1. 概述
大数据tensorflowonspark 进行安装和测试。
2 .环境
所选操作系统 | 地址和软件版本 | 节点类型 |
Centos7.3 64位 | 192.168.2.31(master) Java:jdk 1.8 Scala:2.10.4 Hadoop:2.7.3 Spark:2.12.3 TensorFlowOnSpark:0.8.0 Python2.7 | Master |
Centos7.3 64位 | 192.168.2.32(spark worker) Java:jdk 1.8 Hadoop:2.7.3 Spark:2.12.3 | slave001 |
Centos7.3 64位 | 192.168.2.33(spark worker) Java:jdk 1.8 Hadoop:2.7.3 Spark:2.12.3 | slave002 |
3 .安装
1.1 删除系统自带jdk:
# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
rpm -e --nodeps tzdata-java-2016c-1.el6.noarch1.2 安装jdk
rpm -ivh jdk-8u144-linux-x64.rpm
1.3添加java路径
export JAVA_HOME=/usr/java/jdk1.8.0_1441.4 验证java
[root@master opt]# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)1.5 Ssh免登陆设置
cd /root/.ssh/
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
scp id_rsa.pub authorized_keys root@192.168.2.32:/root/.ssh/
scp id_rsa.pub authorized_keys root@192.168.2.31:/root/.ssh/1.6安装python2.7和pip
yum install -y gcc
wget https://www.python.org/ftp/python/2.7.13/Python-2.7.13.tgz
tar vxf Python-2.7.13.tgz
cd Python-2.7.13.tgz
./configure --prefix=/usr/local
make && make install
[root@master opt]# python
Python 2.7.13 (default, Aug 24 2017, 16:10:35)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-18)] on linux2
Type "help", "copyright", "credits" or "license" for more information.1.7 安装pip和setuptools
tar zxvf pip-1.5.4.tar.gz
tar zxvf setuptools-2.0.tar.gz
cd setuptools-2.0
python setup.py install
cd pip-1.5.4
python setup.py install1.8 Hadoop安装和配置
1.8.1 三台机器都要安装Hadoop
tar zxvf hadoop-2.7.3.tar.gz -C /usr/local/
cd /usr/local/hadoop-2.7.3/bin
[root@master bin]# ./hadoop version
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /usr/local/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar1.8.2 配置hadoop
配置master
vi /usr/local/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9001</value>
</property>
</configuration>配置slave
[root@slave001 hadoop-2.7.3]# vi ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave001:9001</value>
</property>
</configuration>[root@slave002 hadoop-2.7.3]# vi ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave002:9001</value>
</property>
</configuration>1.8.3 配置hdfs
vi /usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>master:9001</value>
</property>
</configuration>1.9 安装scala
tar -zxvf scala-2.12.3.tgz -C /usr/local/
#修改变量添加scala
vi /etc/profile
export SCALA_HOME=/usr/local/scala-2.12.3/
export PATH=$PATH:/usr/local/scala-2.12.3/bin
source /etc/profile2.0三台机器都要安装spark
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_144/
export SCALA_HOME=/usr/local/scala-2.12.3/
export PATH=$PATH:/usr/local/scala-2.12.3/bin
export SPARK_HOME=/usr/local/spark-2.1.1-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile修改spark配置
cd /usr/local/spark-2.1.1-bin-hadoop2.7/
vi ./conf/spark-env.sh.template
export JAVA_HOME=/usr/java/jdk1.8.0_144/
export SCALA_HOME=/usr/local/scala-2.12.3/
#export SPARK_HOME=/usr/local/spark-2.1.1-bin-hadoop2.7/
export SPARK_MASTER_IP=192.168.2.31
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.3/etc/hadoop
export HADOOP_HDFS_HOME=/usr/local/hadoop-2.7.3/
export SPARK_DRIVER_MEMORY=1g
保存退出
mv spark-env.sh.template spark-env.sh
#修改slaves
[root@master conf]# vi slaves.template
192.168.2.32
192.168.2.33
[root@master conf]# mv slaves.template slaves
2.1 三台主机上修改hosts
vi /etc/hosts
192.168.2.31 master
192.168.2.32 slave001
192.168.2.33 slave002
4. 启动服务
[root@master local]# cd hadoop-2.7.3/sbin/
修改配置文件vi /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_144/
./start-all.sh
localhost: Warning: Permanently added 'localhost' (RSA) to the list of known hosts.
localhost: Error: JAVA_HOME is not set and could not be found.
修改配置文件
vi /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_144/
重新启动服务
sbin/start-all.sh
#启动spark
cd /usr/local/spark-2.1.1-bin-hadoop2.7/sbin/
./start-all.sh
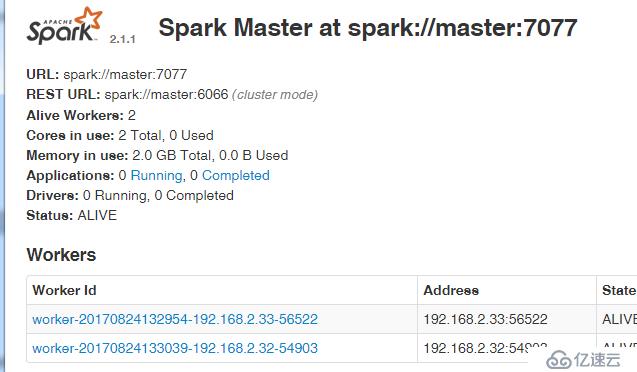
4. 安装tensorflow
前提下先安装cuda
vim /etc/yum.repos.d/linuxtech.testing.repo
添加内容:
[cpp] view plain copy
[linuxtech-testing]
name=LinuxTECH Testing
baseurl=http://pkgrepo.linuxtech.net/el6/testing/
enabled=0
gpgcheck=1
gpgkey=http://pkgrepo.linuxtech.net/el6/release/RPM-GPG-KEY-LinuxTECH.NET
sudo rpm -i cuda-repo-rhel6-8.0.61-1.x86_64.rpm
sudo yum clean all
sudo yum install cuda
rpm -ivh --nodeps dkms-2.1.1.2-1.el6.rf.noarch.rpm
yum install cuda
yum install epel-release
yum install -y zlib*
#软连接cuda
ln -s /usr/local/cuda-8.0 /usr/local/cudaldconfig /usr/local/cuda/lib64
Vi /etc/profile
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda更新pip
pip install --upgrade pip
下载tensorflow
pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.8.0-cp27-none-linux_x86_64.whl
安装好后
#python
>>> import tensorflow
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/site-packages/tensorflow/__init__.py", line 23, in <module>
from tensorflow.python import *
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/__init__.py", line 45, in <module>
from tensorflow.python import pywrap_tensorflow
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 28, in <module>
_pywrap_tensorflow = swig_import_helper()
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow', fp, pathname, description)
ImportError: libcudart.so.7.5: cannot open shared object file: No such file or directory#这是因为lib库不完整
yum install openssl -y
yum install openssl-devel -y
yum install gcc gcc-c++ gcc*
#更新pip install --upgrade pip
pip install --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.8.0-cp27-none-linux_x86_64.whl>>> import tensorflow
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/site-packages/tensorflow/__init__.py", line 23, in <module>
from tensorflow.python import *
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/__init__.py", line 45, in <module>
from tensorflow.python import pywrap_tensorflow
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 28, in <module>
_pywrap_tensorflow = swig_import_helper()
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/pywrap_tensorflow.py", line 24, in swig_import_helper
_mod = imp.load_module('_pywrap_tensorflow', fp, pathname, description)
ImportError: /lib64/libc.so.6: version `GLIBC_2.15' not found (required by /usr/local/lib/python2.7/site-packages/tensorflow/python/_pywrap_tensorflow.so)
#这是因为tensorflow 使用的glibc版本库太高,系统自带太低了。
可以使用。# strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_3.4.9
GLIBCXX_3.4.10
GLIBCXX_3.4.11
GLIBCXX_3.4.12
GLIBCXX_3.4.13
GLIBCXX_FORCE_NEW
GLIBCXX_DEBUG_MESSAGE_LENGTH
放入最新的glibc库,解压出6.0.20
libstdc++.so.6.0.20 覆盖原来的libstdc++.so.6
[root@master 4.4.7]# ln -s /opt/libstdc++.so.6/libstdc++.so.6.0.20 /usr/lib64/libstdc++.so.6
ln: creating symbolic link `/usr/lib64/libstdc++.so.6': File exists
[root@master 4.4.7]# mv /usr/lib64/libstdc++.so.6 /root/
[root@master 4.4.7]# ln -s /opt/libstdc++.so.6/libstdc++.so.6.0.20 /usr/lib64/libstdc++.so.6
[root@master 4.4.7]# strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
[root@master ~]# strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
GLIBCXX_3.4
GLIBCXX_3.4.1
GLIBCXX_3.4.2
GLIBCXX_3.4.3
GLIBCXX_3.4.4
GLIBCXX_3.4.5
GLIBCXX_3.4.6
GLIBCXX_3.4.7
GLIBCXX_3.4.8
GLIBCXX_3.4.9
GLIBCXX_3.4.10
GLIBCXX_3.4.11
GLIBCXX_3.4.12
GLIBCXX_3.4.13
GLIBCXX_3.4.14
GLIBCXX_3.4.15
GLIBCXX_3.4.16
GLIBCXX_3.4.17
GLIBCXX_3.4.18
GLIBCXX_3.4.19
GLIBCXX_3.4.20
GLIBCXX_DEBUG_MESSAGE_LENGTH
这个地方特别要注意坑特别多,一定要覆盖原来的。
pip install tensorflowonspark
这样就可以使用了
报错信息:
报错:ImportError: /lib64/libc.so.6: version `GLIBC_2.17' not found (required by /usr/local/lib/python2.7/site-packages/tensorflow/python/_pywrap_tensorflow.so)
tar zxvf glibc-2.17.tar.gz
mkdir build
cd build
../glibc-2.17/configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin
make -j4
make install
测试验证tensorflow
import tensorflow as tf
import numpy as np
x_data = np.float32(np.random.rand(2, 100))
y_data = np.dot([0.100, 0.200], x_data) + 0.300
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in xrange(0, 201):
sess.run(train)
if step % 20 == 0:
print step, sess.run(W), sess.run(b)
# 得到最佳拟合结果 W: [[0.100 0.200]], b: [0.300]确保etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_144/
export SCALA_HOME=/usr/local/scala-2.12.3/
export PATH=$PATH:/usr/local/scala-2.12.3/bin
export SPARK_HOME=/usr/local/spark-2.1.1-bin-hadoop2.7/
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cuda
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH下载地址:http://down.51cto.com/data/2338827
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



