这篇文章主要介绍“PageHelper引发的幽灵数据问题怎么解决”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“PageHelper引发的幽灵数据问题怎么解决”文章能帮助大家解决问题。
首先我们看了下这对代码的业务逻辑,非常的简单,总共没有几行代码,也没有分页逻辑,代码如下:
public List<SdSubscription> findAll() {
return sdSubscriptionMapper.selectAll();
}那么究竟是咋回事呢?讲道理不可能出现这种情况的啊,不要慌,我们加点日志,将日志级别调整为DEBUG,让日志飞一段时间。
public List<SdSubscription> findAll() {
log.info("find the sub start .....");
List<SdSubscription> subs = sdSubscriptionMapper.selectAll();
log.info("find the sub end .....");
return subs;
}果不其然,日志中出现了奇奇怪怪的分页参数,如下图所示:

果然是PageHelper这个开源框架搞的鬼,我想大家都用过吧,分页非常方便,那么究竟为什么别人都没问题,单单就我会出现问题呢?
为了回答上面的疑问,我们先看看PageHelper框架的工作原理吧。
PageHelper 是一个开源的 MyBatis 分页插件,它可以帮助开发者在查询数据时,快速的实现分页功能。
PageHelper 的工作原理可以简单概括为以下几个步骤:
在需要进行分页的查询方法前,调用 PageHelper 的静态方法 startPage(),设置当前页码和每页显示的记录数。它会将分页信息放到线程的ThreadLocal中,那么在线程的任何地方都可以访问了。
当查询方法执行时,PageHelper 会自动拦截查询语句,如果发现线程的ThreadLocal中有分页信息,那么就会在其前后添加分页语句,例如 MySQL 中的 LIMIT 语句。
查询结果将被包装在 Page 对象中返回,该对象包含分页信息和查询结果列表。
在查询方法执行完毕后,会在finally中清除线程ThreadLocal中的分页信息,避免分页设置对其他查询方法的影响。
PageHelper 的实现原理主要依赖于拦截器技术和反射机制,通过拦截查询语句并动态生成分页语句,实现了简单、高效、通用的分页功能。具体源码在下图的类中,非常容易看懂。
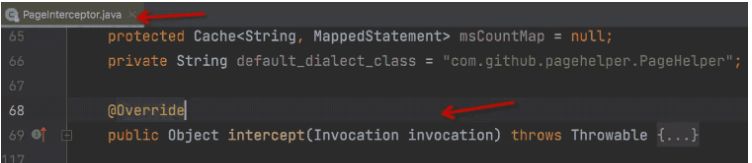
明白了PageHelper的工作原理后,反复检查代码,都没有调用过startPage,debug查看ThreadLocal中也没有分页信息啊,懵逼中。那我看看别人写的添加分页参数的代码吧,不看不知道,一看吓一跳。
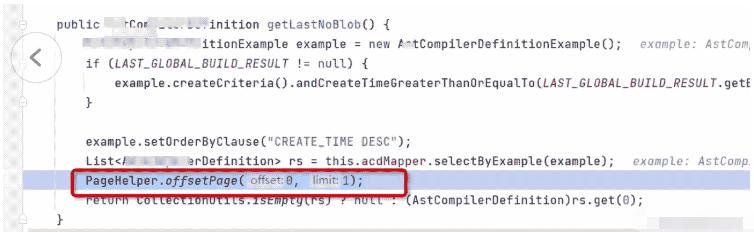
原来有位“可爱”的同事竟然在查询后,加了一个分页,就是把分页信息放到线程的ThreadLocal中。
那大家是不是有疑问,丁是丁,矛是矛,你的线程关我何事?这就要说到我们的tomcat了。
其实这就涉及到我们的tomcat相关知识了,我们一个浏览器发一个接口请求,经过我们的tomcat的,究竟是一个什么样的流程呢?
客户端发送HTTP请求到Tomcat服务器。
Tomcat的HTTP连接器(Connector)接收到请求,将连接请求交给线程池Executor处理,解析它,然后将请求转发给对应的Web应用程序。
Tomcat的Web应用程序容器(Container)接收到请求,根据请求的URL找到对应的Servlet。
关于tomcat中使用线程池提交浏览器的连接请求的源码如下:
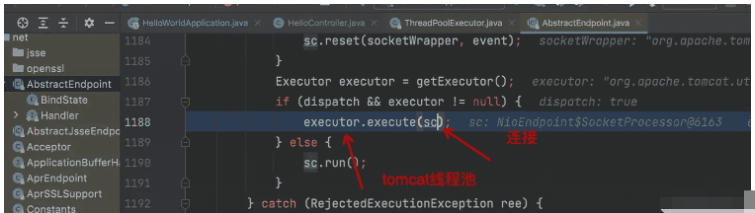
从而得知,你的连接请求是从线程池从拿的,而拿到的这个线程恰好是一个“脏线程”,在ThreadLocal中放了分页信息,导致你这边出现问题。
关于“PageHelper引发的幽灵数据问题怎么解决”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://juejin.cn/post/7223590232730370108



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



