这篇文章给大家介绍用于点云分析的自组织网络SO-Net是怎样的,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
下面提出SO-Net,一种用于无序点云深度学习的置换不变网络结构。 SO-Net通过构建自组织映射(SOM)来模拟点云的空间分布。基于SOM,SO-Net对单个点和SOM节点进行分层特征提取,最终用单个特征向量来表示输入点云。网络的感受野可以通过进行点对节点的KNN(k近邻搜索)系统地调整。在识别点云重建,分类,对象部分分割和形状检索等任务中,我们提出的网络表现出的性能与最先进的方法相似或更好。另外,由于所提出的架构的并行性和简单性,所以训练速度比现有的点云识别网络快得多。
经过多年的深入研究,卷积神经网络(ConvNets)现在成为许多最先进的计算机视觉算法的基础,例如,图像识别,对象分类和语义分割等。尽管ConvNets在二维图像方面取得了巨大成功,但在3D数据上使用深度学习仍然是一个具有挑战性的问题。虽然3D卷积网络(3D ConvNets)可以应用于光栅化为体素表示的3D数据,但由于大多数3D数据的稀疏性,大多数计算都是冗余的。此外,不成熟的3D ConvNets的性能很大程度上受到分辨率的损失和呈指数级增长的计算成本限制。同时,深度传感器的加速发展以及自动驾驶汽车等应用的巨大需求使得高效处理3D数据成为当务之急。包括ModelNet [37],ShapeNet [8],2D-3D-S [2]在内的3D数据集的最新可用性增加了3D数据研究的普及。
为了避免简单体素化的缺点,一种选择是明确利用体素网格的稀疏性[35,21,11]。虽然稀疏设计允许更高的网格分辨率,但其诱导的复杂性和局限性使其难以实现大规模或灵活的深度网络[30]。另一种选择是利用可伸缩索引结构,包括kd-tree [4],八叉树[25]。基于这些结构的深度网络显示出令人鼓舞的结果。与基于树的结构相比,点云表示在数学上更简洁和直接,因为每个点仅由3维向量表示。此外,借助运动结构(SfM)算法,可以使用流行的传感器(如RGB-D相机,LiDAR或常规相机)轻松获取点云。尽管点云被广泛使用,也能够轻松获取,但点云识别任务仍然具有挑战性。传统的深度学习方法如ConvNets不适用,因为点云在空间上是不规则的,并且可以任意排列。由于这些困难,很少有人尝试将深度学习技术直接应用到点云,直到最近的PointNet [26]。
尽管作为将深度学习应用于点云的先驱,PointNet仍无法充分处理局部特征提取。后来PointNet++[28]被提出来通过构建一个类似金字塔的特征聚合方案来解决这个问题,但[28]中的点采样和分组策略并没有揭示输入点云的空间分布。Kd-Net [18]从输入点云构建kd树,然后进行从树叶到根节点的分层特征提取。Kd-Net明确地利用点云的空间分布,但是仍然存在诸如感受野不重叠等限制。
在本文中,我们提出SO-Net来解决现有基于点云的网络中的问题。具体而言,建立SOM [19]来模拟输入点云的空间分布,这使得在单独的点和SOM节点上进行分层特征提取成为可能。最终,输入点云可以被压缩成单个特征向量。在特征聚合过程中,通过在SOM上执行点到节点的k-近邻(KNN)搜索来控制感受野重叠。理论上,SO-Net通过特殊的网络设计以及我们的置换不变SOM训练来保证对输入点的顺序保持不变。我们的SO-Net的应用包括基于点云的分类,自动编码器重建,零件分割和形状检索,如图1所示。
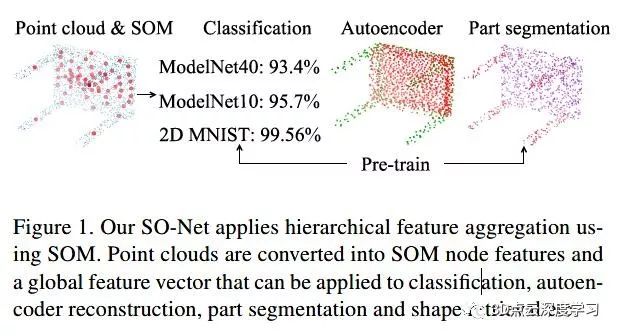
主要贡献如下:
我们设计了置换不变网络 - 显式利用点云空间分布的SO-Net。
通过在SOM上进行点到节点的KNN搜索,可以系统地调整感受野重叠来执行分层特征提取。
我们提出一种点云自动编码器作为预训练,以改善各种任务中的网络性能。
与最先进的方法相比,在各种应用中获得相似或更好的性能,并且训练速度显著加快。
关于用于点云分析的自组织网络SO-Net是怎样的就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579675/blog/4353105



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



