еӨ§ж•°жҚ®еҲҶеёғејҸи®Ўз®—--hadoop
HadoopжҳҜдёҖдёӘз”ұApacheеҹәйҮ‘дјҡжүҖејҖеҸ‘зҡ„еҲҶеёғејҸзі»з»ҹеҹәзЎҖжһ¶жһ„гҖӮз”ЁжҲ·еҸҜд»ҘеңЁдёҚдәҶи§ЈеҲҶеёғејҸеә•еұӮз»ҶиҠӮзҡ„жғ…еҶөдёӢпјҢејҖеҸ‘еҲҶеёғејҸзЁӢеәҸгҖӮе……еҲҶеҲ©з”ЁйӣҶзҫӨзҡ„еЁҒеҠӣиҝӣиЎҢй«ҳйҖҹиҝҗз®—е’ҢеӯҳеӮЁгҖӮ
Hadoop ж ёеҝғйЎ№зӣ®жҸҗдҫӣдәҶеңЁдҪҺз«Ҝ硬件дёҠжһ„е»әдә‘и®Ўз®—зҺҜеўғзҡ„еҹәзЎҖжңҚеҠЎ,е®ғд№ҹжҸҗдҫӣдәҶиҝҗиЎҢеңЁиҝҷдёӘдә‘дёӯзҡ„иҪҜ件жүҖеҝ…йЎ»зҡ„ API жҺҘеҸЈгҖӮ
Hadoop еҶ…ж ёзҡ„дёӨдёӘеҹәжң¬йғЁеҲҶжҳҜ MapReduce жЎҶжһ¶,д№ҹе°ұжҳҜдә‘и®Ўз®—зҺҜеўғ,е’Ң HDFSеҲҶеёғејҸж–Ү件系з»ҹ гҖӮеңЁ Hadoop ж ёеҝғжЎҶжһ¶дёӯ,MapReduce еёёиў«з§°дёә mapred,HDFS з»Ҹеёёиў«з§°дёә dfsгҖӮгҖӮHDFSдёәжө·йҮҸзҡ„ж•°жҚ®жҸҗдҫӣдәҶеӯҳеӮЁпјҢMapReduceдёәжө·йҮҸзҡ„ж•°жҚ®жҸҗдҫӣдәҶи®Ўз®—гҖӮ
MapReduce зҡ„ж ёеҝғжҰӮеҝөжҳҜжҠҠиҫ“е…Ҙзҡ„ж•°жҚ®еҲҶжҲҗдёҚеҗҢзҡ„йҖ»иҫ‘еқ—, Map д»»еҠЎйҰ–е…Ҳ并иЎҢзҡ„еҜ№жҜҸдёҖеқ—иҝӣиЎҢеҚ•зӢ¬зҡ„еӨ„зҗҶгҖӮиҝҷдәӣйҖ»иҫ‘еқ—зҡ„еӨ„зҗҶз»“жһңдјҡиў«йҮҚж–°з»„еҗҲжҲҗдёҚеҗҢзҡ„жҺ’еәҸзҡ„йӣҶеҗҲ,иҝҷдәӣйӣҶеҗҲжңҖеҗҺз”ұ Reduce д»»еҠЎиҝӣиЎҢеӨ„зҗҶгҖӮ
HDFSеҲҶеёғејҸж–Ү件系з»ҹжңүй«ҳе®№й”ҷжҖ§зҡ„зү№зӮ№пјҢ并且и®ҫи®Ўз”ЁжқҘйғЁзҪІеңЁдҪҺе»үзҡ„пјҲlow-costпјү硬件дёҠпјӣиҖҢдё”е®ғжҸҗдҫӣй«ҳеҗһеҗҗйҮҸпјҲhigh throughputпјүжқҘи®ҝй—®еә”з”ЁзЁӢеәҸзҡ„ж•°жҚ®пјҢйҖӮеҗҲйӮЈдәӣжңүзқҖи¶…еӨ§ж•°жҚ®йӣҶпјҲlarge data setпјүзҡ„еә”з”ЁзЁӢеәҸгҖӮHDFSж”ҫпјҲrelaxпјүPOSIXзҡ„иҰҒжұӮпјҢеҸҜд»Ҙд»ҘжөҒзҡ„еҪўејҸи®ҝй—®пјҲstreaming accessпјүж–Ү件系з»ҹдёӯзҡ„ж•°жҚ®гҖӮ
еҸӮиҖғпјҡhadoop.appache.org
е®һйӘҢзҺҜеўғrhel6.5
дё»жңәserver7пјҢд»Һжңәserver8.server9 жіЁпјҡеҗ„жңәйғҪеҝ…йЎ»еҹҹеҗҚзӣёдә’и§ЈжһҗгҖӮ
е®үиЈ…еҸҠеҹәжң¬й…ҚзҪ®
еҗ„жңәеҲӣе»әuidдёә900 зҡ„hadoopз”ЁжҲ·пјҢеҜҶз Ғдёәredhat
Server7дёҠ,hadoopз”ЁжҲ·еңЁ/home/дёӢгҖӮ
#tar zxf hadoop-1.2.1.tar.gz -C hadoop
#cd hadoop
#ln -s hadoop-1.2.1/ hadoop
#sh jdk-6u32-linux-x64.bin //е®үиЈ…java
#ln -s jdk-1.6.32 java
#vim .bash_profile //й…ҚзҪ®path
export JAVA_HOME=/home/hadoop/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
#source .bash_profile
#echo $JAVA_HOME
жҳҫзӨә/home/hadoop/java
#cd hadoop/conf
#vim hadoop-env.sh
дҝ®ж”№exprot JAVA_HOME=/home/hadoop/java
#mkdir ../input
#cp *.xml ../input //еҲӣе»әеҲҶеёғејҸж–Ү件系з»ҹ
#cd ..
#bin/hadoop jar hadoop-examples-1.2.1.jar

еҲ—еҮәдәҶhadoop-example-1.2.1jarеҜ№inputж“ҚдҪңзҡ„зӣёе…іеҸӮж•°пјҢеҰӮgrepжҹҘжүҫпјҢsortжҺ’еәҸпјҢwordcountи®Ўж•°зӯүгҖӮ
#bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+' //жҹҘжүҫinoutдёӯж–Ү件еҗҚејҖеӨҙдёәdfsеҗҺйқўдёәе°ҸеҶҷиӢұж–Үзҡ„ж–Ү件пјҢе°Ҷз»“жһңеӯҳе…ҘиҮӘеҠЁз”ҹжҲҗзҡ„outputж–Ү件еӨ№дёӯ
#cd output/
#ls
#cat *
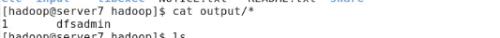
еҶҚд»Ӣз»ҚдёӢhadoopзҡ„дёүз§Қе·ҘдҪңжЁЎејҸ
еҚ•жңәжЁЎејҸпјҲstandaloneпјү
еҚ•жңәжЁЎејҸжҳҜHadoopзҡ„й»ҳи®ӨжЁЎејҸпјҢеҪ“йҰ–ж¬Ўи§ЈеҺӢHadoopзҡ„жәҗз ҒеҢ…ж—¶пјҢHadoopж— жі•дәҶ解硬件е®үиЈ…зҺҜеўғпјҢдҫҝдҝқе®Ҳең°йҖүжӢ©дәҶжңҖе°Ҹй…ҚзҪ®гҖӮеңЁиҝҷз§Қй»ҳи®ӨжЁЎејҸдёӢжүҖжңү3дёӘXMLж–Ү件еқҮдёәз©әгҖӮеҪ“й…ҚзҪ®ж–Ү件дёәз©әж—¶пјҢHadoopдјҡе®Ңе…ЁиҝҗиЎҢеңЁжң¬ең°гҖӮеӣ дёәдёҚйңҖиҰҒдёҺе…¶д»–иҠӮзӮ№дәӨдә’пјҢеҚ•жңәжЁЎејҸе°ұдёҚдҪҝз”ЁHDFSпјҢд№ҹдёҚеҠ иҪҪд»»дҪ•Hadoopзҡ„е®ҲжҠӨиҝӣзЁӢгҖӮиҜҘжЁЎејҸдё»иҰҒз”ЁдәҺејҖеҸ‘и°ғиҜ•MapReduceзЁӢеәҸзҡ„еә”з”ЁйҖ»иҫ‘гҖӮ
дјӘеҲҶеёғжЁЎејҸпјҲPseudo-Distributed Modeпјү
дјӘеҲҶеёғжЁЎејҸеңЁвҖңеҚ•иҠӮзӮ№йӣҶзҫӨвҖқдёҠиҝҗиЎҢHadoopпјҢе…¶дёӯжүҖжңүзҡ„е®ҲжҠӨиҝӣзЁӢйғҪиҝҗиЎҢеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠгҖӮиҜҘжЁЎејҸеңЁеҚ•жңәжЁЎејҸд№ӢдёҠеўһеҠ дәҶд»Јз Ғи°ғиҜ•еҠҹиғҪпјҢе…Ғи®ёдҪ жЈҖжҹҘеҶ…еӯҳдҪҝз”Ёжғ…еҶөпјҢHDFSиҫ“е…Ҙиҫ“еҮәпјҢд»ҘеҸҠе…¶д»–зҡ„е®ҲжҠӨиҝӣзЁӢдәӨдә’гҖӮ
е®Ңе…ЁеҲҶеёғејҸжЁЎејҸ
Hadoopе®ҲжҠӨиҝӣзЁӢиҝҗиЎҢеңЁдёҖдёӘйӣҶзҫӨдёҠгҖӮ
дёҠйқўзҡ„ж“ҚдҪңдёәеҚ•жңәжЁЎејҸгҖӮ
HadoopеҲҶеёғејҸйғЁзҪІ
з»“жһ„пјҡ
дё»иҠӮзӮ№еҢ…жӢ¬еҗҚз§°иҠӮзӮ№пјҲnamenode)гҖҒд»ҺеұһеҗҚз§°иҠӮзӮ№(secondarynamenode)е’Ң jobtracker е®ҲжҠӨиҝӣзЁӢ(еҚіжүҖи°“зҡ„дё»е®ҲжҠӨиҝӣзЁӢ)д»ҘеҸҠз®ЎзҗҶйӣҶзҫӨжүҖз”Ёзҡ„е®һз”ЁзЁӢеәҸе’ҢжөҸи§ҲеҷЁгҖӮ
д»ҺиҠӮзӮ№еҢ…жӢ¬ tasktracker е’Ңж•°жҚ®иҠӮзӮ№(д»Һеұһе®ҲжҠӨиҝӣзЁӢ)гҖӮдёӨз§Қи®ҫзҪ®зҡ„дёҚеҗҢд№ӢеӨ„еңЁдәҺ,дё»иҠӮзӮ№еҢ…жӢ¬жҸҗдҫӣ Hadoop йӣҶзҫӨз®ЎзҗҶе’ҢеҚҸи°ғзҡ„е®ҲжҠӨиҝӣзЁӢ,иҖҢд»ҺиҠӮзӮ№еҢ…жӢ¬е®һзҺ°Hadoop ж–Ү件系з»ҹ(HDFS )еӯҳеӮЁеҠҹиғҪе’Ң MapReduce еҠҹиғҪ(ж•°жҚ®еӨ„зҗҶеҠҹиғҪ)зҡ„е®ҲжҠӨиҝӣзЁӢгҖӮ
жҜҸдёӘе®ҲжҠӨиҝӣзЁӢеңЁ Hadoop жЎҶжһ¶дёӯзҡ„дҪңз”Ёпјҡ
namenode жҳҜ Hadoop дёӯзҡ„дё»жңҚеҠЎеҷЁ,е®ғз®ЎзҗҶж–Ү件系з»ҹеҗҚз§°з©әй—ҙе’ҢеҜ№йӣҶзҫӨдёӯеӯҳеӮЁзҡ„ж–Ү件зҡ„и®ҝй—®гҖӮ
secondary namenode ,е®ғдёҚжҳҜnamenode зҡ„еҶ—дҪҷе®ҲжҠӨиҝӣзЁӢ,иҖҢжҳҜжҸҗдҫӣе‘ЁжңҹжЈҖжҹҘзӮ№е’Ңжё…зҗҶд»»еҠЎгҖӮ
еңЁжҜҸдёӘ Hadoop йӣҶзҫӨдёӯеҸҜд»ҘжүҫеҲ°дёҖдёӘ namenode е’ҢдёҖдёӘ secondary namenodeгҖӮ
datanode з®ЎзҗҶиҝһжҺҘеҲ°иҠӮзӮ№зҡ„еӯҳеӮЁ(дёҖдёӘйӣҶзҫӨдёӯеҸҜд»ҘжңүеӨҡдёӘиҠӮзӮ№)гҖӮжҜҸдёӘеӯҳеӮЁж•°жҚ®зҡ„иҠӮзӮ№иҝҗиЎҢдёҖдёӘ datanode е®ҲжҠӨиҝӣзЁӢгҖӮ
жҜҸдёӘйӣҶзҫӨжңүдёҖдёӘ jobtracker ,е®ғиҙҹиҙЈи°ғеәҰ datanode дёҠзҡ„е·ҘдҪңгҖӮ
жҜҸдёӘ datanode жңүдёҖдёӘtasktracker,е®ғ们жү§иЎҢе®һйҷ…е·ҘдҪңгҖӮ
jobtracker е’Ң tasktracker йҮҮз”Ёдё»-д»ҺеҪўејҸ,jobtracker и°ғеәҰdatanode еҲҶеҸ‘е·ҘдҪң,иҖҢ tasktracker жү§иЎҢд»»еҠЎгҖӮjobtracker иҝҳжЈҖжҹҘиҜ·жұӮзҡ„е·ҘдҪң,еҰӮжһңдёҖдёӘdatanode з”ұдәҺжҹҗз§ҚеҺҹеӣ еӨұиҙҘ,jobtracker дјҡйҮҚж–°и°ғеәҰд»ҘеүҚзҡ„д»»еҠЎгҖӮ
дёӢйқўе®һзҺ°дјӘеҲҶеёғејҸ
дёәдәҶж–№дҫҝпјҢиҝӣиЎҢsshе…ҚеҜҶз Ғи®ҫзҪ®гҖӮ
Server7дёҠhadoopз”ЁжҲ·гҖӮ
#ssh-keygen
#ssh-copy-id localhost
#ssh localhost //е…ҚеҜҶз Ғзҷ»йҷҶжң¬жңә
дҝ®ж”№й…ҚзҪ®ж–Ү件пјҡ
#cd hadoop/conf
#vim core-site.xml
еңЁ<configuration>дёӢйқўж·»еҠ
<property>
<name>fs.default.name</name>
<value>hdfs://172.25.0.7:9000</value>
</property> //жҢҮе®ҡnamenode
#vim mapred-site.xml
еңЁ<configuration>дёӢйқўж·»еҠ
<property>
<name>mapred.job.tracker</name>
<value>172.25.0.7:9001</value>
</property> //жҢҮе®ҡ jobtracker
#vim hdfs-site.xml
еңЁ<configuration>дёӢйқўж·»еҠ
<property>
<name>dfs.replication</name>
<value>1</value>
</property> //жҢҮе®ҡж–Ү件дҝқеӯҳзҡ„еүҜжң¬ж•°пјҢз”ұдәҺжҳҜдјӘеҲҶеёғејҸжүҖд»ҘеүҜжң¬е°ұжҳҜжң¬жңә1дёӘгҖӮ
#cd ..
#bin/hadoop namenode -format //ж јејҸеҢ–namenode
#bin/start-dfs.sh //еҗҜеҠЁhdfs
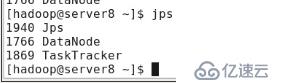
#jps //жҹҘзңӢиҝӣзЁӢ
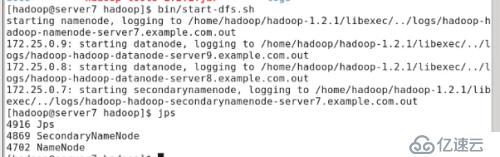
еҸҜзңӢеҲ°secondarynamenodeпјҢnamenode,datanodeйғҪд»ҘеҗҜеҠЁгҖӮNamenodeдёҺdatanodeеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠпјҢжүҖд»ҘжҳҜдјӘеҲҶеёғејҸгҖӮ
#bin/start-mapred.sh.sh //еҗҜеҠЁmapreduce
#bin/hadoop fs -put input test //дёҠдј inputеҲ°hdfs并еңЁhdfsдёӯжӣҙеҗҚдёәtest
жөҸи§Ҳ NameNode е’Ң JobTracker зҡ„зҪ‘з»ңжҺҘеҸЈ,е®ғ们зҡ„ең°еқҖй»ҳи®Өдёә:
NameNode вҖ“ http://172.25.0.7:50070/
JobTracker вҖ“ http://172.25.0.7:50030/
жҹҘзңӢnamenode
#bin/hadoop fs -ls test //еҲ—еҮәhdfsдёӯtestзӣ®еҪ•дёӢзҡ„ж–Ү件
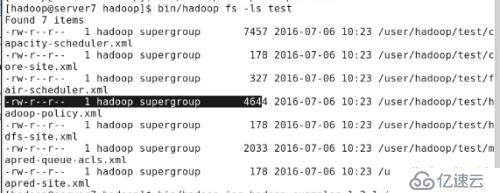
WebдёҠжҹҘзңӢtestдёӢзҡ„ж–Ү件
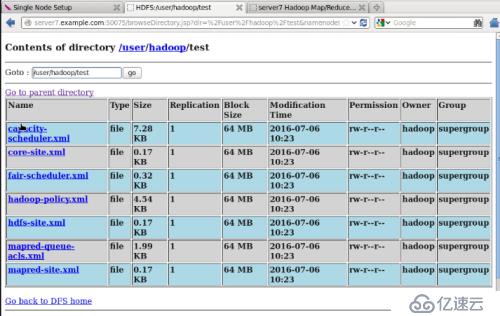
дёӢйқўе®һзҺ°е®Ңе…ЁеҲҶеёғејҸжЁЎејҸ
дё»д»ҺжңәдёҠйғҪе®үиЈ…nfs-utils并еҗҜеҠЁrpcbindжңҚеҠЎпјҲдё»иҰҒжҳҜеңЁnfsе…ұдә«ж—¶еҖҷиҙҹиҙЈйҖҡзҹҘе®ўжҲ·з«ҜпјҢжңҚеҠЎеҷЁзҡ„nfsз«ҜеҸЈеҸ·зҡ„гҖӮз®ҖеҚ•зҗҶи§Јrpcе°ұжҳҜдёҖдёӘдёӯд»ӢжңҚеҠЎпјүпјҢд»ҺжңәйҖҡиҝҮnfsзӣҙжҺҘдҪҝз”Ёhadoopе…ҚеҺ»е®үиЈ…й…ҚзҪ®гҖӮ
еңЁserver7дёҠпјҢеҗҜеҠЁnfsжңҚеҠЎ
#vim /etc/exports
/home/hadoop *(rw,all_squash,anonuid=900,anongid=900
//е…ұдә«hadoopпјҢеҜ№зҷ»йҷҶз”ЁжҲ·жҢҮе®ҡidпјҢз”ЁжҲ·д»Ҙuidдёә900зҡ„з”ЁжҲ·зҷ»йҷҶ
server8пјҢ9дёҠ
#mount 172.25.0.7:/home/hadoop /hooem/hadoop/ //жҢӮиҪҪе…ұдә«зӣ®еҪ•
server7дёҠпјҢhadoopз”ЁжҲ·пјҢжӣҙж”№hadoop/confдёӢзҡ„hdfs-siteпјҢе°ҶеүҜжң¬ж•°з”ұ1ж”№дёә2гҖӮ
#cd hadoop/conf
#vim slave ж·»еҠ д»Һжңә
172.25.0.8
172.25.0.9
#vim master и®ҫзҪ®дё»жңә
172.25.0.7
еҗҜеҠЁе®Ңе…ЁеҲҶеёғејҸжЁЎејҸеүҚиҰҒж јејҸеҢ–дјӘеҲҶеёғејҸж–Ү件系з»ҹ
#cd ..
#bin/stop-all.sh //еҒңжӯўjobtracker,namenode,secondarynamenode
#bin/hadoop-daemon.sh stop tasktracker
#bin/hadoop-daemon.sh stop datanode //еҒңжӯўtasktrackerпјҢdatanodeпјҢ
#bin/hadoop namenode -format
#bin/start-dfs.sh жҳҫзӨәserver8пјҢserver9иҝһжҺҘгҖӮ
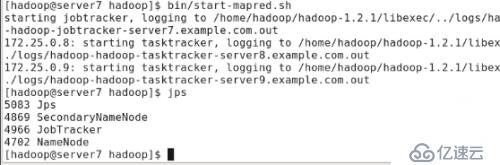
#bin/start-mapred.sh
ж–°еўһдәҶjobtrackerиҝӣзЁӢ
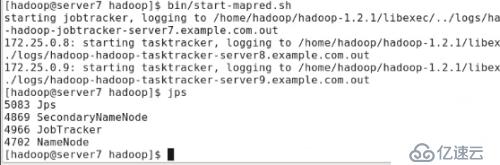
server8дёҠпјҢjpsеҸҜзңӢеҲ°дёүдёӘиҝӣзЁӢjpsпјҢdatanode,tasktracker
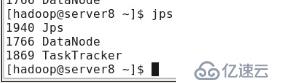
д»ҺжңәеҸҜд»ҘдёҠдј пјҢжҹҘиҜўзӯү
#bin/hadoop fs -put input test
#bin/hadoop jar hadoop-example-1.2.1.jar grep test out вҖҳdfs[a-z]+вҖҷ
server7дёҠпјҢ
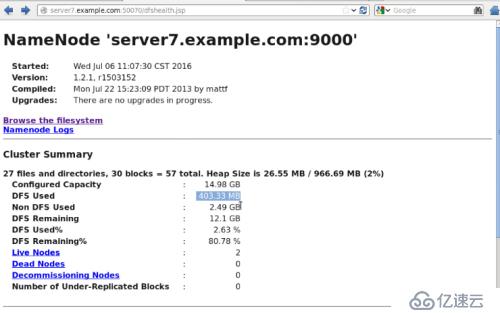
#bin/hadoop dfsadmin -report //жҳҫзӨәhdfsдҝЎжҒҜ
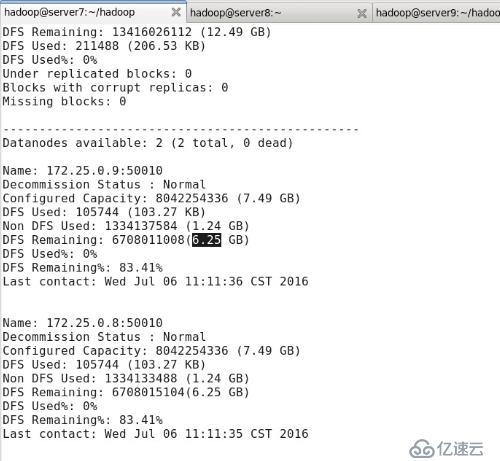
з”ұдәҺhadoopдёӢжңӘеўһеҠ ж–Ү件пјҢжүҖд»Ҙdfs used%еқҮдёә0%
#dd if=/dev/zero of=bigfile bs=1M count=200
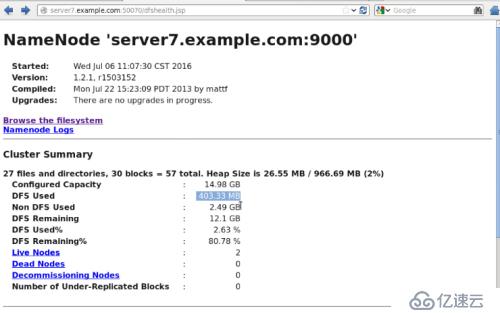
#bin/hadoop fs -put bigfile test
еңЁwebдёҠзңӢеҲ°dfs usedдёә403.33MBпјҲдёӨд»ҺжңәпјҢжҜҸдёӘдёә200MBпјү
жіЁпјҡжңүж—¶еҖҷж“ҚдҪңй”ҷиҜҜеҜјиҮҙhadoopиҝӣе…Ҙе®үе…ЁжЁЎејҸпјҢж— жі•иҝӣиЎҢдёҠдј зӯүж“ҚдҪң

еҸӘйңҖиҝҗиЎҢдёӢиЎҢжҢҮд»ӨеҚіеҸҜ
#bin/hadoop dfsadmin -safemode leave

hadoopж”ҜжҢҒе®һж—¶жү©еұ•пјҢеҸҜеңЁзәҝж·»еҠ д»ҺжңәгҖӮ
ж–°еўһд»Һжңәserver10гҖӮе®үиЈ…nfs-utils,еҗҜеҠЁrpcbindжңҚеҠЎгҖӮж·»еҠ uid900зҡ„hadoopз”ЁжҲ·пјҢжҢӮиҪҪserver7зҡ„hadoop并еңЁhadoop/confдёӢзҡ„slavesж·»еҠ 172.25.0.10гҖӮ
жіЁпјҡеҝ…йЎ»еңЁж·»еҠ server10д№ӢеүҚеңЁдё»д»ҺжңәдёҠж·»еҠ server10зҡ„hostnameи§ЈжһҗгҖӮ
server10дёҠпјҢhadoopз”ЁжҲ·
#bin/hadoop-daemon.sh start datanode
#bin/hadoop-daemon.sh start tasktracker
server7дёҠпјҢ
#bin/hadoop dfsadmin -report
еҸҜзңӢеҲ°server10зҡ„дҝЎжҒҜ
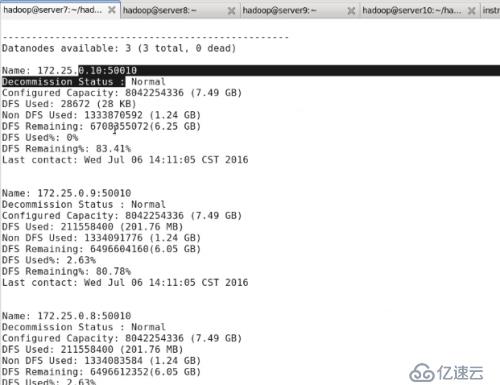
еҸҜзңӢеҲ°server10 dfs usedдёә0пјҢеҸҜд»Ҙе°Ҷserver9зҡ„ж•°жҚ®з§»еҲ°server10дёӯгҖӮ
ж•°жҚ®иҝҒ移пјҡ
ж•°жҚ®иҝҒ移жҳҜе°ҶеҫҲе°‘дҪҝз”ЁжҲ–дёҚз”Ёзҡ„ж–Ү件移еҲ°иҫ…еҠ©еӯҳеӮЁзі»з»ҹзҡ„иҝҮзЁӢгҖӮ
hadoop еңЁзәҝеҲ йҷӨ server9 datanode иҠӮзӮ№еҸҜе®һзҺ°ж•°жҚ®иҝҒ移:
#bin/hadoop-daemon.sh stop tasktracker //еңЁеҒҡж•°жҚ®иҝҒ移时,жӯӨиҠӮзӮ№дёҚиҰҒеҸӮдёҺ tasktracker,еҗҰеҲҷдјҡеҮәзҺ°ејӮеёё
еңЁ master дёҠдҝ®ж”№ conf/mapred-site.xml
еңЁ</property>дёӢйқўж·»еҠ
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/datanode-excludes</value>
</property>
еңЁconfдёӢеҲӣе»әdatanode-excludesпјҢж·»еҠ йңҖиҰҒеҲ йҷӨзҡ„дё»жңә,дёҖиЎҢдёҖдёӘ
#vim datanode-excludes
172.25.0.9 //еҲ йҷӨиҠӮзӮ№server9
#cd ..
#bin/hadoop dfsadmin -refreshNodes //еңЁзәҝеҲ·ж–°иҠӮзӮ№
#bin/hadoop dfsadmin -report
еҸҜзңӢеҲ°server9 зҠ¶жҖҒпјҡDecommission in progressпјҢ
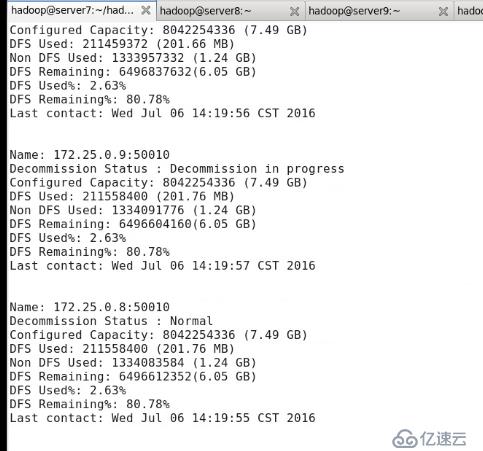
иӢҘиҰҒеңЁзәҝеҲ йҷӨtasktrackerиҠӮзӮ№
еңЁserver7дёҠдҝ®ж”№ conf/mapred-site.xml
<property>
<name>mapred.hosts.exclude</name>
<value>/home/hadoop/hadoop-1.0.4/conf/tasktracker-excludes</value></property>
еҲӣе»ә tasktracker-excludes ж–Ү件,并添еҠ йңҖиҰҒеҲ йҷӨзҡ„дё»жңәеҗҚ,дёҖиЎҢдёҖдёӘ
server9.example.com
#bin/hadoop mradmin -refreshNodes
зӯүжӯӨиҠӮзӮ№зҡ„зҠ¶жҖҒжҳҫзӨәдёә Decommissioned,ж•°жҚ®иҝҒ移е®ҢжҲҗпјҢеҸҜд»Ҙе®үе…Ёе…ій—ӯдәҶгҖӮ
hadoop1.2.1зүҲжң¬иҝҮдҪҺпјҢjobtrackerзҡ„и°ғеәҰиғҪеҠӣдёҚејәпјҢеҪ“slversиҝҮеӨҡж—¶е®№жҳ“жҲҗдёә瓶йўҲгҖӮдҪҝз”Ёж–°зүҲжң¬2.6.4жҳҜдёӘдёҚй”ҷзҡ„йҖүжӢ©гҖӮ
еҒңжҺүиҝӣзЁӢпјҢеҲ йҷӨж–Ү件пјҡ
server7дёҠ
#bin/stop-all.sh
#cd /home/hadoop
#rm -fr hadoop java hadoop-1.2.1 java1.6.32
#rm -fr /tmp/*
д»ҺжңәдёҠ
#bin/hadoop-daemon.sh stop datanode
#bin/hadoop-daemon.sh stop tasktracker
#rm -fr /tmp/*
дёӢйқўж“ҚдҪңдёҺдёҠйқўеҹәжң¬зӣёеҗҢ
server7дёҠпјҢ/home/hadoop/дёӢhadoopз”ЁжҲ·
#tar zxf jdk-7u79-linux-x64.tar.gz -C /home/hadoop/
#ln -s jdk1.7.0.79 java
#tar zxf hadoop-2.6.4.tar.gz
#ln -s hadoop-2.6.4 hadoop
#cd hadoop/etc/hadoop
#vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java
export HADOOP_PREFIX=/home/hadoop/hadoop
#cd /home/hadoop/hadoop
#mkdir input
#cp etc/hadoop/*.xml input
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output вҖҳdfs[a-z.]+вҖҷ
#cat output/*
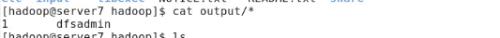
grepзј–иҜ‘ж—¶дјҡжңүwarningпјҢеҪ“йӣҶзҫӨеӨ§ж—¶еҸҜиғҪдјҡеҮәзҺ°й—®йўҳгҖӮйңҖиҰҒж·»еҠ hadoop-nativeгҖӮ
#tar -xf hadoop-native-64.2.6.0.tar -C hadoop/lib/native/
#bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output вҖҳdfs[a-z.]+вҖҷ
еҶҚзј–иҜ‘жІЎжңүwarning
#cd etc/hadoop
#vim slaves
172.25.0.8
172.25.0.9
#vim etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.0.7:9000</value>
</property>
#vim hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
#bin/hdfs namenode -format
#sbin/start-dfs.sh
#jps

#ps -ax еҸҜзңӢеҲ°namenodeдёҺsecondarynamenodeиҝӣзЁӢ
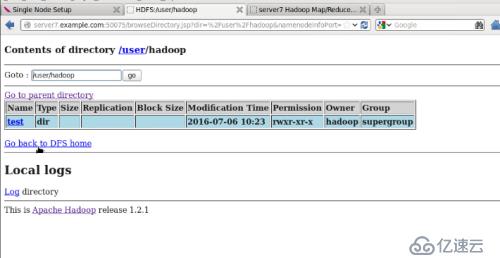
#bin/hdfs dfs -mkdir /user/hadoop
#bin/hdfs dfs -put input/ test
webдёҠеҸҜзңӢеҲ°inputд»ҘдёҠдј гҖӮ
MapReduce зҡ„ JobTracker/TaskTracker жңәеҲ¶йңҖиҰҒеӨ§и§„жЁЎзҡ„и°ғж•ҙжқҘдҝ®еӨҚе®ғеңЁеҸҜжү©еұ•жҖ§пјҢеҶ…еӯҳж¶ҲиҖ—пјҢзәҝзЁӢжЁЎеһӢпјҢеҸҜйқ жҖ§е’ҢжҖ§иғҪдёҠзҡ„зјәйҷ·
дёәд»Һж №жң¬дёҠи§ЈеҶіж—§ MapReduce жЎҶжһ¶зҡ„жҖ§иғҪ瓶йўҲпјҢдҝғиҝӣ Hadoop жЎҶжһ¶зҡ„жӣҙй•ҝиҝңеҸ‘еұ•пјҢд»Һ 0.23.0 зүҲжң¬ејҖе§ӢпјҢHadoop зҡ„ MapReduce жЎҶжһ¶е®Ңе…ЁйҮҚжһ„пјҢеҸ‘з”ҹдәҶж №жң¬зҡ„еҸҳеҢ–гҖӮж–°зҡ„ Hadoop MapReduce жЎҶжһ¶е‘ҪеҗҚдёә MapReduceV2 жҲ–иҖ…еҸ« Yarn
#vim etc/hadoop/yarn-site.xml
< property>
<name>yarn.resourcemanager.hostname</name>
<value>server7.example.com</value>
</property>
#sbin/start-yarn.sh
#jps
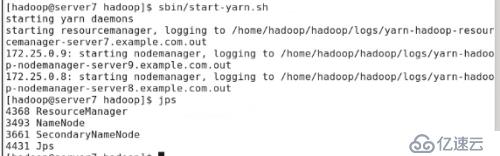
server8еҸҜзңӢеҲ°иҝӣзЁӢе·ІеҗҜеҠЁ