这篇文章主要介绍了Hadoop中HDFS文件读写流程是怎么样的,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
一、文件读流程说明
读取操作是对于Cient端是透明操作,感觉是连续的数据流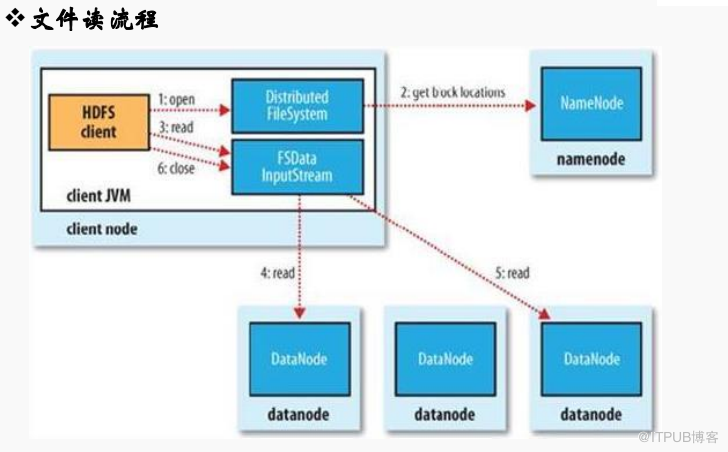
1、Client 通过FileSystem.open(filePath)方法,去与NameNode进行RPC通信,返回该文件的部分
或全部block列表,也就是返回FSDatainputstream对象;
2、Client调用FSDatainputStream对象的read()方法;
a. 去与第一个最近的DN进行read,读取完后会check;如果ok会关闭与当前的DN通信;check fail
会记录失败的block+DN信息下次不会读,然后去读取第二个DN地址
b. 第二个块最近的DN上进行读取,check后关闭与DN通信
c. block列表读取完了,文件还没有结束,FileSystem会从NameNode获取下一批的block列表;
3、Client条用FSDatainput对象的close方法,关闭输入流;
总结
client > filesystem.open()与NameNode进行RPC通信返回get block list
client > 调用inputstream对象read()方法
if ok > 关闭DN通信调用inputstream.close()方法关闭输入流
if fail > 记录DN和block信息,向第二个DN去读取最后close();
block列表read out , file over year > filesystem获取下一批block列表
二、文件写流程说明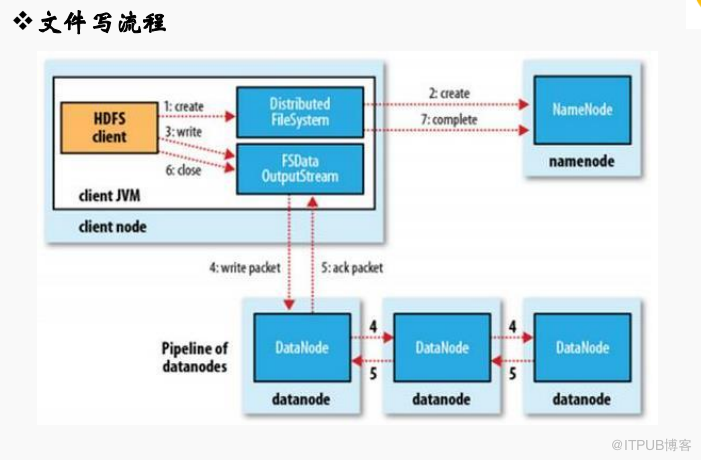
1、Client调用FileSystem.create(filepath)方法,与NameNode进行RPC通信,check该路径的文件是否存在和是否有创建该文件权限,假如ok就创建一个新文件,但并不关联任何的block,返回一个FSDataOutputStream对象;
2、Client调用FSDataOutputStream对象的write()方法,将第一个块写入第一个DataName,依次传给第二个节点,第三个节点,第三个节点写完返回一个ack packet给第二个节点,第二个节点返回第一个节点,第一个节点返回给ack packet给FSDataOutputstream对象,意味着第一个块写完,副本数为3;后面剩余块依次这样写;
3、文件写入数据完成后,Client调用FSDataOutputStream.close()方法,关闭输出流,刷新缓存区的数据包;
4、最后调用FileSystem.complate()方法,告诉NameNode节点写入成功;
总结:File.System.create()方法 > NameNode check(qx and exists )
if ok > 返回 FSDataOutStream对象 | if fail > return error
client 调用FSDataOutstream.write()方法 > 写入DN,teturn ack packet > FSDataOutStream对象
client 调用FSDataOutstream.close()方法关闭输出流 >flush缓存
最后FileSystem.complate() 方法 > NameNode write ok
感谢你能够认真阅读完这篇文章,希望小编分享的“Hadoop中HDFS文件读写流程是怎么样的”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





