小编今天带大家了解数据仓库中的OLTP与OLAP查询是怎样的,文中知识点介绍的非常详细。觉得有帮助的朋友可以跟着小编一起浏览文章的内容,希望能够帮助更多想解决这个问题的朋友找到问题的答案,下面跟着小编一起深入学习“数据仓库中的OLTP与OLAP查询是怎样的”的知识吧。
在业务数据处理的早期,对数据库的写操作通常对应于正在发生的商业交易-进行销售,与供应商下订单,支付员工的工资等。随着数据库扩展到不涉及的领域 涉及货币易手,但是交易一词仍然存在,是指构成逻辑单元的一组读写操作。 这些类型的查询称为事务处理系统查询(OLTP)。 为这些查询设计的系统通常是面向用户的,这意味着它们可能会看到大量的请求。 为了处理负载,应用程序通常仅在每个查询中触摸少量记录。 该应用程序使用某种密钥来请求记录,而存储引擎使用索引来查找所请求密钥的数据。 磁盘查找时间通常是这里的瓶颈。
但是,数据库也开始越来越多地用于数据分析,而这种数据分析具有非常不同的访问模式。 通常,分析查询需要扫描大量记录,仅读取每条记录的几列,并计算汇总统计信息(例如计数,总和或平均值),而不是将原始数据返回给用户。 例如,如果您的数据是销售交易表,则分析查询可能是:
一月份,我们每家商店的总收入是多少?
在最近的促销活动中,我们售出的iPhone比平时多了多少?
哪个品牌的牛奶最常与家乐氏的玉米片一起购买?
这些查询通常由业务分析人员编写,并馈入有助于公司管理层做出更好决策(业务智能)的报告。 为了将这种使用数据库的模式与事务处理区分开来,它被称为在线分析处理(OLAP)。 它们之所以鲜为人知,是因为它们是由业务分析师而不是最终用户处理的。 与OLTP系统相比,它们处理的查询量要少得多,但每个查询的要求通常很高,需要在短时间内扫描数百万条记录。 磁盘带宽(不是寻道时间)通常是这里的瓶颈,而面向列的存储是此类工作负载越来越流行的解决方案。
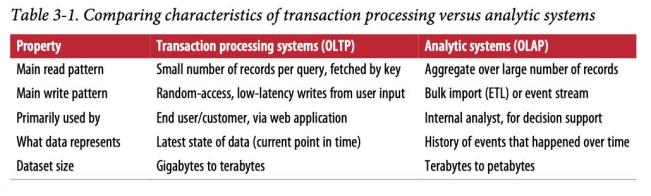
OLTP和OLAP之间的区别并不总是很明确,但是下面列出了一些典型特征。
首先,将相同的数据库用于事务处理和分析查询。事实证明,SQL在这方面非常灵活:它对于OLTP类型查询和OLAP类型查询都适用。尽管如此,在1980年代末和1990年代初,公司有一种趋势是停止使用OLTP系统进行分析,而改为在单独的数据库上运行分析。这个独立的数据库称为数据仓库。
企业可能具有数十种不同的交易处理系统:为面向客户的网站提供动力的系统,实体商店中的销售点(结帐)系统,仓库中的库存跟踪,车辆路线规划,供应商管理,员工管理等。这些系统中的一个很复杂,需要一个团队来维护它,因此这些系统最终只能彼此独立地运行。通常期望这些OLTP系统具有高可用性,并以低延迟处理事务,因为它们通常对业务运营至关重要。因此,数据库管理员密切保护其OLTP数据库。他们通常不愿让业务分析人员在OLTP数据库上运行临时分析查询,因为这些查询通常很昂贵,会扫描数据集的大部分,这可能会损害并发执行事务的性能。
数据仓库
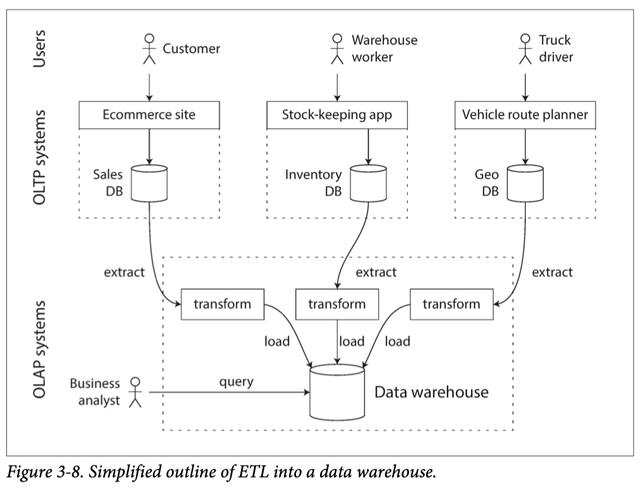
相比之下,数据仓库是一个独立的数据库,分析人员可以查询其内心的内容,而不会影响OLTP操作。数据仓库包含公司所有各种OLTP系统中数据的只读副本。从OLTP数据库中提取数据(使用定期数据转储或连续的更新流),将其转换为易于分析的模式,进行清理,然后将其加载到数据仓库中。将数据放入仓库的过程称为"提取-转换-加载(ETL)"。现在,几乎所有大型企业都存在数据仓库,但在小型企业中几乎闻所未闻。这可能是因为大多数小型公司没有太多不同的OLTP系统;而且大多数小型公司的数据量都很小-足够小,可以在常规SQL数据库中查询,甚至可以在电子表格中进行分析。在大型公司中,要做一些在小型公司中简单的事情需要很多繁重的工作。
使用单独的数据仓库而不是直接查询OLTP系统进行分析的一大优势是,可以针对分析访问模式对数据仓库进行优化。 某些数据库(例如Microsoft SQL Server和SAP HANA)在同一产品中支持事务处理和数据仓库。 但是,它们越来越成为两个独立的存储和查询引擎,它们恰巧可以通过公共SQL接口进行访问。 数据仓库供应商(例如Teradata,Vertica,SAP HANA和ParAccel)通常在昂贵的商业许可下销售其系统。 Amazon RedShift是ParAccel的托管版本。 最近,出现了许多开源的SQL-onHadoop项目。 他们很年轻,但旨在与商业数据仓库系统竞争。 这些包括Apache hive,Spark SQL,Cloudera Impala,Facebook Presto,Apache Tajo和Apache Drill。 其中一些是基于Google Dremel的想法。
Analytics的存储架构
根据应用程序的需求,在事务处理领域中会使用各种不同的数据模型。 另一方面,在分析中,数据模型的多样性要少得多。 许多数据仓库都以相当公式化的方式使用,称为星型模式(也称为维建模)。 通常,将事实捕获为单个事件,因为这样可以在以后最大程度地进行分析。 但是,这意味着事实表可能会变得非常大。
星星和雪花:
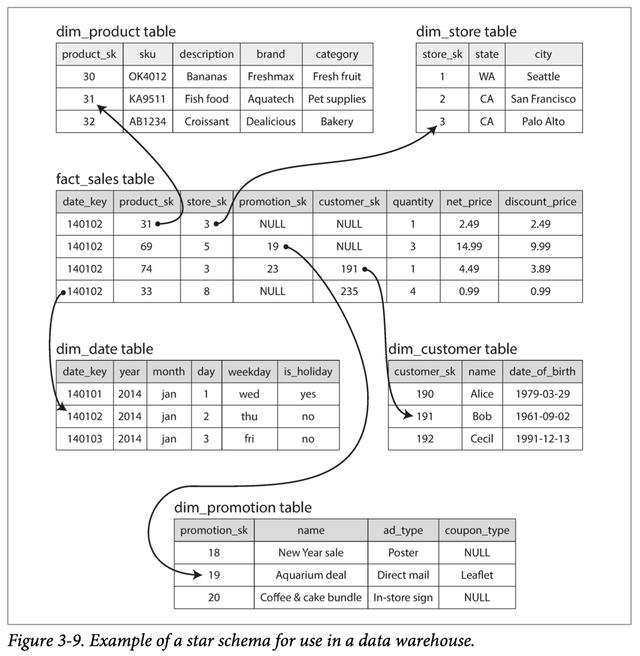
"星型模式"的名称来自以下事实:当可视化表关系时,事实表位于中间,并被其维度表包围; 这些桌子的连接就像星星的光芒。 此模板的一种变体称为雪花模式,其中尺寸进一步细分为多个子维度。 像Apple,Walmart或eBay这样的大企业,其数据仓库中可能有数十PB的事务历史记录,其中大多数实际上是表。
列式存储:
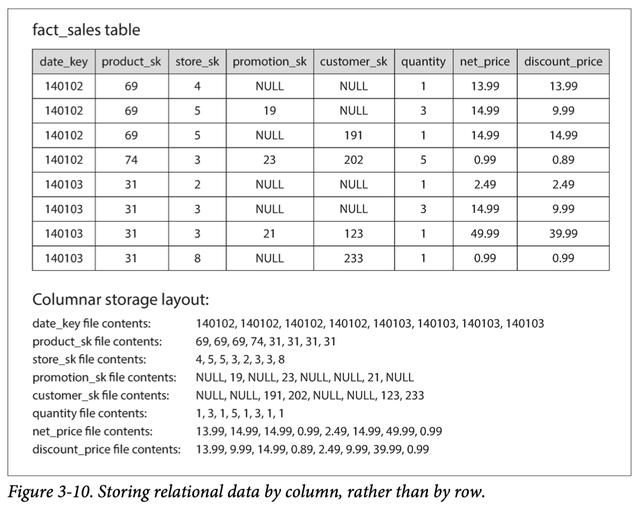
尽管事实表通常超过100列,但是典型的数据仓库查询一次只能访问其中的4或5。 在大多数OLTP数据库中,存储以面向行的方式进行布局:表的一行中的所有值都彼此相邻存储。 为了处理诸如"查找某项X在12月的平均销售额"之类的分析查询,面向行的存储引擎仍然需要将所有这些行(每个行包含100多个属性)从磁盘加载到内存中 ,解析它们并过滤掉不符合要求的条件,这可能会花费很长时间。 面向列的存储背后的想法很简单:不要将一行中的所有值都存储在一起,而是将每一列中的所有值存储在一起。 如果每列存储在单独的文件中,则查询仅需要读取和解析该查询中使用的那些列,这可以节省大量工作。
列压缩:

通常,一列中不同值的数量与行数相比很小(例如,零售商可能进行数十亿次销售交易,但只有100,000种不同产品)。 根据列中的数据,可以使用不同的压缩技术-在数据仓库中特别有效的一种技术是位图编码。
现在,我们可以将一列包含n个不同的值,并将其转换为n个单独的位图-每个不同的值一个位图,每行一个位。 如果行具有该值,则该位为1,否则为0。 如果n很小(例如,一个国家/地区列可能具有大约200个不同的值),则这些位图可以每行一位存储。
感谢大家的阅读,以上就是“数据仓库中的OLTP与OLAP查询是怎样的”的全部内容了,学会的朋友赶紧操作起来吧。相信亿速云小编一定会给大家带来更优质的文章。谢谢大家对亿速云网站的支持!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





