»зәҝзЁӢпјҢжүҖжңүзҡ„е·ҘдҪңйғҪжҳҜз”ұmainзәҝзЁӢеҺ»е®ҢжҲҗзҡ„гҖӮиҖҢеңЁеӨҡзәҝзЁӢзҺҜеўғдёӢпјҢеӯҗзәҝзЁӢеҸҜд»ҘеҲҶжӢ…mainзәҝзЁӢзҡ„е·ҘдҪңеҺӢеҠӣпјҢеңЁеӨҡдёӘCPUдёӢпјҢе®һзҺ°зңҹжӯЈзҡ„并иЎҢж“ҚдҪңгҖӮ
еңЁдёҠиҝ°д»Јз ҒдёӯпјҢеҸҜд»ҘзңӢеҲ°mainзәҝзЁӢеҲӣе»ә并еҗҜеҠЁдәҶдёҖдёӘж–°зәҝзЁӢtпјҢз”ұж–°зәҝзЁӢtеҺ»жү§иЎҢThreadMain()еҮҪж•°пјҢjionеҮҪж•°е°ҶдјҡжҠҠmainзәҝзЁӢйҳ»еЎһдҪҸпјҢзҹҘйҒ“ж–°зәҝзЁӢtжү§иЎҢз»“жқҹпјҢеҰӮжһңж–°зәҝзЁӢtжңүиҝ”еӣһеҖјпјҢиҝ”еӣһеҖје°Ҷдјҡиў«еҝҪз•Ҙ
жҲ‘们еҸҜд»ҘйҖҡиҝҮеҮҪж•°this_thread::get_id()жқҘеҲӨж–ӯжҳҜtзәҝзЁӢиҝҳжҳҜmainзәҝзЁӢжү§иЎҢд»»еҠЎ
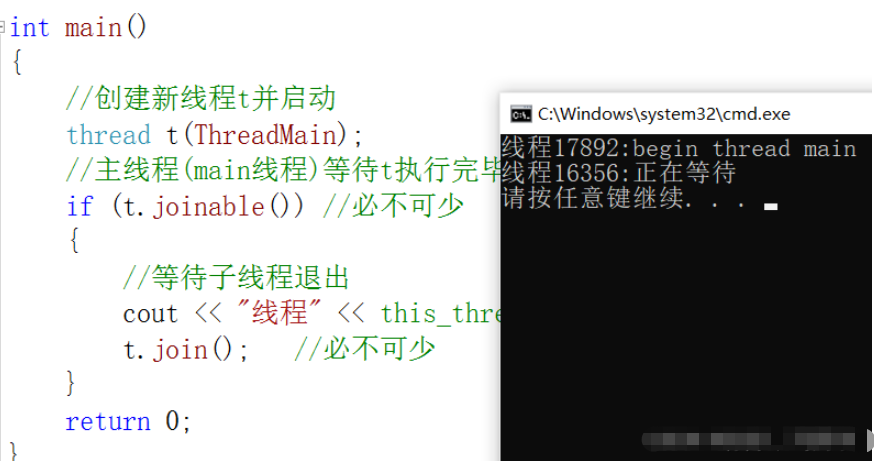
void ThreadMain()
{
cout << "зәҝзЁӢ" << this_thread::get_id()<< ":begin thread main" << endl;
}
int main()
{
//еҲӣе»әж–°зәҝзЁӢt并еҗҜеҠЁ
thread t(ThreadMain);
//дё»зәҝзЁӢ(mainзәҝзЁӢ)зӯүеҫ…tжү§иЎҢе®ҢжҜ•
if (t.joinable()) //еҝ…дёҚеҸҜе°‘
{
//зӯүеҫ…еӯҗзәҝзЁӢйҖҖеҮә
cout << "зәҝзЁӢ" << this_thread::get_id() << ":жӯЈеңЁзӯүеҫ…" << endl;
t.join(); //еҝ…дёҚеҸҜе°‘
}
return 0;
}жү§иЎҢз»“жһңпјҡ
2гҖҒзәҝзЁӢеҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖҒзӯүеҫ…е’ҢеҲҶзҰ»
void func()
{
cout << "do func" << endl;
}
int main()
{
thread t(func);
return 0;
}дёҠиҜүд»Јз ҒиҝҗиЎҢеҸҜиғҪдјҡжҠӣеҮәејӮеёёпјҢеӣ дёәзәҝзЁӢеҜ№иұЎtеҸҜиғҪе…ҲдәҺзәҝзЁӢеҮҪж•°funcз»“жқҹпјҢеә”иҜҘдҝқиҜҒзәҝзЁӢеҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹеңЁзәҝзЁӢеҮҪж•°funcжү§иЎҢе®Ңж—¶д»Қ然еӯҳеңЁ
дёәдәҶйҳІжӯўзәҝзЁӢеҜ№иұЎзҡ„з”ҹе‘Ҫе‘Ёжңҹж—©дәҺзәҝзЁӢеҮҪж•°funз»“жқҹпјҢеҸҜд»ҘдҪҝз”ЁзәҝзЁӢзӯүеҫ…join
void func()
{
while (true)
{
cout << "do work" << endl;
this_thread::sleep_for(std::chrono::seconds(1));//еҪ“еүҚзәҝзЁӢзқЎзң 1з§’
}
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();//mainзәҝзЁӢйҳ»еЎһ
}
return 0;
}иҷҪ然дҪҝз”ЁjoinиғҪжңүж•ҲйҳІжӯўзЁӢеәҸзҡ„еҙ©жәғпјҢдҪҶжҳҜеңЁжҹҗдәӣжғ…еҶөдёӢпјҢжҲ‘们并дёҚеёҢжңӣmainзәҝзЁӢйҖҡиҝҮjoinиў«йҳ»еЎһеңЁеҺҹең°пјҢжӯӨж—¶еҸҜд»ҘйҮҮз”ЁdetachиҝӣиЎҢзәҝзЁӢеҲҶзҰ»гҖӮдҪҶжҳҜйңҖиҰҒжіЁж„Ҹпјҡdetachд№ӢеҗҺmainзәҝзЁӢе°ұж— жі•еҶҚе’ҢеӯҗзәҝзЁӢеҸ‘з”ҹиҒ”зі»дәҶпјҢжҜ”еҰӮdetachд№ӢеҗҺе°ұдёҚиғҪеҶҚйҖҡиҝҮjoinжқҘзӯүеҫ…еӯҗзәҝзЁӢпјҢеӯҗзәҝзЁӢд»»дҪ•жү§иЎҢе®ҢжҲ‘们д№ҹж— жі•жҺ§еҲ¶дәҶ
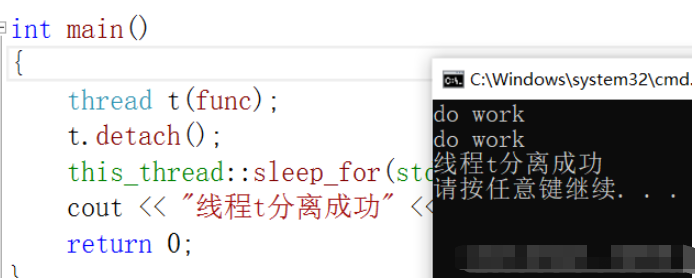
void func()
{
int count = 0;
while (count < 3)
{
cout << "do work" << endl;
count++;
this_thread::sleep_for(std::chrono::seconds(1));//еҪ“еүҚзәҝзЁӢзқЎзң 1з§’
}
}
int main()
{
thread t(func);
t.detach();
this_thread::sleep_for(std::chrono::seconds(1));//еҪ“еүҚзәҝзЁӢзқЎзң 1з§’
cout << "зәҝзЁӢtеҲҶзҰ»жҲҗеҠҹ" << endl;
return 0;
}жү§иЎҢз»“жһңпјҡ
3гҖҒзәҝзЁӢеҲӣе»әзҡ„еӨҡз§Қж–№ејҸ
зәҝзЁӢзҡ„еҲӣе»әе’Ңжү§иЎҢпјҢж— йқһжҳҜз»ҷзәҝзЁӢжҢҮе®ҡдёҖдёӘе…ҘеҸЈеҮҪж•°еҳӣпјҢдҫӢеҰӮmainзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°е°ұmain()еҮҪж•°пјҢеүҚйқўзј–еҶҷзҡ„еӯҗзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°жҳҜдёҖдёӘе…ЁеұҖеҮҪж•°гҖӮйҷӨдәҶиҝҷдәӣд№ӢеӨ–зәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°иҝҳеҸҜд»ҘжҳҜеҮҪж•°жҢҮй’ҲгҖҒд»ҝеҮҪж•°гҖҒзұ»зҡ„жҲҗе‘ҳеҮҪж•°гҖҒlambdaиЎЁиҫҫејҸзӯүпјҢе®ғ们йғҪжңүдёҖдёӘе…ұеҗҢзҡ„зү№зӮ№пјҡйғҪжҳҜеҸҜи°ғз”ЁеҜ№иұЎгҖӮзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°жҢҮе®ҡпјҢеҸҜд»Ҙдёәд»»ж„ҸдёҖдёӘеҸҜи°ғз”ЁеҜ№иұЎгҖӮ
жҷ®йҖҡеҮҪж•°дҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
void func()
{
cout << "hello world" << endl;
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();
}
return 0;
}зұ»зҡ„жҲҗе‘ҳеҮҪж•°дҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
class ThreadMain
{
public:
ThreadMain() {}
virtual ~ThreadMain(){}
void SayHello(std::string name)
{
cout << "hello " << name << endl;
}
};
int main()
{
ThreadMain obj;
thread t(&ThreadMain::SayHello, obj, "fl");
thread t1(&ThreadMain::SayHello, &obj, "fl");
t.join();
t1.join();
return 0;
}tе’Ңt1еңЁдј йҖ’еҸӮж•°ж—¶еӯҳеңЁдёҚеҗҢпјҡ
tжҳҜз”ЁеҜ№иұЎobjи°ғз”ЁзәҝзЁӢеҮҪж•°зҡ„иҜӯеҸҘпјҢеҚізәҝзЁӢеҮҪж•°е°ҶеңЁobjеҜ№иұЎзҡ„дёҠдёӢж–ҮдёӯиҝҗиЎҢгҖӮиҝҷйҮҢobjжҳҜйҖҡиҝҮеҖјдј йҖ’з»ҷзәҝзЁӢжһ„йҖ еҮҪж•°зҡ„пјҢеӣ жӯӨеңЁзәҝзЁӢдёӯдҪҝз”Ёзҡ„жҳҜеҜ№иұЎobjзҡ„дёҖдёӘеүҜжң¬гҖӮиҝҷз§Қж–№ејҸйҖӮз”ЁдәҺзұ»е®ҡд№үеңЁеұҖйғЁдҪңз”Ёеҹҹдёӯж—¶пјҢйңҖиҰҒе°Ҷе…¶дј йҖ’з»ҷзәҝзЁӢзҡ„жғ…еҶөгҖӮ
t1жҳҜдҪҝз”ЁеҜ№иұЎзҡ„жҢҮй’Ҳ&objи°ғз”ЁзәҝзЁӢеҮҪж•°зҡ„иҜӯеҸҘпјҢеҚізәҝзЁӢеҮҪж•°е°ҶеңЁеҜ№иұЎobjзҡ„жҢҮй’ҲжүҖжҢҮеҗ‘зҡ„дёҠдёӢж–ҮдёӯиҝҗиЎҢгҖӮиҝҷйҮҢдҪҝз”Ёзҡ„жҳҜеҜ№иұЎobjзҡ„жҢҮй’ҲпјҢеӣ жӯӨеңЁзәҝзЁӢдёӯдҪҝз”Ёзҡ„жҳҜеҺҹе§Ӣзҡ„objеҜ№иұЎгҖӮиҝҷз§Қж–№ејҸйҖӮз”ЁдәҺзұ»е®ҡд№үеңЁе…ЁеұҖжҲ–йқҷжҖҒдҪңз”Ёеҹҹдёӯж—¶пјҢйңҖиҰҒе°Ҷе…¶дј йҖ’з»ҷзәҝзЁӢзҡ„жғ…еҶөгҖӮ
еҰӮжһңйңҖиҰҒеңЁзұ»зҡ„жҲҗе‘ҳеҮҪж•°дёӯпјҢеҲӣе»әзәҝзЁӢпјҢд»Ҙзұ»дёӯзҡ„еҸҰдёҖдёӘжҲҗе‘ҳеҮҪж•°дҪңдёәе…ҘеҸЈеҮҪж•°пјҢеҶҚжү§иЎҢ
class ThreadMain
{
public:
ThreadMain() {}
virtual ~ThreadMain(){}
void SayHello(std::string name)
{
cout << "hello " << name << endl;
}
void asycSayHello(std::string name)
{
thread t(&ThreadMain::SayHello, this, name);
if (t.joinable())
{
t.join();
}
}
};
int main()
{
ThreadMain obj;
obj.asycSayHello("fl");
return 0;
}еңЁasycSayHelloзҡ„жҲҗе‘ҳеҮҪж•°дёӯпјҢеҰӮжһңжІЎжңүдј йҖ’thisжҢҮй’ҲпјҢдјҡеҜјиҮҙзј–иҜ‘дёҚйҖҡиҝҮ
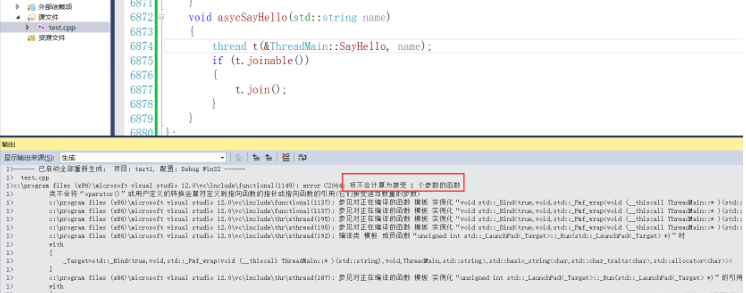
еҺҹеӣ е°ұжҳҜеҸӮж•°еҲ—иЎЁдёҚеҢ№й…ҚпјҢеӣ жӯӨйңҖиҰҒжҲ‘们жҳҫзӨәзҡ„дј йҖ’thisжҢҮй’ҲпјҢиЎЁзӨәд»Ҙжң¬еҜ№иұЎзҡ„жҲҗе‘ҳеҮҪж•°дҪңдёәеҸӮж•°зҡ„е…ҘеҸЈеҮҪж•°
lambdaиЎЁиҫҫејҸдҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
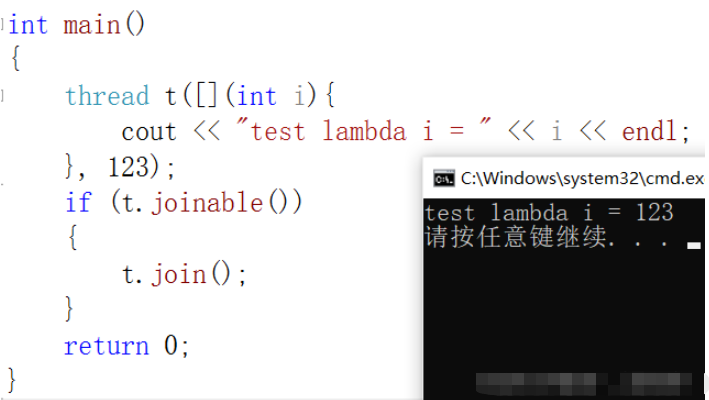
int main()
{
thread t([](int i){
cout << "test lambda i = " << i << endl;
}, 123);
if (t.joinable())
{
t.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ
еңЁзұ»зҡ„жҲҗе‘ҳеҮҪж•°дёӯпјҢд»ҘlambdaиЎЁиҫҫејҸдҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
class TestLmadba
{
public:
void Start()
{
thread t([this](){
cout << "name is " << this->name << endl;
});
if (t.joinable())
{
t.join();
}
}
private:
std::string name = "fl";
};
int main()
{
TestLmadba test;
test.Start();
return 0;
}еңЁзұ»зҡ„жҲҗе‘ҳеҮҪж•°дёӯпјҢд»ҘlambdaиЎЁиҫҫејҸдҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°пјҢеҰӮжһңйңҖиҰҒи®ҝй—®е…‘зҺ°зҡ„жҲҗе‘ҳеҸҳйҮҸпјҢд№ҹйңҖиҰҒдј йҖ’thisжҢҮй’Ҳ
д»ҝеҮҪж•°дҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
class Mybusiness
{
public:
Mybusiness(){}
virtual ~Mybusiness(){}
void operator()(void)
{
cout << "Mybusiness thread id is " << this_thread::get_id() << endl;
}
void operator()(string name)
{
cout << "name is " << name << endl;
}
};
int main()
{
Mybusiness mb;
thread t(mb);
if (t.joinable())
{
t.join();
}
thread t1(mb, "fl");
if (t1.joinable())
{
t1.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ

зәҝзЁӢtд»Ҙж— еҸӮзҡ„д»ҝеҮҪж•°дҪңдёәеҮҪж•°е…ҘеҸЈпјҢиҖҢзәҝзЁӢt1д»ҘжңүеҸӮзҡ„д»ҝеҮҪж•°дҪңдёәеҮҪж•°е…ҘеҸЈ
еҮҪж•°жҢҮй’ҲдҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
void func()
{
cout << "thread id is " << this_thread::get_id() << endl;
}
void add(int a, int b)
{
cout << a << "+" << b << "=" << a + b << endl;
}
int main()
{
//йҮҮз”ЁC++11жү©еұ•зҡ„usingжқҘе®ҡд№үеҮҪж•°жҢҮй’Ҳзұ»еһӢ
using FuncPtr = void(*)();
using FuncPtr1 = void(*)(int, int);
//дҪҝз”ЁFuncPtrжқҘе®ҡд№үеҮҪж•°жҢҮй’ҲеҸҳйҮҸ
FuncPtr ptr = &func;
thread t(ptr);
if (t.joinable())
{
t.join();
}
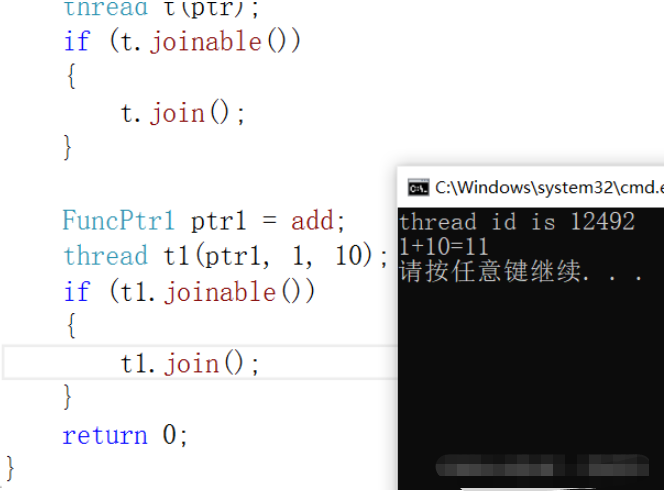
FuncPtr1 ptr1 = add;
thread t1(ptr1, 1, 10);
if (t1.joinable())
{
t1.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ
functionе’ҢbindдҪңдёәзәҝзЁӢзҡ„е…ҘеҸЈеҮҪж•°
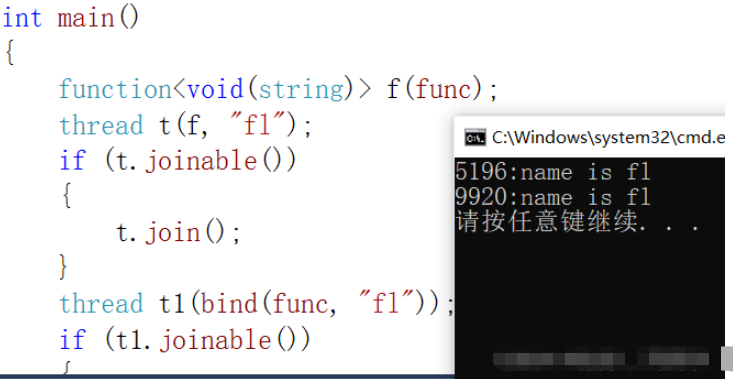
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
function<void(string)> f(func);
thread t(f, "fl");
if (t.joinable())
{
t.join();
}
thread t1(bind(func, "fl"));
if (t1.joinable())
{
t1.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ
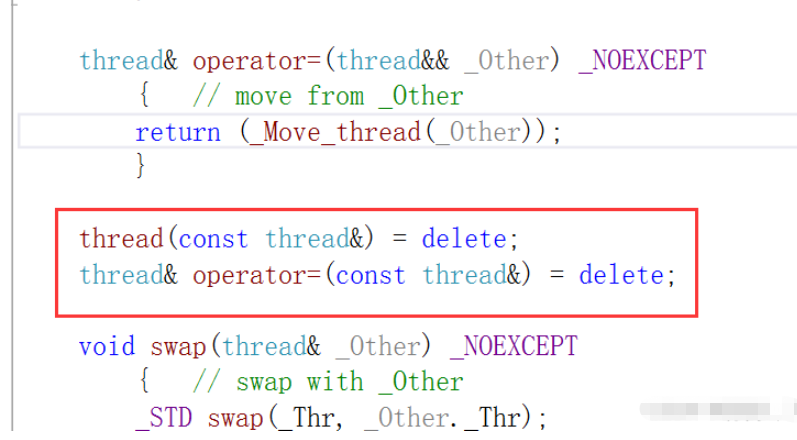
зәҝзЁӢдёҚиғҪжӢ·иҙқе’ҢеӨҚеҲ¶пјҢдҪҶеҸҜд»Ҙ移еҠЁ
//иөӢеҖјж“ҚдҪң
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
thread t1(func, "fl");
thread t2 = t1;
thread t3(t1);
return 0;
}зј–иҜ‘жҠҘй”ҷпјҡ

еңЁзәҝзЁӢеҶ…йғЁпјҢе·Із»Ҹе°ҶзәҝзЁӢзҡ„иөӢеҖје’ҢжӢ·иҙқж“ҚдҪңdeleteжҺүдәҶпјҢжүҖд»Ҙж— жі•и°ғз”ЁеҲ°
//移еҠЁж“ҚдҪң
void func(string name)
{
cout << this_thread::get_id() << ":name is " << name << endl;
}
int main()
{
thread t1(func, "fl");
thread t2(std::move(t1));
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ
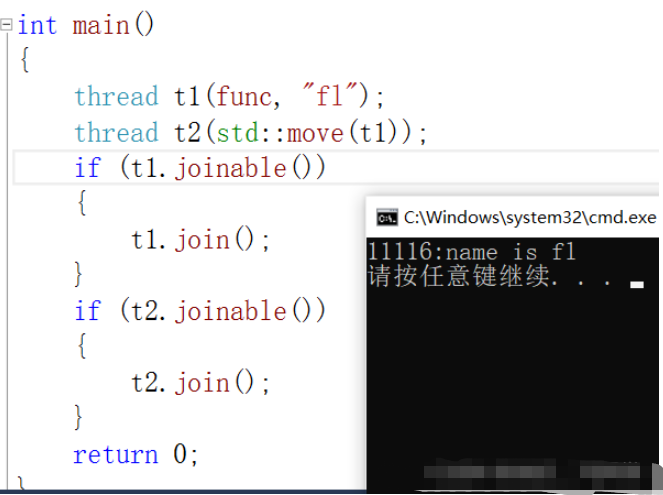
зәҝзЁӢ被移еҠЁд№ӢеҗҺпјҢзәҝзЁӢеҜ№иұЎt1е°ҶдёҚд»ЈиЎЁд»»дҪ•зәҝзЁӢдәҶпјҢеҸҜд»ҘйҖҡиҝҮи°ғиҜ•и§ӮеҜҹеҲ°

4гҖҒдә’ж–ҘйҮҸ
еҪ“еӨҡдёӘзәҝзЁӢеҗҢж—¶и®ҝй—®еҗҢдёҖдёӘе…ұдә«иө„жәҗж—¶пјҢеҰӮжһңдёҚеҠ д»ҘдҝқжҠӨжҲ–иҖ…дёҚеҒҡд»»дҪ•еҗҢжӯҘж“ҚдҪңпјҢеҸҜиғҪеҮәзҺ°ж•°жҚ®з«һдәүжҲ–дёҚдёҖиҮҙзҡ„зҠ¶жҖҒпјҢеҜјиҮҙзЁӢеәҸиҝҗиЎҢеҮәзҺ°й—®йўҳгҖӮ
дёәдәҶдҝқиҜҒжүҖжңүзҡ„зәҝзЁӢйғҪиғҪеӨҹжӯЈзЎ®ең°гҖҒеҸҜйў„жөӢең°гҖҒдёҚдә§з”ҹеҶІзӘҒең°и®ҝй—®е…ұдә«иө„жәҗпјҢC++11жҸҗдҫӣдәҶдә’ж–ҘйҮҸгҖӮ
дә’ж–ҘйҮҸжҳҜдёҖз§ҚеҗҢжӯҘеҺҹиҜӯпјҢжҳҜдёҖз§ҚзәҝзЁӢеҗҢжӯҘжүӢж®өпјҢз”ЁжқҘдҝқжҠӨеӨҡзәҝзЁӢеҗҢж—¶и®ҝй—®зҡ„е…ұдә«ж•°жҚ®гҖӮдә’ж–ҘйҮҸе°ұжҳҜжҲ‘们平常иҜҙзҡ„й”Ғ
C++11дёӯжҸҗдҫӣдәҶ4з§ҚиҜӯд№үзҡ„дә’ж–ҘйҮҸ
std::mutexпјҡзӢ¬еҚ зҡ„дә’ж–ҘйҮҸпјҢдёҚиғҪйҖ’еҪ’
std::timed_mutexпјҡеёҰи¶…ж—¶зҡ„зӢ¬еҚ дә’ж–ҘйҮҸпјҢдёҚиғҪйҖ’еҪ’дҪҝз”Ё
std::recursive_mutexпјҡйҖ’еҪ’дә’ж–ҘйҮҸпјҢдёҚиғҪеёҰи¶…ж—¶еҠҹиғҪ
std::recursive_timed_mutexпјҡеёҰи¶…ж—¶зҡ„йҖ’еҪ’дә’ж–ҘйҮҸ
4.1 зӢ¬еҚ зҡ„дә’ж–ҘйҮҸstd::mutex
иҝҷдәӣдә’ж–ҘйҮҸзҡ„жҺҘеҸЈеҹәжң¬зұ»дјјпјҢдёҖиҲ¬з”Ёжі•жҳҜйҖҡиҝҮlock()ж–№жі•жқҘйҳ»еЎһзәҝзЁӢпјҢзҹҘйҒ“иҺ·еҫ—дә’ж–ҘйҮҸзҡ„жүҖжңүжқғдёәжӯўгҖӮеңЁзәҝзЁӢиҺ·еҫ—дә’ж–ҘйҮҸ并е®ҢжҲҗд»»еҠЎд№ӢеҗҺпјҢе°ұеҝ…йЎ»дҪҝз”Ёunlock()жқҘи§ЈйҷӨеҜ№дә’ж–ҘйҮҸзҡ„еҚ з”ЁпјҢlock()е’Ңunlock()еҝ…йЎ»жҲҗеҜ№еҮәзҺ°гҖӮtry_lock()е°қиҜ•й”Ғе®ҡдә’ж–ҘйҮҸпјҢеҰӮжһңжҲҗеҠҹеҲҷиҝ”еӣһtrueпјҢеӨұиҙҘеҲҷиҝ”еӣһfalseпјҢе®ғжҳҜйқһйҳ»еЎһзҡ„гҖӮ
int num = 0;
std::mutex mtx;
void func()
{
for (int i = 0; i < 100; ++i)
{
mtx.lock();
num++;
mtx.unlock();
}
}
int main()
{
thread t1(func);
thread t2(func);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
cout << num << endl;
return 0;
}жү§иЎҢз»“жһңпјҡ
дҪҝз”Ёlock_guardеҸҜд»Ҙз®ҖеҢ–lock/unlockзҡ„еҶҷжі•пјҢеҗҢж—¶д№ҹжӣҙе®үе…ЁпјҢеӣ дёәlock_guardеңЁжһ„йҖ ж—¶дјҡиҮӘеҠЁй”Ғе®ҡдә’ж–ҘйҮҸпјҢиҖҢеңЁйҖҖеҮәдҪңз”ЁеҹҹеҗҺиҝӣиЎҢжһҗжһ„ж—¶иҮӘеҠЁи§Јй”ҒпјҢд»ҺиҖҢдҝқиҜҒдәҶдә’ж–ҘйҮҸзҡ„жӯЈзЎ®ж“ҚдҪңпјҢйҒҝе…Қеҝҳи®°unlockж“ҚдҪңпјҢеӣ жӯӨпјҢе°ҪйҮҸз”Ёlock_guardгҖӮlock_guardз”ЁеҲ°дәҶRALLжҠҖжңҜпјҢиҝҷз§ҚжҠҖжңҜеңЁзұ»зҡ„жһ„йҖ еҮҪж•°дёӯеҲҶй…Қиө„жәҗпјҢеңЁжһҗжһ„еҮҪж•°дёӯйҮҠж”ҫиө„жәҗпјҢдҝқиҜҒиө„жәҗеңЁеҮәдәҶдҪңз”Ёеҹҹд№ӢеҗҺе°ұйҮҠж”ҫгҖӮдёҠйқўзҡ„дҫӢеӯҗдҪҝз”Ёlock_guardеҗҺдјҡжӣҙз®Җд»ӢпјҢд»Јз ҒеҰӮдёӢпјҡ
void func()
{
for (int i = 0; i < 100; ++i)
{
lock_guard<mutex> lock(mtx);
num++;
}
}дёҖиҲ¬жқҘиҜҙпјҢеҪ“жҹҗдёӘзәҝзЁӢжү§иЎҢж“ҚдҪңе®ҢжҜ•еҗҺпјҢйҮҠж”ҫй”ҒпјҢ然еҗҺйңҖиҰҒзӯүеҫ…еҮ еҚҒжҜ«з§’пјҢи®©е…¶д»–зәҝзЁӢд№ҹеҺ»иҺ·еҸ–й”Ғиө„жәҗпјҢд№ҹеҺ»жү§иЎҢж“ҚдҪңгҖӮеҰӮжһңдёҚиҝӣиЎҢзӯүеҫ…зҡ„иҜқпјҢеҸҜиғҪеҪ“еүҚзәҝзЁӢйҮҠж”ҫй”ҒеҗҺпјҢеҸҲз«Ӣ马иҺ·еҸ–дәҶй”Ғиө„жәҗпјҢдјҡеҜјиҮҙе…¶д»–зәҝзЁӢеҮәзҺ°йҘҘйҘҝгҖӮ
4.2 йҖ’еҪ’зӢ¬еҚ дә’ж–ҘйҮҸrecursive_mutex
йҖ’еҪ’й”Ғе…Ғи®ёеҗҢдёҖзәҝзЁӢеӨҡж¬ЎиҺ·еҫ—иҜҘдә’ж–Ҙй”ҒпјҢеҸҜд»Ҙз”ЁжқҘи§ЈеҶіеҗҢдёҖзәҝзЁӢйңҖиҰҒеӨҡж¬ЎиҺ·еҸ–дә’ж–ҘйҮҸж—¶жӯ»й”Ғзҡ„й—®йўҳгҖӮеңЁд»ҘдёӢд»Јз ҒдёӯпјҢдёҖдёӘзәҝзЁӢеӨҡж¬ЎиҺ·еҸ–еҗҢдёҖдёӘдә’ж–ҘйҮҸж—¶дјҡеҸ‘з”ҹжӯ»й”Ғпјҡ
class Complex
{
public:
std::mutex mtx;
void SayHello()
{
lock_guard<mutex> lock(mtx);
cout << "Say Hello" << endl;
SayHi();
}
void SayHi()
{
lock_guard<mutex> lock(mtx);
cout << "say Hi" << endl;
}
};
int main()
{
Complex complex;
complex.SayHello();
return 0;
}жү§иЎҢз»“жһңпјҡ
иҝҷдёӘдҫӢеӯҗиҝҗиЎҢиө·жқҘе°ұеҸ‘з”ҹдәҶжӯ»й”ҒпјҢеӣ дёәеңЁи°ғз”ЁSayHelloж—¶иҺ·еҸ–дәҶдә’ж–ҘйҮҸпјҢд№ӢеҗҺеҶҚи°ғз”ЁSayHIеҸҲиҰҒиҺ·еҸ–зӣёеҗҢзҡ„дә’ж–ҘйҮҸпјҢдҪҶжҳҜиҝҷдёӘдә’ж–ҘйҮҸе·Із»Ҹиў«еҪ“еүҚзәҝзЁӢиҺ·еҸ– пјҢж— жі•йҮҠж”ҫпјҢиҝҷж—¶е°ұдјҡдә§з”ҹжӯ»й”ҒпјҢеҜјиҮҙзЁӢеәҸеҙ©жәғгҖӮ
иҰҒи§ЈеҶіиҝҷйҮҢзҡ„жӯ»й”Ғй—®йўҳпјҢжңҖз®ҖеҚ•зҡ„ж–№жі•е°ұжҳҜйҮҮз”ЁйҖ’еҪ’й”Ғпјҡstd::recursive_mutexпјҢе®ғе…Ғи®ёеҗҢдёҖдёӘзәҝзЁӢеӨҡж¬ЎиҺ·еҸ–дә’ж–ҘйҮҸ
class Complex
{
public:
std::recursive_mutex mtx;//еҗҢдёҖзәҝзЁӢеҸҜд»ҘеӨҡж¬ЎиҺ·еҸ–еҗҢдёҖдә’ж–ҘйҮҸпјҢдёҚдјҡеҸ‘з”ҹжӯ»й”Ғ
void SayHello()
{
lock_guard<recursive_mutex> lock(mtx);
cout << "Say Hello" << endl;
SayHi();
}
void SayHi()
{
lock_guard<recursive_mutex> lock(mtx);
cout << "say Hi" << endl;
}
};жү§иЎҢз»“жһңпјҡ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜе°ҪйҮҸдёҚиҰҒдҪҝз”ЁйҖ’еҪ’й”ҒжҜ”иҫғеҘҪпјҢдё»иҰҒеҺҹеӣ еҰӮдёӢпјҡ
1гҖҒйңҖиҰҒз”ЁеҲ°йҖ’еҪ’й”Ғе®ҡзҡ„еӨҡзәҝзЁӢдә’ж–ҘйҮҸеӨ„зҗҶеҫҖеҫҖжң¬иә«е°ұжҳҜеҸҜд»Ҙз®ҖеҢ–зҡ„пјҢе…Ғи®ёйҖ’еҪ’дә’ж–ҘйҮҸеҫҲе®№жҳ“ж”ҫзәөеӨҚжқӮйҖ»иҫ‘зҡ„дә§з”ҹпјҢиҖҢйқһеҜјиҮҙдёҖдәӣеӨҡзәҝзЁӢеҗҢжӯҘеј•иө·зҡ„жҷҰ涩问йўҳ
2гҖҒйҖ’еҪ’й”Ғзҡ„ж•ҲзҺҮжҜ”йқһйҖ’еҪ’й”Ғзҡ„ж•ҲзҺҮдҪҺ
3гҖҒйҖ’еҪ’й”ҒиҷҪ然е…Ғи®ёеҗҢдёҖдёӘзәҝзЁӢеӨҡж¬ЎиҺ·еҫ—еҗҢдёҖдёӘдә’ж–ҘйҮҸпјҢдҪҶеҸҜйҮҚеӨҚзҡ„жңҖеӨ§ж¬Ўж•°е№¶дёәе…·дҪ“иҜҙжҳҺпјҢдёҖж—Ұи¶…иҝҮдёҖе®ҡж¬Ўж•°пјҢеҶҚеҜ№lockиҝӣиЎҢи°ғз”Ёе°ұдјҡжҠӣеҮәstd::systemй”ҷиҜҜ
4.3 еёҰи¶…ж—¶зҡ„дә’ж–ҘйҮҸstd::timed_mutexе’Ңstd::recursive_timed_mutex
std::timed_mutexжҳҜи¶…ж—¶зҡ„зӢ¬еҚ й”ҒпјҢsrd::recursive_timed_mutexжҳҜи¶…ж—¶зҡ„йҖ’еҪ’й”ҒпјҢдё»иҰҒз”ЁеңЁиҺ·еҸ–й”Ғж—¶еўһеҠ и¶…ж—¶й”Ғзӯүеҫ…еҠҹиғҪпјҢеӣ дёәжңүж—¶дёҚзҹҘйҒ“иҺ·еҸ–й”ҒйңҖиҰҒеӨҡд№…пјҢдёәдәҶдёҚиҮідәҺдёҖзӣҙеңЁзӯүеҫ…иҺ·дә’ж–ҘйҮҸпјҢе°ұи®ҫзҪ®дёҖдёӘзӯүеҫ…и¶…ж—¶ж—¶й—ҙпјҢеңЁи¶…ж—¶ж—¶й—ҙеҗҺиҝҳеҸҜеҒҡе…¶д»–дәӢгҖӮ
std::timed_mutexжҜ”std::mutexеӨҡдәҶдёӨдёӘи¶…ж—¶иҺ·еҸ–й”Ғзҡ„жҺҘеҸЈпјҡtry_lock_forе’Ңtry_lock_untilпјҢиҝҷдёӨдёӘжҺҘеҸЈжҳҜз”ЁжқҘи®ҫзҪ®иҺ·еҸ–дә’ж–ҘйҮҸзҡ„и¶…ж—¶ж—¶й—ҙпјҢдҪҝз”Ёж—¶еҸҜд»Ҙз”ЁдёҖдёӘwhileеҫӘзҺҜеҺ»дёҚж–ӯең°иҺ·еҸ–дә’ж–ҘйҮҸгҖӮ
std::timed_mutex mtx;
void work()
{
chrono::milliseconds timeout(100);
while (true)
{
if (mtx.try_lock_for(timeout))
{
cout << this_thread::get_id() << ": do work with the mutex" << endl;
this_thread::sleep_for(chrono::milliseconds(250));
mtx.unlock();
}
else
{
cout << this_thread::get_id() << ": do work without the mutex" << endl;
this_thread::sleep_for(chrono::milliseconds(100));
}
}
}
int main()
{
thread t1(work);
thread t2(work);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ

еңЁдёҠйқўзҡ„дҫӢеӯҗдёӯпјҢйҖҡиҝҮдёҖдёӘwhileеҫӘзҺҜдёҚж–ӯең°еҺ»иҺ·еҸ–и¶…ж—¶й”ҒпјҢеҰӮжһңи¶…ж—¶иҝҳжІЎжңүиҺ·еҸ–еҲ°й”Ғж—¶е°ұдј‘зң 100жҜ«з§’пјҢеҶҚ继з»ӯиҺ·еҸ–й”ҒгҖӮ
зӣёжҜ”std::timed_mutexпјҢstd::recursive_timed_mutexеӨҡдәҶйҖ’еҪ’й”Ғзҡ„еҠҹиғҪпјҢе…Ғи®ёеҗҢдёҖдёӘзәҝзЁӢеӨҡж¬ЎиҺ·еҫ—дә’ж–ҘйҮҸгҖӮstd::recursive_timed_mutexе’Ңstd::recursive_mutexзҡ„з”Ёжі•зұ»дјјпјҢеҸҜд»ҘзңӢдҪңеңЁstd::recursive_mutexзҡ„еҹәзЎҖдёҠеўһеҠ дәҶи¶…ж—¶еҠҹиғҪ
4.4 std::lock_guardе’Ңstd::unique_lock
lock_guardе’Ңunique_lockзҡ„еҠҹиғҪе®Ңе…ЁзӣёеҗҢпјҢдё»иҰҒе·®еҲ«еңЁдәҺunique_lockжӣҙеҠ зҒөжҙ»пјҢеҸҜд»ҘиҮӘз”ұзҡ„йҮҠж”ҫmutexпјҢиҖҢlock_guardйңҖиҰҒзӯүеҲ°з”ҹе‘Ҫе‘Ёжңҹз»“жқҹеҗҺжүҚиғҪйҮҠж”ҫгҖӮ
е®ғ们зҡ„жһ„йҖ еҮҪж•°дёӯйғҪжңү第дәҢдёӘеҸӮж•°
unique_lockпјҡ

lock_guardпјҡ

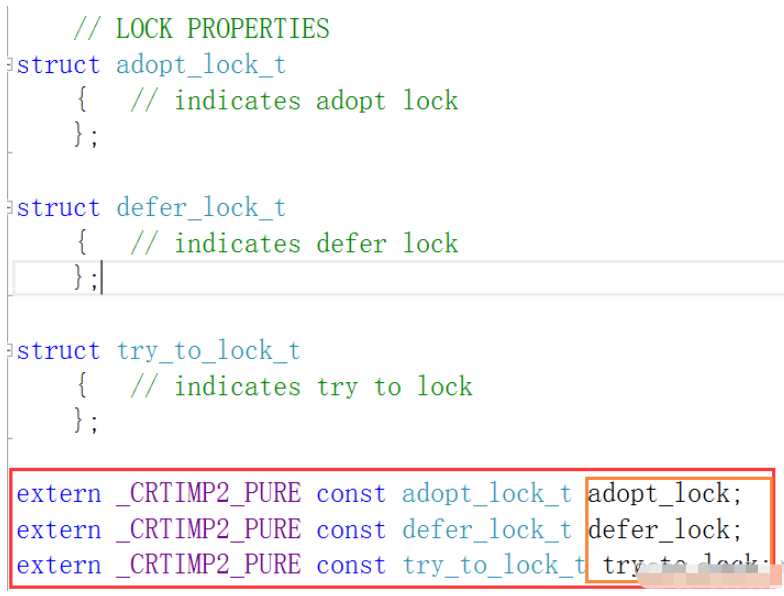
еҸҜд»Ҙд»Һжәҗз ҒдёӯзңӢеҲ°пјҢunique_lockзҡ„жһ„йҖ еҮҪж•°дёӯпјҢ第дәҢдёӘеҸӮж•°зҡ„з§Қзұ»жңүдёүз§ҚпјҢеҲҶеҲ«жҳҜadopt_lockпјҢdefer_lockе’Ңtry_to_lockгҖӮlock_guardзҡ„жһ„йҖ еҮҪж•°дёӯпјҢ第дәҢдёӘеҸӮж•°зҡ„з§Қзұ»еҸӘжңүдёҖз§ҚпјҢadopt_lock
иҝҷдәӣеҸӮж•°зҡ„еҗ«д№үеҲҶеҲ«жҳҜпјҡ
adopt_lockпјҡдә’ж–ҘйҮҸе·Із»Ҹиў«lockпјҢжһ„йҖ еҮҪж•°дёӯж— йңҖеҶҚlock(lock_ guardдёҺunique_lockйҖҡз”Ё)
defer_lockпјҡдә’ж–ҘйҮҸзЁҚеҗҺжҲ‘дјҡиҮӘиЎҢlockпјҢдёҚйңҖиҰҒеңЁжһ„йҖ еҮҪж•°дёӯlockпјҢеҸӘеҲқе§ӢеҢ–дёҖдёӘжІЎжңүеҠ й”Ғзҡ„mutex
try_to_lockпјҡдё»иҰҒдҪңз”ЁжҳҜеңЁдёҚйҳ»еЎһзәҝзЁӢзҡ„жғ…еҶөдёӢе°қиҜ•иҺ·еҸ–й”ҒпјҢеҰӮжһңдә’ж–ҘйҮҸеҪ“еүҚжңӘиў«й”Ғе®ҡпјҢеҲҷиҝ”еӣһstd::unique_lockеҜ№иұЎпјҢиҜҘеҜ№иұЎжӢҘжңүдә’ж–ҘйҮҸ并且已з»Ҹиў«й”Ғе®ҡгҖӮеҰӮжһңдә’ж–ҘйҮҸеҪ“еүҚе·Із»Ҹиў«еҸҰдёҖдёӘзәҝзЁӢй”Ғе®ҡпјҢеҲҷиҝ”еӣһдёҖдёӘз©әзҡ„std::unique_lockеҜ№иұЎ
mutex mtx;
void func()
{
//mtx.lock();//йңҖиҰҒеҠ й”ҒпјҢеҗҰеҲҷеңЁlockзҡ„з”ҹе‘Ҫе‘Ёжңҹз»“жқҹеҗҺпјҢдјҡиҮӘеҠЁи§Јй”ҒпјҢеҲҷдјҡеҜјиҮҙзЁӢеәҸеҙ©жәғ
unique_lock<mutex> lock(mtx, std::adopt_lock);
cout << this_thread::get_id() << " do work" << endl;
}
int main()
{
thread t(func);
if (t.joinable())
{
t.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ
adopt_lockе°ұиЎЁзӨәжһ„йҖ unique_lock<mutex>ж—¶пјҢи®Өдёәmutexе·Із»ҸеҠ иҝҮй”ҒдәҶпјҢе°ұдёҚдјҡеҶҚеҠ й”ҒдәҶпјҢе®ғе°ұжҠҠеҠ й”Ғзҡ„жқғйҷҗе’Ңж—¶жңәдәӨз»ҷдәҶжҲ‘们пјҢз”ұжҲ‘们иҮӘе·ұжҺ§еҲ¶
mutex mtx;
void func()
{
while (true)
{
unique_lock<mutex> lock(mtx, std::defer_lock);
cout << "func thread id is " << this_thread::get_id() << endl;
this_thread::sleep_for(chrono::milliseconds(500));
}
}
int main()
{
thread t1(func);
thread t2(func);
if (t1.joinable())
{
t1.join();
}
if (t2.joinable())
{
t2.join();
}
return 0;
}жү§иЎҢз»“жһңпјҡ

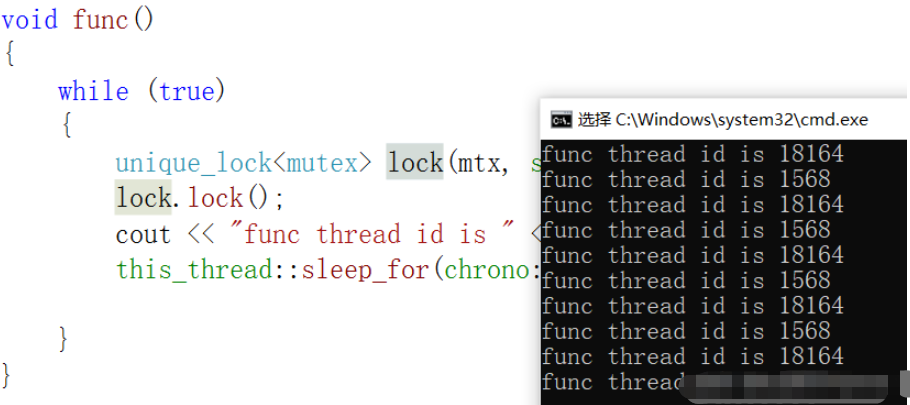
жң¬жқҘжҲ‘们зҡ„ж„Ҹж„ҝжҳҜt1е’Ңt2жҜҸдёӘж—¶еҲ»еҸӘиғҪжңүдёҖдёӘзәҝзЁӢжү“еҚ°"func thread id is…"пјҢдҪҶжҳҜе®һйҷ…дёҠеҚҙеҸ‘з”ҹдәҶз«һдәүзҡ„е…ізі»пјҢеҺҹеӣ е°ұеңЁдәҺdefer_lockеңЁжһ„йҖ unique_lock<mutex>ж—¶пјҢи®ӨдёәmutexеңЁеҗҺйқўдјҡеҠ й”ҒпјҢд№ҹе°ұжІЎжңүеҠ й”ҒпјҢжүҖд»Ҙжү“еҚ°з»“жһңжүҚеҸ‘з”ҹж··д№ұпјҢеӣ жӯӨйңҖиҰҒжҲ‘们жүӢеҠЁж”№иҝӣдёҖдёӢ
void func()
{
while (true)
{
unique_lock<mutex> lock(mtx, std::defer_lock);
lock.lock();
cout << "func thread id is " << this_thread::get_id() << endl;
this_thread::sleep_for(chrono::milliseconds(500));
//lock.unlock(); //еҸҜд»ҘеҠ пјҢд№ҹеҸҜд»ҘдёҚеҠ
//еӣ дёәеҶ…йғЁжңүдёҖдёӘж ҮеҮҶдёәпјҢеҰӮжһңжҲ‘们иҮӘе·ұжүӢеҠЁи§Јй”ҒдәҶпјҢз”ұдәҺж Үеҝ—дҪҚзҡ„ж”№еҸҳпјҢеңЁи°ғз”Ёlockзҡ„жһҗжһ„еҮҪж•°ж—¶пјҢе°ұдёҚдјҡиҝӣиЎҢи§Јй”Ғж“ҚдҪң
}
}жү§иЎҢз»“жһңпјҡ
5гҖҒcall_once/once_flagзҡ„дҪҝз”Ё
дёәдәҶдҝқиҜҒеңЁеӨҡзәҝзЁӢзҺҜеўғдёӯжҹҗдёӘеҮҪж•°д»…иў«и°ғз”ЁдёҖж¬ЎпјҢжҜ”еҰӮпјҢйңҖиҰҒеңЁеҲқе§ӢеҢ–жҹҗдёӘеҜ№иұЎпјҢиҖҢиҝҷдёӘеҜ№иұЎеҸӘиғҪеҲқе§ӢеҢ–дёҖж¬Ўж—¶пјҢе°ұеҸҜд»Ҙз”Ёstd::call_onceжқҘдҝқиҜҒеҮҪж•°еңЁеӨҡзәҝзЁӢзҺҜеўғдёӯеҸӘиғҪиў«и°ғз”ЁдёҖж¬ЎгҖӮдҪҝз”Ёstd::call_onceж—¶пјҢйңҖиҰҒдёҖдёӘonce_flagдҪңдёәcall_onceзҡ„е…ҘеҸӮпјҢз”Ёжі•жҜ”иҫғз®ҖеҚ•
call_onceеҮҪж•°жЁЎжқҝ

еңЁдҪҝз”Ёcall_onceж—¶пјҢ第дёҖдёӘеҸӮж•°жҳҜзұ»еһӢдёәonce_flagзҡ„ж Үеҝ—дҪҚпјҢ第дәҢдёӘеҸӮж•°жҳҜдёҖдёӘеҸҜи°ғз”ЁеҜ№иұЎпјҢ第дёүдёӘдёәеҸҜеҸҳеҸӮж•°пјҢиЎЁзӨәзҡ„еҸҜи°ғз”ЁеҜ№иұЎдёӯзҡ„еҸӮж•°
std::once_flag flag;
void do_once()
{
std::call_once(flag, [](){
cout << "call once" << endl;
});
}
int main()
{
const int ThreadSize = 5;
vector<thread> threads;
for (int i = 0; i < ThreadSize; ++i)
{
threads.emplace_back(do_once);
}
for (auto& t : threads)
{
if (t.joinable())
{
t.join();
}
}
return 0;
}жү§иЎҢз»“жһңпјҡ

6гҖҒжқЎд»¶еҸҳйҮҸ
жқЎд»¶еҸҳйҮҸжҳҜC++11жҸҗдҫӣзҡ„еҸҰеӨ–дёҖз§Қз”ЁдәҺзӯүеҫ…зҡ„еҗҢжӯҘжңәеҲ¶пјҢе®ғиғҪеӨҹйҳ»еЎһдёҖдёӘжҲ–иҖ…еӨҡдёӘиҙӨиҮЈпјҢзӣҙеҲ°ж”¶еҲ°еҸҰдёҖдёӘзәҝзЁӢеҸ‘еҮәзҡ„йҖҡзҹҘжҲ–иҖ…и¶…ж—¶пјҢжүҚдјҡе”ӨйҶ’еҪ“еүҚйҳ»еЎһзҡ„зәҝзЁӢгҖӮжқЎд»¶еҸҳйҮҸйңҖиҰҒе’Ңдә’ж–ҘйҮҸй…ҚеҗҲиө·жқҘдҪҝз”ЁгҖӮC++11жҸҗдҫӣдәҶдёӨз§ҚжқЎд»¶еҸҳйҮҸпјҡ
еҸҜд»ҘзңӢеҲ°condition_valuable_anyжҜ”condition_valuableжӣҙзҒөжҙ»пјҢеӣ дёәе®ғйҖҡз”ЁпјҢеҜ№жүҖжңүзҡ„й”ҒйғҪйҖӮз”ЁпјҢиҖҢcondition_valuableзҡ„жҖ§иғҪжӣҙеҘҪгҖӮжҲ‘们еә”иҜҘж №жҚ®е…·дҪ“зҡ„еә”з”ЁеңәжҷҜжқҘйҖүжӢ©еҗҲйҖӮзҡ„жқЎд»¶еҸҳйҮҸ
жқЎд»¶еҸҳйҮҸзҡ„дҪҝз”ЁжқЎд»¶еҰӮдёӢпјҡ
жӢҘжңүжқЎд»¶еҸҳйҮҸзҡ„зәҝзЁӢиҺ·еҸ–дә’ж–ҘйҮҸ
еҫӘзҺҜжЈҖжөӢжҹҗдёӘжқЎд»¶пјҢеҰӮжһңжқЎд»¶дёҚж»Ўи¶іпјҢеҲҷйҳ»еЎһзӣҙеҲ°жқЎд»¶ж»Ўи¶іпјӣеҰӮжһңжқЎд»¶ж»Ўи¶іпјҢеҲҷеҗ‘дёӢжү§иЎҢ
жҹҗдёӘзәҝзЁӢж»Ўи¶іжқЎд»¶жү§иЎҢе®ҢжҜ•д№ӢеҗҺи°ғз”Ёnotify_oncжҲ–иҖ…notify_allе”ӨйҶ’дёҖдёӘжҲ–иҖ…жүҖжңүзӯүеҫ…зҡ„зәҝзЁӢ
дёҖдёӘз®ҖеҚ•зҡ„з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎеһӢ
mutex mtx;
condition_variable_any notEmpty;//жІЎж»Ўзҡ„жқЎд»¶еҸҳйҮҸ
condition_variable_any notFull;//дёҚдёәз©әзҡ„жқЎд»¶еҸҳйҮҸ
list<string> list_; //зј“еҶІеҢә
const int custom_threads_size = 3;//ж¶Ҳиҙ№иҖ…зҡ„ж•°йҮҸ
const int produce_threads_size = 4;//з”ҹдә§иҖ…зҡ„ж•°йҮҸ
const int max_size = 10;
void produce(int i)
{
while (true)
{
lock_guard<mutex> lock(mtx);
notEmpty.wait(mtx, []{
return list_.size() != max_size;
});
stringstream ss;
ss << "з”ҹдә§иҖ…" << i << "з”ҹдә§зҡ„дёңиҘҝ";
list_.push_back(ss.str());
notFull.notify_one();
}
}
void custome(int i)
{
while (true)
{
lock_guard<mutex> lock(mtx);
notFull.wait(mtx, []{
return !list_.empty();
});
cout << "ж¶Ҳиҙ№иҖ…" << i << "ж¶Ҳиҙ№дәҶ " << list_.front() << endl;
list_.pop_front();
notEmpty.notify_one();
}
}
int main()
{
vector<std::thread> producer;
vector<std::thread> customer;
for (int i = 0; i < produce_threads_size; ++i)
{
producer.emplace_back(produce, i);
}
for (int i = 0; i < custom_threads_size; ++i)
{
customer.emplace_back(custome, i);
}
for (int i = 0; i < produce_threads_size; ++i)
{
producer[i].join();
}
for (int i = 0; i < custom_threads_size; ++i)
{
customer[i].join();
}
return 0;
}еңЁдёҠиҝ°жЎҲдҫӢдёӯпјҢlist<string> list_жҳҜдёҖдёӘдёҙз•Ңиө„жәҗпјҢж— и®әжҳҜз”ҹдә§иҖ…з”ҹдә§ж•°жҚ®пјҢиҝҳжҳҜж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№ж•°жҚ®пјҢйғҪиҰҒеҫҖlist_дёӯжҸ’е…Ҙж•°жҚ®жҲ–иҖ…еҲ йҷӨж•°жҚ®пјҢдёәдәҶйҳІжӯўеҮәзҺ°ж•°жҚ®з«һдәүжҲ–дёҚдёҖиҮҙзҡ„зҠ¶жҖҒпјҢеҜјиҮҙзЁӢеәҸиҝҗиЎҢеҮәзҺ°й—®йўҳпјҢеӣ дёәжҜҸж¬Ўж“ҚдҪңlist_ж—¶йғҪйңҖиҰҒиҝӣиЎҢеҠ й”Ғж“ҚдҪңгҖӮ
еҪ“list_жІЎжңүж»Ўзҡ„жғ…еҶөдёӢпјҢз”ҹдә§иҖ…еҸҜд»Ҙз”ҹдә§ж•°жҚ®пјҢеҰӮжһңж»ЎдәҶпјҢеҲҷдјҡйҳ»еЎһеңЁжқЎд»¶еҸҳйҮҸnotFullдёӢпјҢйңҖиҰҒж¶Ҳиҙ№иҖ…йҖҡиҝҮnotify_one()йҡҸжңәе”ӨйҶ’дёҖдёӘз”ҹдә§иҖ…гҖӮ
еҪ“list_дёҚдёәз©әзҡ„жғ…еҶөдёӢгҖӮж¶Ҳиҙ№иҖ…еҸҜд»Ҙж¶Ҳиҙ№ж•°жҚ®пјҢеҰӮжһңз©әдәҶпјҢеҲҷдјҡйҳ»еЎһеңЁжқЎд»¶еҸҳйҮҸnotEmptyдёӢпјҢйңҖиҰҒз”ҹдә§иҖ…йҖҡиҝҮnotify_one()йҡҸжңәе”ӨйҶ’дёҖдёӘж¶Ҳиҙ№иҖ…гҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңC++11зәҝзЁӢгҖҒдә’ж–ҘйҮҸеҸҠжқЎд»¶еҸҳйҮҸжҖҺд№ҲеҲӣе»әвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





