这篇文章主要介绍SQL优化之如何使用索引,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
下面 sql 30秒执行出结果,查看 sql 谓词中有 like ,我们知道谓词中有这样的语句是不走索引的(为了保护客户的隐私,表名和部分列已经重命名)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
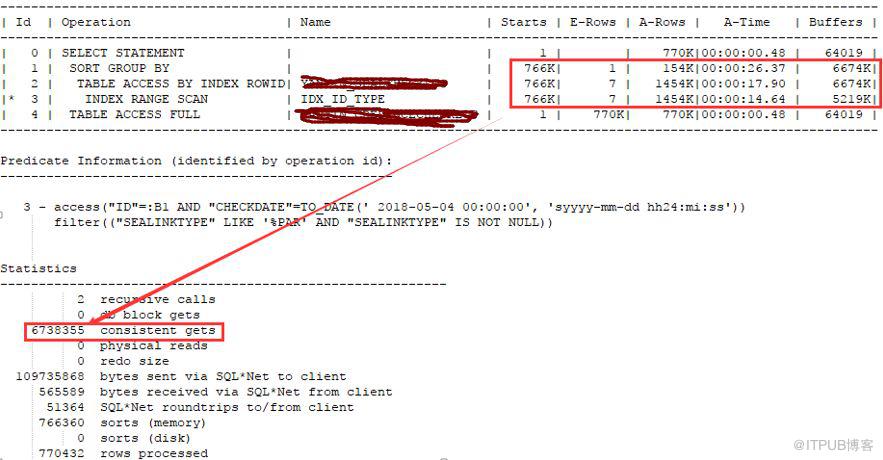
逻辑读600多万。查看索引情况如下

表过滤返回数据量如下:
1 2 3 4 5 6 |
|
通过查询上面返回数据可知,因为xxxtype不走索引,所以通过索引要回表197984次,如果走了索引只回表12856次。
下面我们建立REVERSE索引IDX_ID_TYPE_RE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
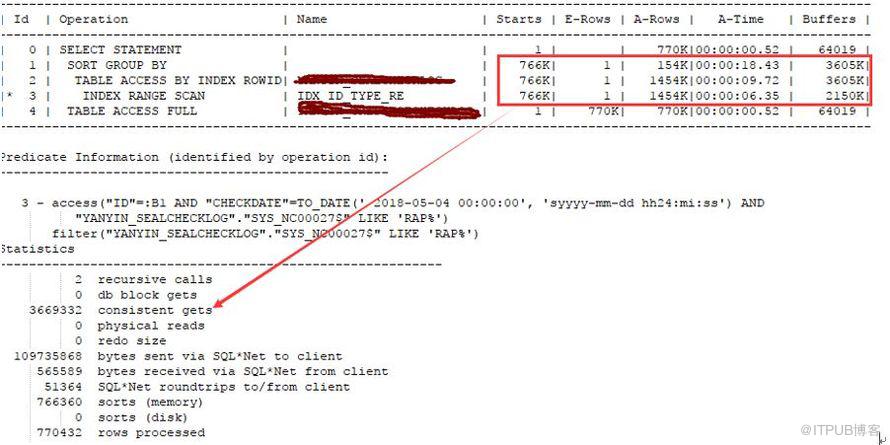
查看执行计划如下,逻辑读将为300万,但是时间还是维持在 18 秒,根本原因在于这个索引因为标量子查询的问题被访问700 万次导致。
下面我们改写sql如下
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
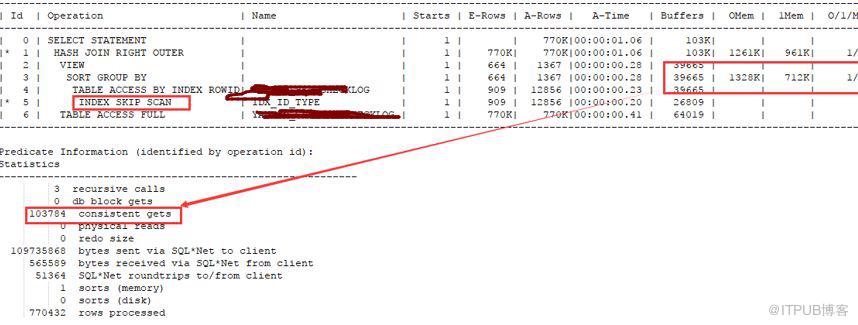
执行计划中出现index_skip_scan。
下面我们创建如下索引:
1 |
|
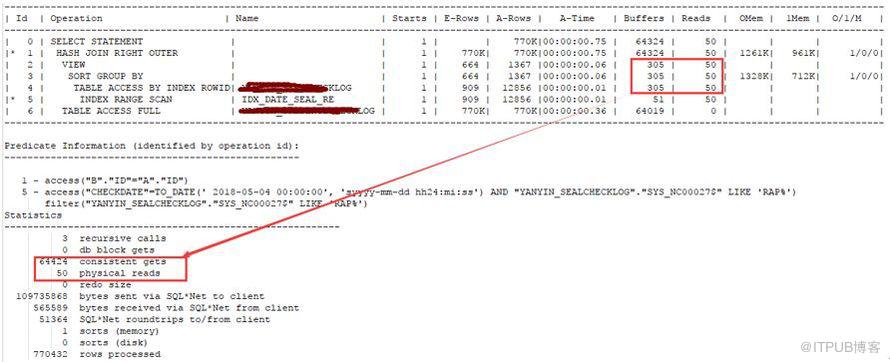
可以看到,逻辑读降到64424, 50 个物理读是因为刚刚创建索引的原因, sql 也秒出。
以上是“SQL优化之如何使用索引”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:http://blog.itpub.net/28218939/viewspace-2155102/



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



